







EM算法其实是最大似然估计的拓展,是为了解决最大似然估计无法解决的参数估计,最大似然估计通过简单的求导可以得到简单模型的参数,但是对于复杂的混合模型,含有隐含数据的情况下就力不从心了。例如,单高斯模型(GSM)可以通过最大似然估计进行参数估计,但是我们随后会学习混合高斯模型(GMM),是有好多个单高斯模型混合所得,就要使用EM算法进行参数估计,样本到底属于哪一个单高斯模型就是所谓的隐含数据, 现在以经典的身高问题说明下:
现在国家卫计委对幼儿身高进行统计,男孩500个,女孩500个。我们假定男孩的身高服从正态分布 ,女孩的身高则服从另一个正态分布:
,女孩的身高则服从另一个正态分布:  。这时候我们可以用最大似然法(MLE),在我们明确样本是男孩还是女孩的情况下可以通过最大似然估计分别得到两个正态分布的参数。
。这时候我们可以用最大似然法(MLE),在我们明确样本是男孩还是女孩的情况下可以通过最大似然估计分别得到两个正态分布的参数。
但现在我们让情况复杂一点,就是这500个男孩和500个女孩混在一起了。我们拥有1000个人的身高数据,却不知道这1000个人每一个是男孩的还是女孩的,而男孩,女孩就是所谓的隐含数据。,
那么问题来了,我们只有知道了精确的男女身高的正态分布参数我们才能知道每一个人更有可能是男孩还是女孩。但从另一方面去考量,我们只有知道了每个人是男孩还是女孩才能尽可能准确地估计男女各自身高的正态分布的参数。
解决问题的思路就是我们要先假设一下两个模型的参数(初始值),然后根据一定的准则判断每一个样本是来自男孩还是女孩,然后根据标注的样本在反过来重新估计这些参数,之后再多次重复这个过程,直至稳定。这个算法也就是EM算法。
(1)初始化参数:先初始化男孩身高的正态分布的参数:如均值=1.7,方差=0.1
(2)计算每一个人更可能属于男孩分布或者女孩分布;
(3)通过分为男孩的n个人来重新估计男生身高分布的参数(最大似然估计),女孩分布也按照相同的方式估计出来,更新分布。
(4)这时候两个分布的概率也变了,然后重复步骤(1)至(3),直到参数不发生变化为止
算法准备:
凸函数:
设是定义在实数域上的函数,如果对于任意的实数
,都有
那么是凸函数。若
不是单个实数,而是由实数组成的向量,此时,如果函数
的Hesse矩阵
是半正定的,即
那么是凸函数。特别地,如果
或者
,那么称
为严格凸函数。
Jensen不等式:
如果函数是凸函数,
是随机变量,那么
特别地,如果函数是严格凸函数,那么
当且仅当
即随机变量是常量。

(图片来自参考文章1)
注:若函数是凹函数,上述的符号相反。
数学期望:
随机变量的期望:
设离散型随机变量的概率分布为:
其中,,如果
绝对收敛,则称
为
的数学期望,记为
,即:
若连续型随机变量的概率密度函数为
,则数学期望为:
随机变量函数的数学期望:
设是随机变量
的函数,即
,若
是离散型随机变量,概率分布为:
则:
若是连续型随机变量,概率密度函数为
,则
算法推导过程:
已知:样本集X={x(1),…,x(m))},包含m个独立的样本;
未知:每个样本i对应的类别z(i)是未知的(相当于聚类);
输出:我们需要估计概率模型p(x,z)的参数θ;
目标:找到适合的θ和z让L(θ)最大。

(1)到(2)比较直接,就是分子分母同乘以一个相等的函数。(2)到(3)利用了Jensen不等式,考虑到![]() 是凹函数(二阶导数小于0),而且
是凹函数(二阶导数小于0),而且

就是![]() 的期望;
的期望;
再根据凹函数时的Jensen不等式:

可以得到(3)。
这个过程可以看作是对L(θ)求了下界。对于问题:
什么时候下界J(z,Q)与L(θ)在此点θ处相等?

根据Jensen不等式,自变量X是常数,等式成立。即:

由于 ,则可以得到:分子的和等于c
,则可以得到:分子的和等于c

在固定参数θ后,使下界拉升的Q(z)的计算公式,解决了Q(z)如何选择的问题。这一步就是E步,建立L(θ)的下界。接下来的M步,就是在给定Q(z)后,调整θ,去极大化L(θ)的下界J。
算法流程:
1)初始化分布参数θ; 重复以下步骤直到收敛:
E(求期望)步骤:根据参数初始值或上一次迭代的模型参数来计算出隐性变量的后验概率,其实就是隐性变量的期望。作为隐藏变量的现估计值:

M(最大化)步骤:将似然函数最大化以获得新的参数值:

算法缺陷:
传统的EM算法对初始值敏感,聚类结果随不同的初始值而波动较大。总的来说,EM算法收敛的优劣很大程度上取决于其初始参数。
推荐一篇详细推导的文章:http://www.cnblogs.com/jerrylead/archive/2011/04/06/2006936.html
















 1192
1192

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












{kind=link}
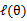{kind=link}
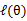{kind=link}
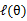{kind=link}