








博客主页:小馒头学python
本文专栏: Python爬虫五十个小案例
专栏简介:分享五十个Python爬虫小案例

🎓引言
数据分析为我们提供了对市场动态的深刻洞察,能够帮助企业优化运营策略、提升用户体验和增加收入。在本案例中,我们将通过Python进行电商平台用户购买行为数据的分析,揭示不同用户群体的消费模式以及热门产品的销售趋势。通过数据分析,我们希望为平台提供更精确的市场决策依据。
注意:由于本文为学习目的,所使用的数据为生成的虚拟数据,非真实的电商数据。其主要目的是展示数据分析的过程和方法。
🎓生成虚拟电商数据
如果你没有现成的电商数据,可以使用pandas和numpy生成虚拟数据。以下是生成数据的代码示例:
import pandas as pd
import numpy as np
# 设置随机种子,确保每次生成的结果相同
np.random.seed(42)
# 生成虚拟电商数据
num_records = 1000 # 数据记录数
user_ids = np.random.randint(1, 101, size=num_records) # 100个用户
product_ids = np.random.randint(1, 21, size=num_records) # 20个产品
product_categories = ['Electronics', 'Clothing', 'Home', 'Beauty', 'Sports']
purchase_amounts = np.round(np.random.uniform(5, 500, size=num_records), 2)
purchase_dates = pd.to_datetime(np.random.choice(pd.date_range('2023-01-01', '2023-12-31', freq='D'), num_records))
# 随机生成年龄段(假设年龄段为:18-24, 25-34, 35-44, 45-54, 55+)
age_groups = np.random.choice(['18-24', '25-34', '35-44', '45-54', '55+'], size=num_records)
# 随机生成地区
regions = np.random.choice(['North', 'South', 'East', 'West'], size=num_records)
# 创建 DataFrame
df = pd.DataFrame({
'user_id': user_ids,
'purchase_date': purchase_dates,
'product_id': product_ids,
'product_category': np.random.choice(product_categories, num_records),
'purchase_amount': purchase_amounts,
'age_group': age_groups,
'region': regions
})
# 保存数据为CSV文件
df.to_csv('ecommerce_data.csv', index=False)
print("虚拟电商数据已生成并保存为 'ecommerce_data.csv'.")
通过以上代码,我们生成了一个包含1000条记录的电商数据集,包括用户ID、购买日期、产品ID、产品类别、购买金额、年龄段和地区等字段。你可以根据实际需要调整数据量和内容。
🎓环境配置与库导入
我们将使用Python的常见数据分析库,如pandas、numpy、matplotlib和seaborn。这些库可以帮助我们进行数据处理、统计分析以及可视化。
安装必要的库
首先,确保你已经安装了所需的库。如果尚未安装,可以通过以下命令进行安装:
pip install pandas numpy matplotlib seaborn
导入库
然后,我们在代码中导入相关的库:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
🎓数据加载与预处理
数据预处理是数据分析的第一步。我们需要加载数据,检查数据的结构,处理缺失值和异常值,确保数据质量。
🎓加载数据
假设我们已经生成并保存了ecommerce_data.csv文件,接下来,我们将加载数据并查看其基本信息:
# 加载数据
df = pd.read_csv('ecommerce_data.csv')
# 显示数据的前几行
print(df.head())
# 查看数据的基本信息
print(df.info())
🎓处理缺失值
我们检查数据中是否有缺失值,并根据情况选择填充或删除:
# 检查缺失值
print(df.isnull().sum())
# 填充缺失值
df.fillna(method='ffill', inplace=True)
🎓数据分析
🎓用户购买行为概况
首先,我们来分析每个用户的购买总额和购买频次。这有助于了解平台用户的消费习惯,以及哪些用户更活跃。
# 计算每个用户的总购买金额与购买次数
user_stats = df.groupby('user_id').agg(
total_purchase_amount=('purchase_amount', 'sum'),
purchase_count=('purchase_amount', 'count')
).reset_index()
# 显示前几行结果
print(user_stats.head())
🎓用户群体分析:年龄段
接下来,我们将对不同年龄段的用户进行分析,查看不同年龄段的平均购买金额,帮助我们识别出哪一类用户的消费能力最强。
# 按年龄段分组,计算每个年龄段的平均购买金额
age_group_stats = df.groupby('age_group')['purchase_amount'].mean().reset_index()
# 可视化年龄段与购买金额的关系
plt.figure(figsize=(10, 6))
sns.barplot(x='age_group', y='purchase_amount', data=age_group_stats)
plt.title('Average Purchase Amount by Age Group')
plt.xlabel('Age Group')
plt.ylabel('Average Purchase Amount')
plt.show()
🎓产品类别分析
产品类别分析可以帮助我们识别出哪些类别的产品最受欢迎。我们将按产品类别计算总销售额,并通过可视化展示各类别的销售情况。
# 按产品类别计算销售额
category_stats = df.groupby('product_category')['purchase_amount'].sum().reset_index()
# 可视化不同产品类别的销售额
plt.figure(figsize=(12, 6))
sns.barplot(x='purchase_amount', y='product_category', data=category_stats)
plt.title('Total Sales by Product Category')
plt.xlabel('Total Purchase Amount')
plt.ylabel('Product Category')
plt.show()
🎓购买频次分析
我们还可以通过用户购买次数的分布,了解平台上用户的购买频率。这有助于识别出平台的核心用户群体。
# 绘制购买次数的分布
plt.figure(figsize=(10, 6))
sns.histplot(user_stats['purchase_count'], bins=30, kde=True)
plt.title('Distribution of Purchase Frequency')
plt.xlabel('Number of Purchases')
plt.ylabel('Frequency')
plt.show()
🎓完整源码
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# 生成虚拟电商数据
np.random.seed(42)
num_records = 1000 # 数据记录数
user_ids = np.random.randint(1, 101, size=num_records) # 100个用户
product_ids = np.random.randint(1, 21, size=num_records) # 20个产品
product_categories = ['Electronics', 'Clothing', 'Home', 'Beauty', 'Sports']
purchase_amounts = np.round(np.random.uniform(5, 500, size=num_records), 2)
purchase_dates = pd.to_datetime(np.random.choice(pd.date_range('2023-01-01', '2023-12-31', freq='D'), num_records))
# 随机生成年龄段(假设年龄段为:18-24, 25-34, 35-44, 45-54, 55+)
age_groups = np.random.choice(['18-24', '25-34', '35-44', '45-54', '55+'], size=num_records)
# 随机生成地区
regions = np.random.choice(['North', 'South', 'East', 'West'], size=num_records)
# 创建 DataFrame
df = pd.DataFrame({
'user_id': user_ids,
'purchase_date': purchase_dates,
'product_id': product_ids,
'product_category': np.random.choice(product_categories, num_records),
'purchase_amount': purchase_amounts,
'age_group': age_groups,
'region': regions
})
# 保存数据为CSV文件
df.to_csv('ecommerce_data.csv', index=False)
print("虚拟电商数据已生成并保存为 'ecommerce_data.csv'.")
# 载入数据
df = pd.read_csv('ecommerce_data.csv')
# 数据预处理
print("数据基本信息:")
print(df.info())
# 检查缺失值
print("\n缺失值统计:")
print(df.isnull().sum())
# 填充缺失值(如有)
df.fillna(method='ffill', inplace=True)
# 计算每个用户的购买总额和购买次数
user_stats = df.groupby('user_id').agg(
total_purchase_amount=('purchase_amount', 'sum'),
purchase_count=('purchase_amount', 'count')
).reset_index()
# 显示前几行结果
print("\n每个用户的购买总额与购买次数:")
print(user_stats.head())
# 用户群体分析:年龄段
age_group_stats = df.groupby('age_group')['purchase_amount'].mean().reset_index()
# 可视化年龄段与购买金额的关系
plt.figure(figsize=(10, 6))
sns.barplot(x='age_group', y='purchase_amount', data=age_group_stats)
plt.title('Average Purchase Amount by Age Group')
plt.xlabel('Age Group')
plt.ylabel('Average Purchase Amount')
plt.show()
# 产品类别分析:按产品类别计算销售额
category_stats = df.groupby('product_category')['purchase_amount'].sum().reset_index()
# 可视化不同产品类别的销售额
plt.figure(figsize=(12, 6))
sns.barplot(x='purchase_amount', y='product_category', data=category_stats)
plt.title('Total Sales by Product Category')
plt.xlabel('Total Purchase Amount')
plt.ylabel('Product Category')
plt.show()
# 购买频次分析:绘制购买次数的分布
plt.figure(figsize=(10, 6))
sns.histplot(user_stats['purchase_count'], bins=30, kde=True)
plt.title('Distribution of Purchase Frequency')
plt.xlabel('Number of Purchases')
plt.ylabel('Frequency')
plt.show()
🎓可视化展示
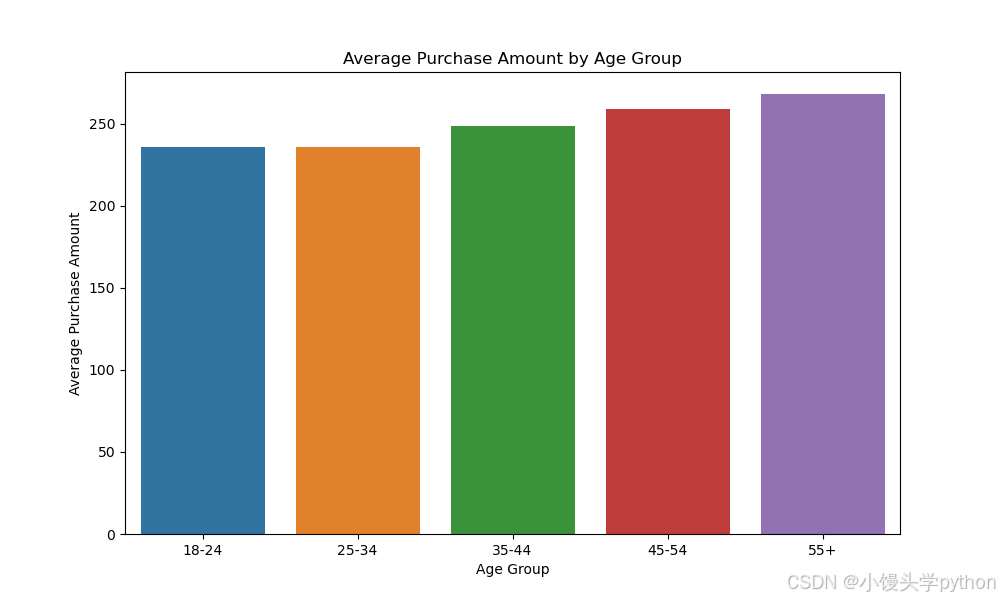
从上图可以看出,年龄在55+的平均购物数量更多一些,这可能由于年级大的人群对于某些生活产出的数量比年轻人更多一些
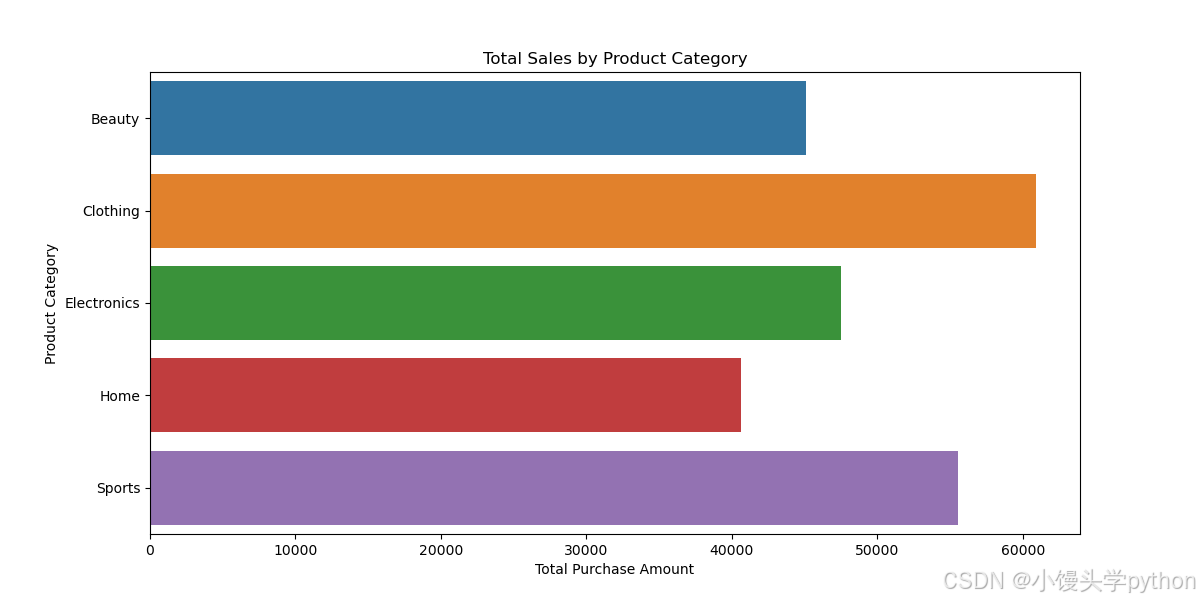
从总的销售来看,衣服的占比最高
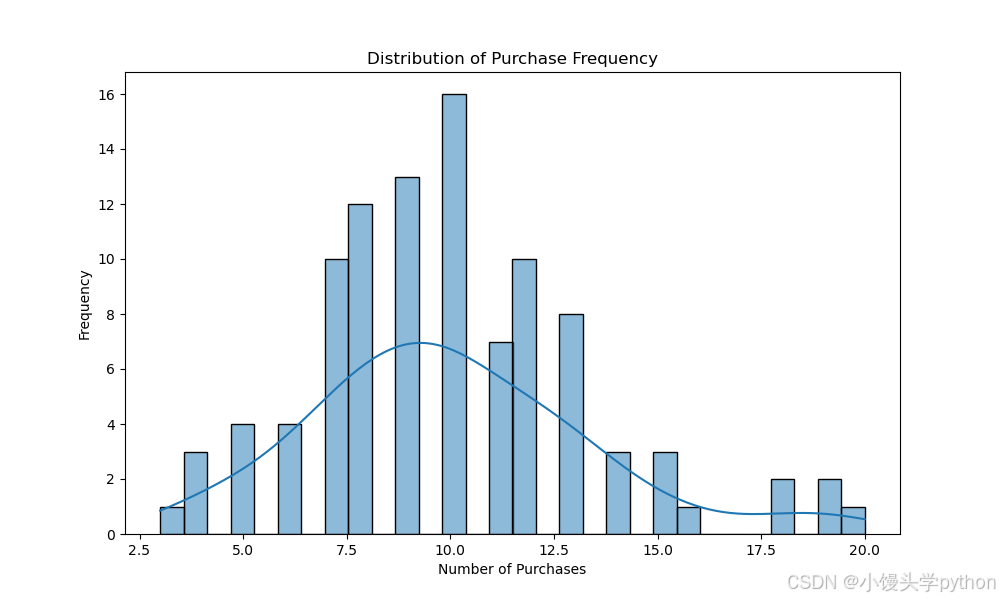
购买频率分布在10点左右比较高,5以内和15以上的购买频率较低
🎓总结
本文通过一个电商平台用户购买行为的案例,展示了如何使用Python进行数据分析。我们通过对数据的加载、清洗、处理和可视化,获得了关于用户行为和产品销售的一些有价值的洞察。数据分析不仅可以帮助我们理解现有的业务状况,还能为优化市场策略和提升用户体验提供可靠的依据。





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











