







前言
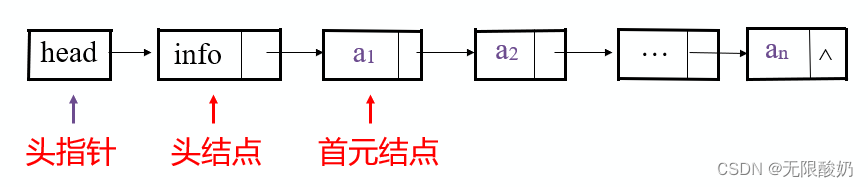
首先我们要知道什么是链表的头节点和头指针,两者有什么区别,弄清这一点我们才能更好的理解带头指针和不带头节点有什么优势和劣势。
头指针
什么是头指针?
- 头指针是指向链表中第一个有效节点的指针。
- 它通常是链表的起始点,用于访问链表的第一个元素。
头结点
什么是头节点?
- 头结点是链表中的第一个节点,但它不存储实际数据,仅用于辅助管理链表。
首元节点
什么是首元节点?
- 首元结点是链表中存储实际数据的第一个节点。
- 通常,头结点之后的节点是首元结点,但在某些链表中,首元结点也可能是头结点本身。
既然有头指针就可以找到首元节点,那么我们还要头节点干什么呢?
这说明,加上头节点一定存在一定的优势。
那么,优势是什么?
带头结点链表的优势
首先,带头节点的一个优势就是:在链表的第一个位置插入删除操作更加方便
下面我会详细解释一下这一点。假如我们有一个不带头节点的链表:
1->2->3->NULL
我们想要在第一位置插入一个元素4,我们应该怎么做呢?
//我们先为元素4分配一个空间
Node* newNode = new Node(4);
newNode->next = head; // 将新节点的next指向原头节点
head = newNode; // 更新头指针,使其指向新节点
这样我们就完成了对元素4的插入操作。通过观察我们可以发现,当你插入这个新结点之后,你还需要每次对头指针进行更新,造成这样的原因是因为首元节点没有前驱节点。
接下来我们对比一下,在含头节点的链表中插入元素4有什么不同。
带头节点的链表:
(head)->1->2->3->NULL
在带头节点的链表中,插入第一个节点与插入其他节点的方式完全相同。
Node* newNode = new Node(4);
newNode->next = head->next; // 将新节点的next指向原第一个节点
head->next = newNode; // 将头节点的next指向新节点
在这种情况下,我们无需要特殊处理头指针的更新,因为头节点始终存在且不会改变,我们只需要像对待其他节点一样操作。
带头节点的另一个优势是:可以避免对链表为空的判断
假如我们有一个不带头节点链表,我们想要判断这个链表是否为空,我们首先要判断一下头指针是不是为空,如果为空,就需要进行特殊处理。
if (head == nullptr) {
// 链表为空,需要特殊处理
head = new Node(4); //插入一个新节点4
} else {
// 链表不为空,正常插入或删除第一个节点
Node* newNode = new Node(4);
newNode->next = head->next;
head->next = newNode;
}
这样的话我们就增加了算法的分支(if else),而使用头节点的话就可以避免if else的使用,可以使代码更加简洁。
以下使对带头结点的链表的插入操作:
Node* newNode = new Node(4);
newNode->next = head->next;
head->next = newNode;
这样的话就减少了对链表为空的检查。其实使用头节点还有很多优势,例如,使用头节点可以可以包含一些附件信息(链表长度)等等。
一句话总结就是:使用带头节点的链表可以使链表操作更加一致、简化和可维护,减少特殊情况的处理,提高代码的可读性和可靠性。















 658
658











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











