






记录一下,怕自己忘了。。。。
wget方法一
网址:Archive - LAADS DAAC (nasa.gov)
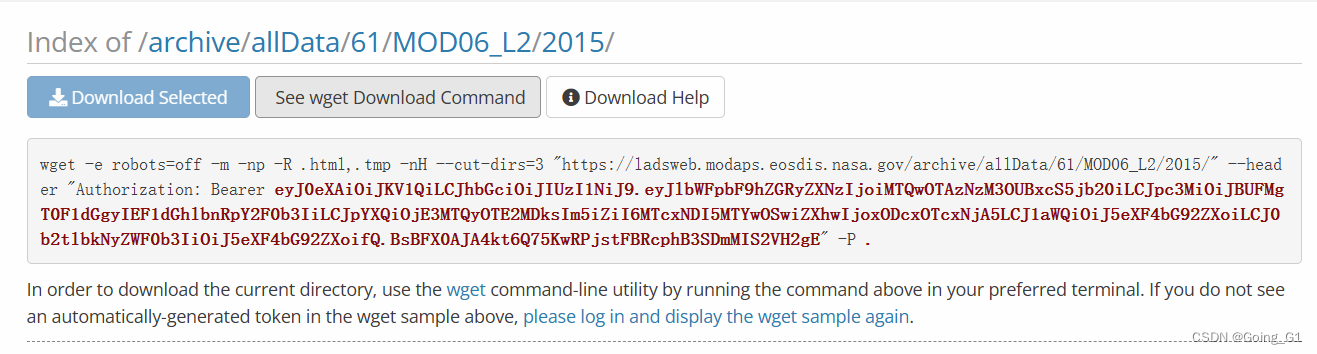 获取wget码,然后直接在cmd命令窗口运行,下载目录为当前所在的目录,激活虚拟环境后,可以先转跳到需要下载的目录,再运行代码。
获取wget码,然后直接在cmd命令窗口运行,下载目录为当前所在的目录,激活虚拟环境后,可以先转跳到需要下载的目录,再运行代码。
缺点一:但是这个方法不知道为什么总是会断掉,也就是说下载了一点点就不下载了,奇奇怪怪的。
缺点二:只能全球下载,不能进行区域选择。
python方法二
这里点击Download Help,转跳至如下界面
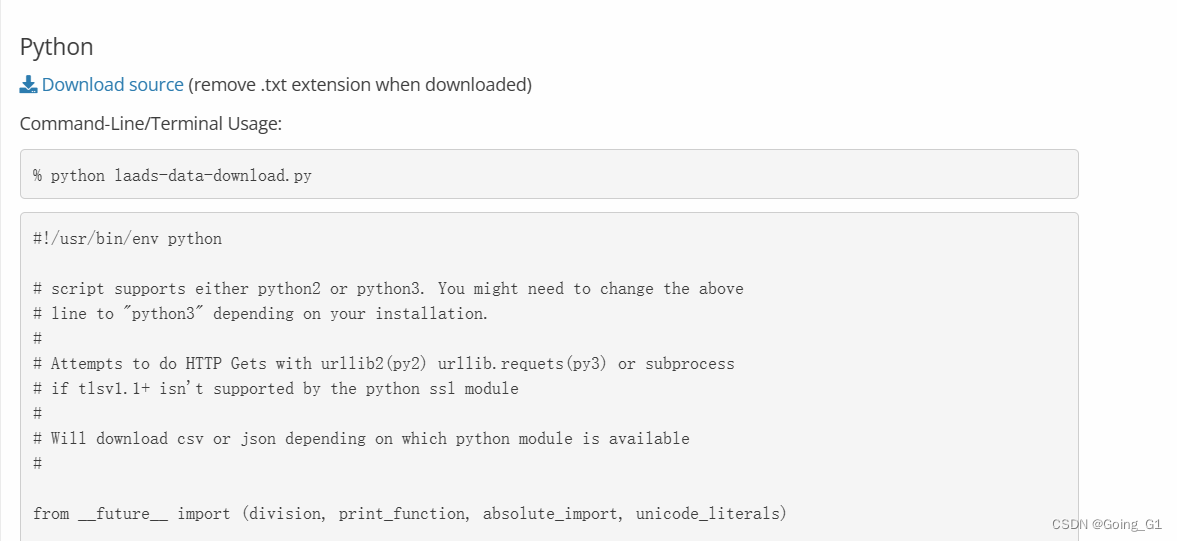
下载txt文件至电脑,然后把txt后缀去掉,这里就是.py文件。
再到命令窗口里面运行,查看帮助,根据帮助修改命令行
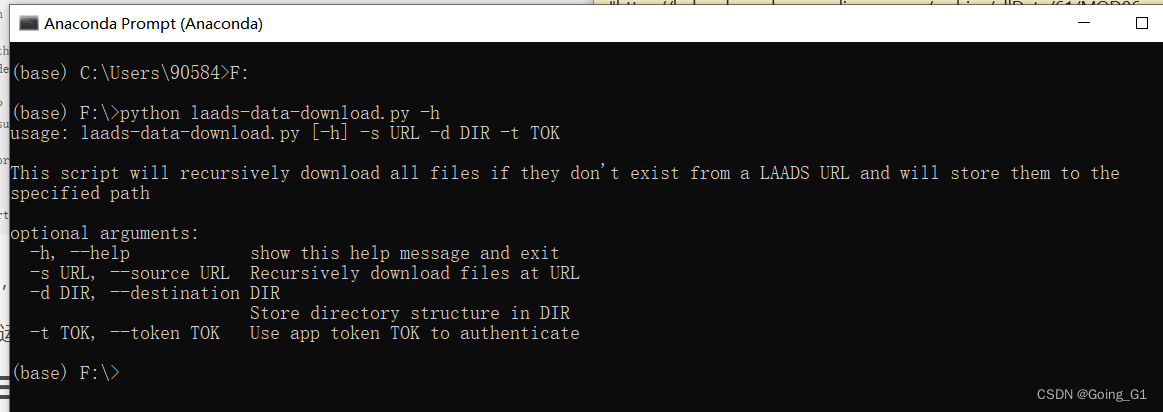
python laads-data-download.py -s https://ladsweb.modaps.eosdis.nasa.gov/archive/allData/61/MOD06_L2/2015/ -d F:\MOD06_L2 -t 你的token
获取token
网址:Find Data - LAADS DAAC (nasa.gov)
注册后,点击login小三角处,选择generate token,便可以获取。
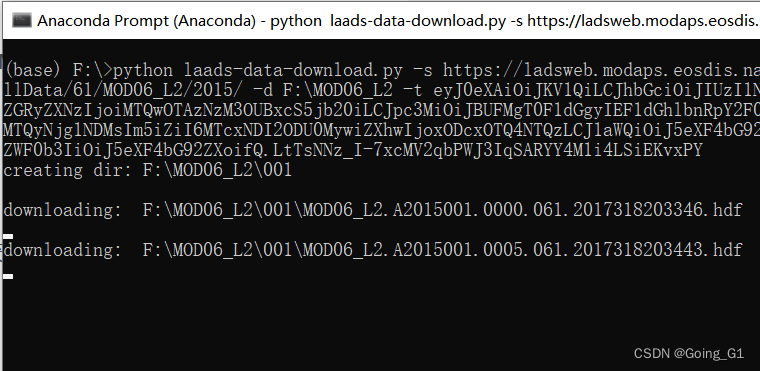
运行成功。
缺点:只能批量下载全球的数据,无法选区域数据下载。
python方法三
网址:Find Data - LAADS DAAC (nasa.gov)
进行如下操作后,筛选出所需要的数据目录,每次只能低于2000条。中国差不多5个月的数据就达到了2000条。

点击下载CSV文件
再用这段代码在python里面进行下载:
原文:MODIS数据批量下载与处理2-一二级产品_mod06 l2产品用户手册-CSDN博客
from __future__ import (division, print_function, absolute_import, unicode_literals)
import os
import os.path
import shutil
import sys
try:
from StringIO import StringIO # python2
except ImportError:
from io import StringIO # python3
USERAGENT = 'tis/download.py_1.0--' + sys.version.replace('\n','').replace('\r','')
def geturl(url, token=None, out=None):
headers = { 'user-agent' : USERAGENT }
if not token is None:
headers['Authorization'] = 'Bearer ' + token
try:
import ssl
CTX = ssl.SSLContext(ssl.PROTOCOL_TLSv1_2)
if sys.version_info.major == 2:
import urllib2
try:
fh = urllib2.urlopen(urllib2.Request(url, headers=headers), context=CTX)
if out is None:
return fh.read()
else:
shutil.copyfileobj(fh, out)
except urllib2.HTTPError as e:
print('HTTP GET error code: %d' % e.code(), file=sys.stderr)
print('HTTP GET error message: %s' % e.message, file=sys.stderr)
except urllib2.URLError as e:
print('Failed to make request: %s' % e.reason, file=sys.stderr)
return None
else:
from urllib.request import urlopen, Request, URLError, HTTPError
try:
fh = urlopen(Request(url, headers=headers), context=CTX)
if out is None:
return fh.read().decode('utf-8')
else:
shutil.copyfileobj(fh, out)
except HTTPError as e:
print('HTTP GET error code: %d' % e.code(), file=sys.stderr)
print('HTTP GET error message: %s' % e.message, file=sys.stderr)
except URLError as e:
print('Failed to make request: %s' % e.reason, file=sys.stderr)
return None
except AttributeError:
# OS X Python 2 and 3 don't support tlsv1.1+ therefore... curl
import subprocess
try:
args = ['curl', '--fail', '-sS', '-L', '--get', url]
for (k,v) in headers.items():
args.extend(['-H', ': '.join([k, v])])
if out is None:
# python3's subprocess.check_output returns stdout as a byte string
result = subprocess.check_output(args)
return result.decode('utf-8') if isinstance(result, bytes) else result
else:
subprocess.call(args, stdout=out)
except subprocess.CalledProcessError as e:
print('curl GET error message: %' + (e.message if hasattr(e, 'message') else e.output), file=sys.stderr)
return None
################################################################################
"""
"""
DESC = "This script will recursively download all files if they don't exist from a LAADS URL and stores them to the specified path"
def sync(src, dest, tok):
'''synchronize src url with dest directory'''
try:
import csv
files = [ f for f in csv.DictReader(StringIO(geturl('%s.csv' % src, tok)), skipinitialspace=True) ]
except ImportError:
import json
files = json.loads(geturl(src + '.json', tok))
# use os.path since python 2/3 both support it while pathlib is 3.4+
items = getItems(r'F:\LAADS_query.2024-04-28T02_15.csv')
for f in files:
# currently we use filesize of 0 to indicate directory
filesize = int(f['size'])
path = os.path.join(dest, f['name'])
url = src + '/' + f['name']
if filesize == 0:
try:
print('creating dir:', path)
os.mkdir(path)
sync(src + '/' + f['name'], path, tok)
except IOError as e:
print("mkdir `%s': %s" % (e.filename, e.strerror), file=sys.stderr)
sys.exit(-1)
else:
try:
if not os.path.exists(path) and f['name'] in items:
print('downloading: ', path)
with open(path, 'w+b') as fh:
geturl(url, tok, fh)
else:
print('skipping: ', path)
except IOError as e:
print("open `%s': %s" % (e.filename, e.strerror), file=sys.stderr)
sys.exit(-1)
return 0
def date2julian(year, month, day):
hour = 10
JD0 = int(365.25 * (year - 1)) + int(30.6001 * (1 + 13)) + 1 + hour / 24 + 1720981.5
if month <= 2:
JD2 = int(365.25 * (year - 1)) + int(30.6001 * (month + 13)) + day + hour / 24 + 1720981.5
else:
JD2 = int(365.25 * year) + int(30.6001 * (month + 1)) + day + hour / 24 + 1720981.5
DOY = JD2 - JD0 + 1
return int(DOY)
def getItems(filename):
f = open(filename, 'r')
f.readline() #读掉表头
items = []
while True:
itemstr = f.readline()
if itemstr == '':
break
items.append(itemstr.split(',')[1].split('/')[7])
return items
if __name__ == '__main__':
destination = r'F:\MOD06_L2\2015'
urlPsth_MOD06 = r'https://ladsweb.modaps.eosdis.nasa.gov/archive/allData/61/MOD06_L2'
startDoy = date2julian(2015, 1, 1)
endDoy = date2julian(2015, 1, 31)
for doy in range(startDoy, endDoy):
sync(urlPsth_MOD06 + '/2015/' + str(doy) + '/', destination, 'token')
好处:可以选择需要的区域进行下载,减少很多不必要的下载。
但是:一个月的数据量有30多G,下载用时3个小时,数据量太大了,想尝试一下GEE,把数据拼接、提取关键量、裁剪等处理好了后,再下载到本地matlab中计算。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









