







前言
在学习Hadoop-MapReduce之前,我们首先要搞懂什么是HadoopMapReduce?具体有什么应用场景?
Hadoop-MapReduce作为一种用于处理和生成大规模数据集的分布式计算框架。
从这一点就可以看出来,作为一种处理大规模数据集的分布式框架,肯定有它的优点,特别是在处理和简化大数据方面。 Hadoop-MapReduce 由两个主要部分组成:Map(映射)和 Reduce(归约)
- Map:负责“分”,就是将复杂的任务分解为若干个“简单的任务”来进行并行处理。在map阶段,输入的数据会被分割成独立的块。Hadoop会将这些块分部在不同的节点上进行处理,从而实现数据的并行化处理,从而提高计算效率。
这里独立的块指的是将大规模的输入数据集拆分成多个较小的部分,这个较小的部分称为“块”。 通常在Hadoop中,默认的块大小是128MB或256MB(可以配置) 假设你有一个 1 TB 的大文件需要处理,如果默认块大小为 128 MB,这个文件会被分割成约 8192 个块(1 TB ÷ 128 MB = 8192),然后这些块被分发到集群中的多个节点上进行处理。每个块的处理任务由一个
map()函数执行,这样整个文件的处理就变成了多个任务的并行执行,从而大大提高了效率。
- Reduce:负责“合”,就是将map阶段处理好的结果进行全局汇总。
- MapReduce运行在yarn集群(ResourceManager进行资源分配,NodeManager执行具体的运算)
YARN 主要负责协调 Hadoop 集群中的计算资源(如 CPU、内存),允许多个应用程序在同一集群上并发运行。
为了搞懂这些抽象的概念,我就举一个例子带大家了解。
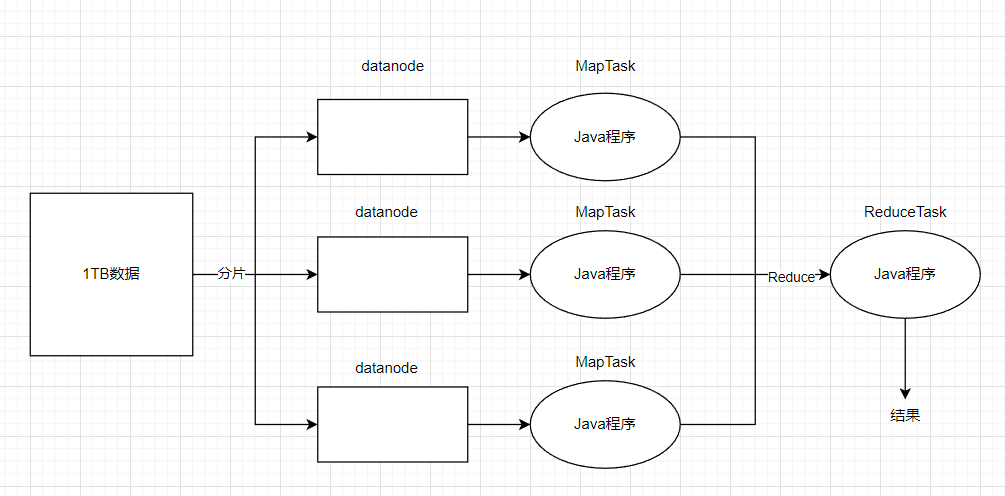
假如说有1TB的数据要处理,那么数据先会经过分片处理后,将数据分配到datanode节点上,然后我们编写好的Java程序就会处理各个节点的任务(MapTask),这个阶段就是Map阶段。在Redcuce阶段,会对Map阶段的输出进行聚合,排序等最终处理,最后生成最终结果。
刚才分析MapReduce的计算过程是在datanode上进行的。那么如果用户想要提交一个任务,它的具体流程是什么样的呢?
MapReduce的计算框架
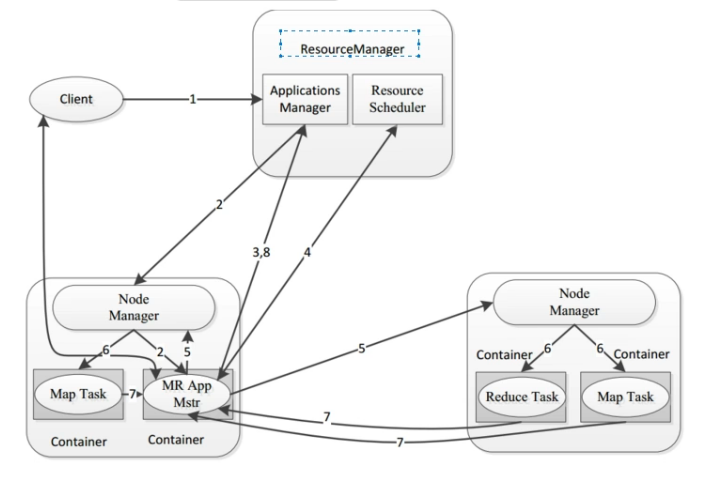
当用户(客户端client)想要提交一个计算任务时,ResourceManager会启动两个模块(Applications Manager和Resource Scheduler)然后Node Manager会启动一个进程App Master,然后App Master会向ResourceManager请求资源(内存,cpu),ResourceManager在收到请求后会由ApplicationManager进行接收,这个时候会由它的中间组件ResourceScheduler进行分配资源,它会告诉AppMaster向哪一个NodeManager获取资源,然后appMaster会将资源列表回复给ResourceScheduler。然后appmaster会向NodeManager分配资源。在资源分配之后,NodeManager会启动MapTask来执行具体的计算任务,同时它还会启动一个ReduceTask,然后ReduceTask会将计算状态和结果汇报给appMaster。最后将结果汇报给applicationMaster。
在了解完MapReduce的基本工作流程之后,那么如何去编写这个业务逻辑处理代码呢?
其实在编写Hadoop MapRedcuce的业务处理代码时,主要分为两个部分:Map函数和Redcuce函数。这些函数的实现通常使用Java语言来实现。 在后续的讲解中,我会详细的讲解编写思路以及过程。
MapReduce的编程规范
在进行MapRedcuce开发时一共八个步骤,其中Map阶段两个步骤,Shuffle阶段4个步骤,Reduce阶段2个步骤。
Map阶段的两个步骤:
- 设置InputFormat类,将数据切分为Key-Value(k1和v1),输入到第二步
- 自定义Map逻辑(编写Map函数),将第一步的结果转换成另外的Key-Value(K2和V2)对,输出结果。
Shuffle阶段4个步骤:
- 对输出的Key-Value对进行**分区**
- 对不同分区的数据按照相同的Key**排序**
- (可选)对分组过的数据初步**规约**,降低数据的网络拷贝
- 对数据进行**分组**,相同Key的Value放入到一个集合中
Reduce阶段2个步骤:
- 对多个Map任务的结果进行排序以及处理,编写Redcuce函数实现自己的逻辑,对输入的Key-Value进行处理,转为新的Key-Value(K3和V3)输出
- 设置OutputFormat处理并保存Redcuce输出的Key-Value数据
下面我们看一个案例
WordCount词频统计
需求:在Linux系统本地创建两个文件,即文件wordfile1.txt和wordfile2.txt。针对这两个小数据集样本编写的MapReduce词频统计程序,不作任何修改,就可以用来处理大规模数据集的词频统计。
过程分析:
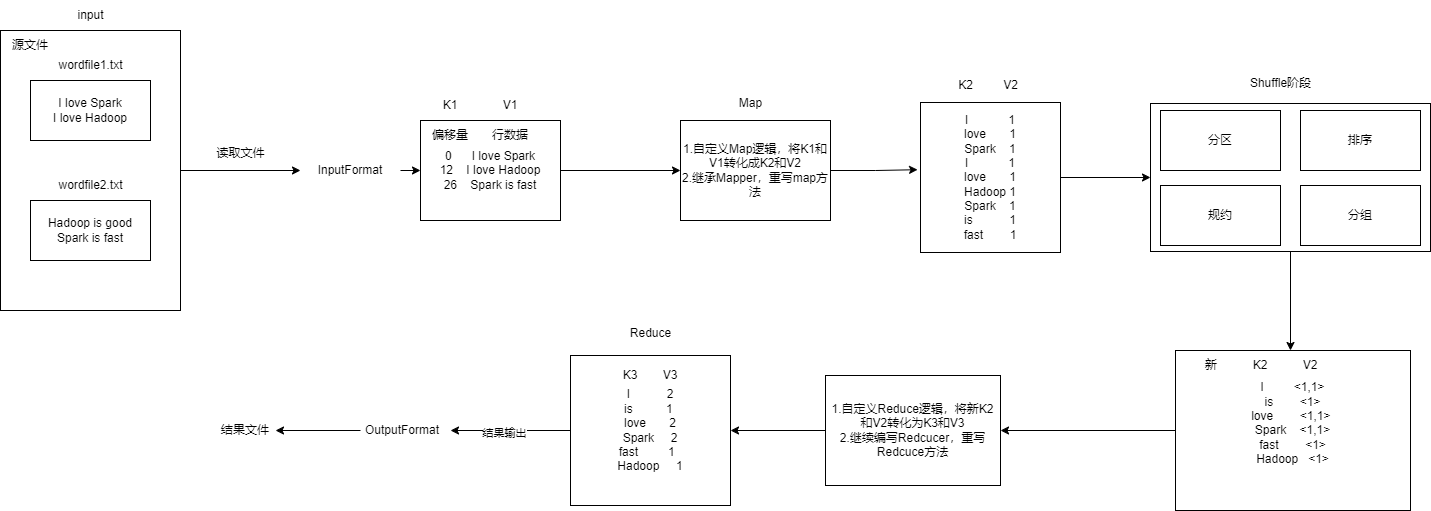
- 重写map方法
/*
Mapper<Object, Text, Text, IntWritable>:四个参数分别表示K1,V1,K2,V2
重写map方法的目的就是将<k1,v1>转化为<k2,v2>,k1是每一行数据的行偏移量,v1是行数据。k2是单词,v2出现次数
数据类型:v1行偏移量是int类型,这里不能用基本数据类型,要用封装类型Object。Text类型是k1的封装类型存储行数据。IntWritable是int的封装类型存储次数
*/
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private static final IntWritable one = new IntWritable(1); //由于V2的值都为1,实现序列化
private Text word = new Text(); //下面要用到K2,这里先创建一个Text类型的K2对象word
public TokenizerMapper() {
}
/*
map(Object key, Text value, Context context):前两个参数表示的是k1和v1,最后一个参数context表示的是上下文对象
*/
public void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString()); //将传入的字符串 value 按默认的空格分隔符拆分成若干个子字符串(token)
while(itr.hasMoreTokens()) {
this.word.set(itr.nextToken());//将token写入k2
context.write(this.word, one);//传给下一个上下文对象比如reduce
}
}
}
- 重写redcuce方法
/*
Reducer<Text, IntWritable, Text, IntWritable>:四个参数分别表示新的k2,v2和k3,v3
*/
public static class IntSumReducer extends Reducer 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 564
564

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











