







假如我们希望收集一个对象list中每个对象的某个字段值,有很多做法,for循环,方法回调,反射都可以帮助我们完成
反射我们不讨论,非必要不用,性能相比其他毕竟差一点
for循环我们也不讨论,代码太冗余了
所以这里讨论一下方法回调的方式 , 而stream和我们自定义的工具方法都是基于方法回调的,所以到底哪个好呢?
stream
外部代码是这样的
List<Long> productIdList = productExchangeNumReqDtoList.stream() .map(ProductExchangeNumReqDto::getProductId) .collect(Collectors.toList());底层代码(JDK源码)
@Override @SuppressWarnings("unchecked") public final <R> Stream<R> map(Function<? super P_OUT, ? extends R> mapper) { Objects.requireNonNull(mapper); return new StatelessOp<P_OUT, R>(this, StreamShape.REFERENCE, StreamOpFlag.NOT_SORTED | StreamOpFlag.NOT_DISTINCT) { @Override Sink<P_OUT> opWrapSink(int flags, Sink<R> sink) { return new Sink.ChainedReference<P_OUT, R>(sink) { @Override public void accept(P_OUT u) { downstream.accept(mapper.apply(u)); } }; } }; } @Override @SuppressWarnings("unchecked") public final <R, A> R collect(Collector<? super P_OUT, A, R> collector) { A container; if (isParallel() && (collector.characteristics().contains(Collector.Characteristics.CONCURRENT)) && (!isOrdered() || collector.characteristics().contains(Collector.Characteristics.UNORDERED))) { container = collector.supplier().get(); BiConsumer<A, ? super P_OUT> accumulator = collector.accumulator(); forEach(u -> accumulator.accept(container, u)); } else { container = evaluate(ReduceOps.makeRef(collector)); } return collector.characteristics().contains(Collector.Characteristics.IDENTITY_FINISH) ? (R) container : collector.finisher().apply(container); }
自定义工具方法
外部代码
List<Long> productIdList2 = ListUtil.collectionField( productExchangeNumReqDtoList, ProductExchangeNumReqDto::getProductId );底层源码(程序员自定义)
/** * 在一个指定的对象list中,收集每一个元素(对象)的指定字段,并将收集好的字段装入新的集合返回 * @param objList 指定的对象list * @param getFieldValueFunc 用于获取每一个对象指定字段的回调函数,也是用于指定收集哪个字段的 * @return 一个基于对象集合的对象字段集合 * @param <T> 对象泛型 * @param <F> 字段泛型 */ public static<T,F> List<F> collectionField(List<T> objList, Function<T,F> getFieldValueFunc) { //校验 objList为空则直接返回空 而getFieldValueFunc为null时抛出错误 if(CollUtil.isEmpty(objList)){ return new ArrayList<>(); } if(Objects.isNull(getFieldValueFunc)){ throw new RuntimeException("ListUtil collectionField 不提供有效的回调函数,但期望成功获取对象的字段值"); } //逐个遍历对象 List<F> result = new ArrayList<>(); for (T t : objList) { //获取并收集这个对象的这个字段 F fieldValue = getFieldValueFunc.apply(t); result.add(fieldValue); } return result; }
性能测试如下:
性能测试结论:
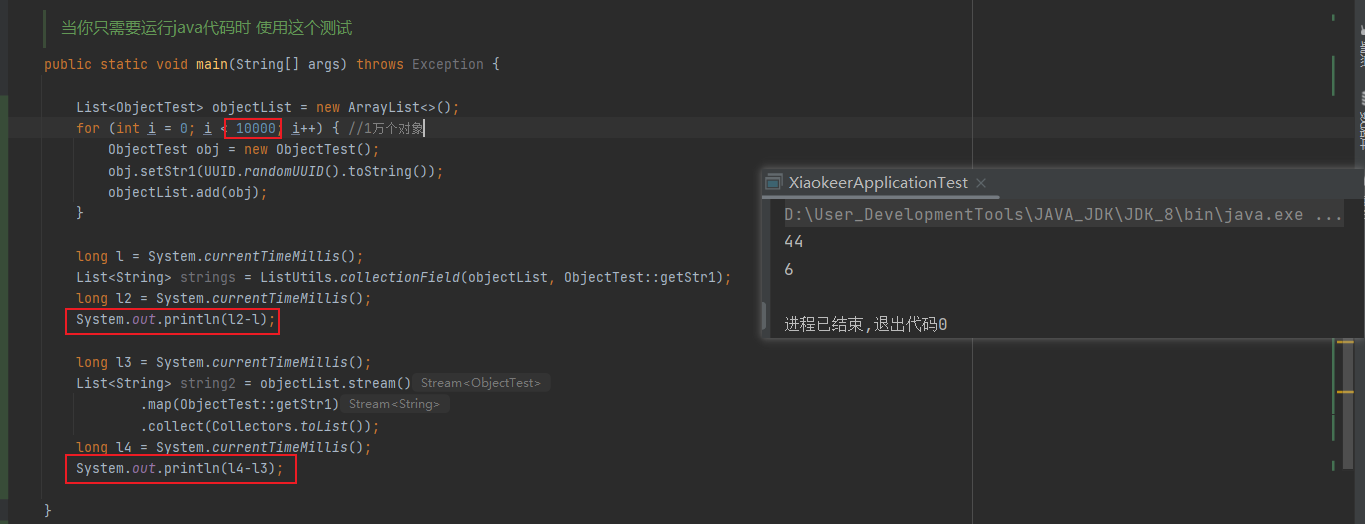
当元素较少时stream性能更好,图1
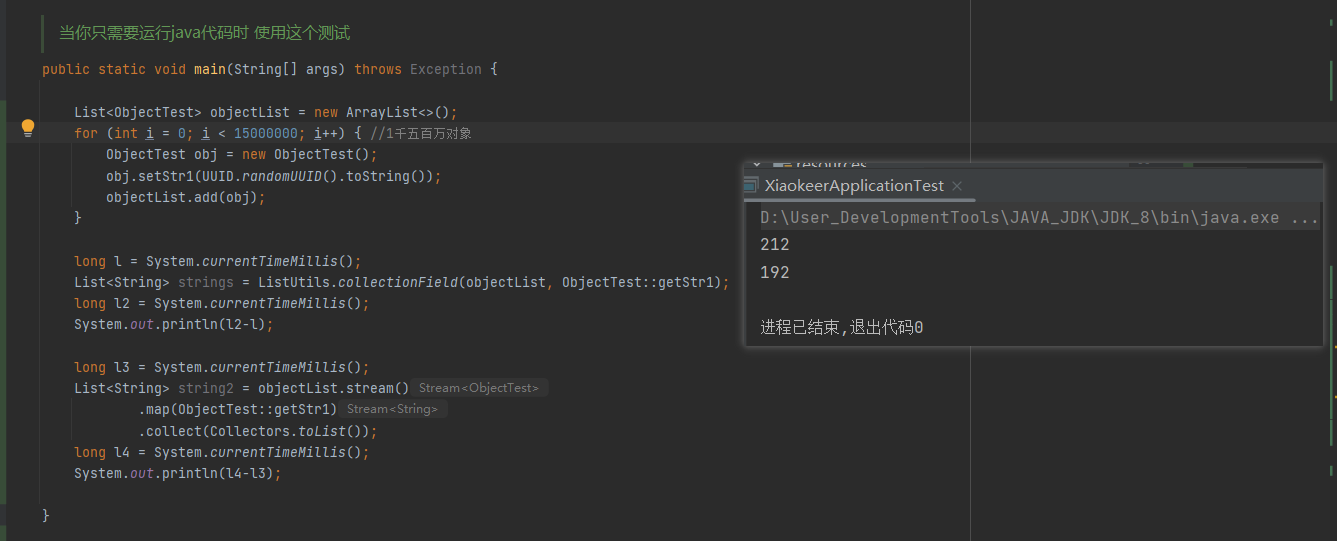
当元素在1千5百万时,stream性能则和工具方法持平,图2
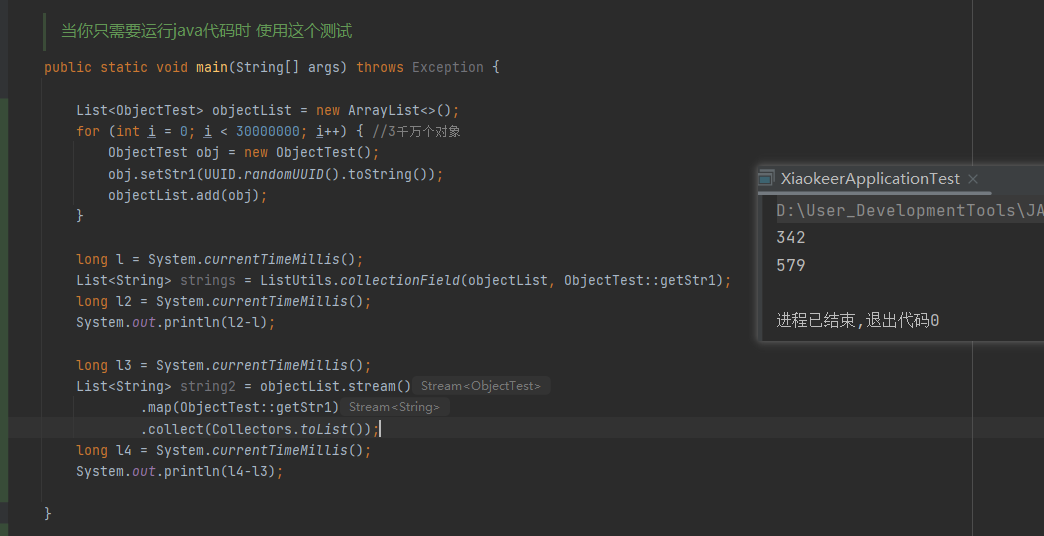
当元素3千万时,工具方法性能超过stream,图3
所以用什么都懂了吧
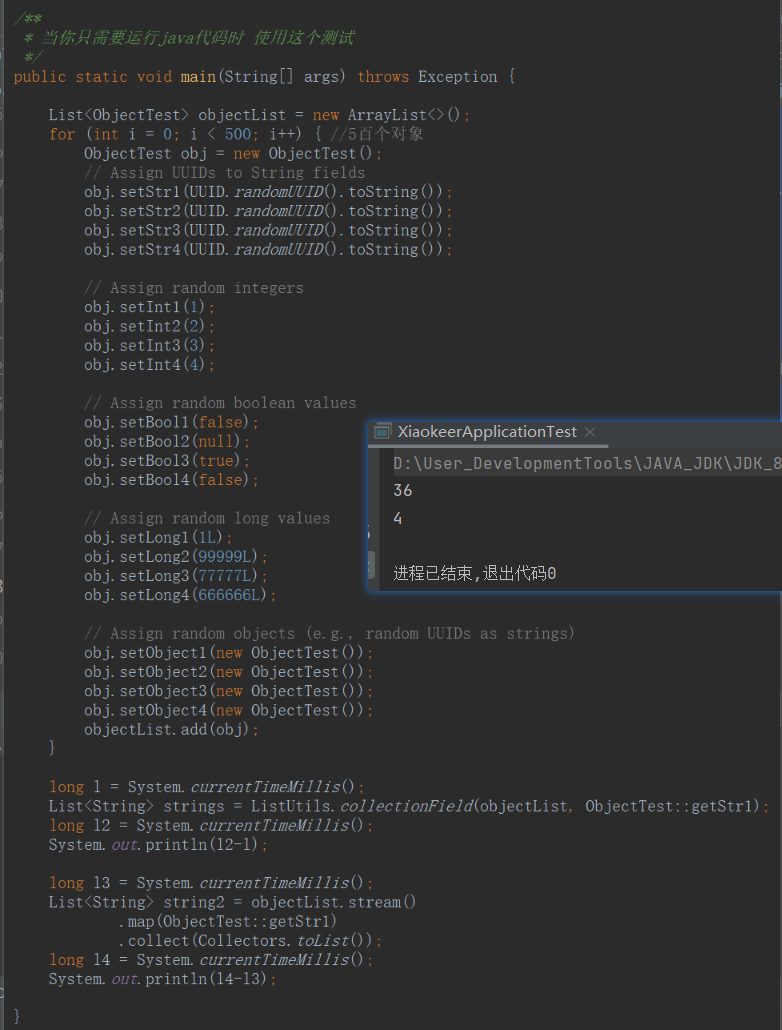
但是别急别急.如果这个对象字段再多点呢.我们模仿实际情况,1个对象可能20个字段,并且有这样的对象1000个(实际上定时任务的接口,对象和字段会更多) 再来测试一下
假设这样对象有1万个呢?
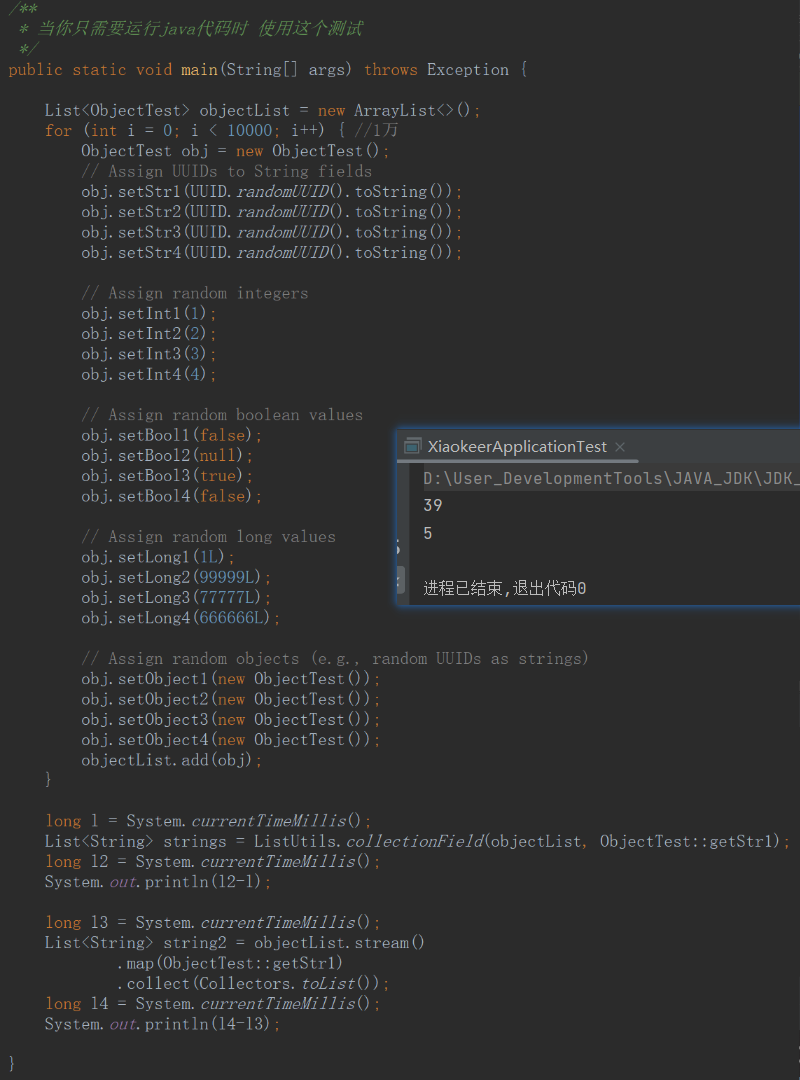
所以最后建议大家封装stream,这样既有性能也有可读性和简洁性 ??? QAQ
public static<T,F> List<F> collectionFieldByStream(List<T> objList, Function<T,F> getFieldValueFunc) { //校验 objList为空则直接返回空 而getFieldValueFunc为null时抛出错误 if(CollUtil.isEmpty(objList)){ return new ArrayList<>(); } if(Objects.isNull(getFieldValueFunc)){ throw new RuntimeException("ListUtil collectionField 不提供有效的回调函数,但期望成功获取对象的字段值"); } return objList.stream().map( getFieldValueFunc ).collect( Collectors.toList() ); }
END















 5191
5191











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









