







附Dense源码:
class Dense(Layer):
def __init__(self, units,
activation=None,
use_bias=True,
kernel_initializer='glorot_uniform',
bias_initializer='zeros',
kernel_regularizer=None,
bias_regularizer=None,
activity_regularizer=None,
kernel_constraint=None,
bias_constraint=None,
**kwargs):
if 'input_shape' not in kwargs and 'input_dim' in kwargs:
kwargs['input_shape'] = (kwargs.pop('input_dim'),)
super(Dense, self).__init__(**kwargs)
self.units = units
self.activation = activations.get(activation)
self.use_bias = use_bias
self.kernel_initializer = initializers.get(kernel_initializer)
self.bias_initializer = initializers.get(bias_initializer)
self.kernel_regularizer = regularizers.get(kernel_regularizer)
self.bias_regularizer = regularizers.get(bias_regularizer)
self.activity_regularizer = regularizers.get(activity_regularizer)
self.kernel_constraint = constraints.get(kernel_constraint)
self.bias_constraint = constraints.get(bias_constraint)
self.input_spec = InputSpec(min_ndim=2)
self.supports_masking = True
def build(self, input_shape):
assert len(input_shape) >= 2
input_dim = input_shape[-1]
self.kernel = self.add_weight(shape=(input_dim, self.units),
initializer=self.kernel_initializer,
name='kernel',
regularizer=self.kernel_regularizer,
constraint=self.kernel_constraint)
if self.use_bias:
self.bias = self.add_weight(shape=(self.units,),
initializer=self.bias_initializer,
name='bias',
regularizer=self.bias_regularizer,
constraint=self.bias_constraint)
else:
self.bias = None
self.input_spec = InputSpec(min_ndim=2, axes={-1: input_dim})
self.built = True
def call(self, inputs):
output = K.dot(inputs, self.kernel)
if self.use_bias:
output = K.bias_add(output, self.bias, data_format='channels_last')
if self.activation is not None:
output = self.activation(output)
return output
def compute_output_shape(self, input_shape):
assert input_shape and len(input_shape) >= 2
assert input_shape[-1]
output_shape = list(input_shape)
output_shape[-1] = self.units
return tuple(output_shape)
def get_config(self):
config = {
'units': self.units,
'activation': activations.serialize(self.activation),
'use_bias': self.use_bias,
'kernel_initializer': initializers.serialize(self.kernel_initializer),
'bias_initializer': initializers.serialize(self.bias_initializer),
'kernel_regularizer': regularizers.serialize(self.kernel_regularizer),
'bias_regularizer': regularizers.serialize(self.bias_regularizer),
'activity_regularizer':
regularizers.serialize(self.activity_regularizer),
'kernel_constraint': constraints.serialize(self.kernel_constraint),
'bias_constraint': constraints.serialize(self.bias_constraint)
}
base_config = super(Dense, self).get_config()
return dict(list(base_config.items()) + list(config.items()))
正文:
keras介绍
Keras 是一个用 Python 编写的高级神经网络 API,它能够以 TensorFlow, CNTK, 或者 Theano 作为后端运行。Keras 的开发重点是支持快速的实验。能够以最小的时延把你的想法转换为实验结果,是做好研究的关键。 如果你在以下情况下需要深度学习库,请使用 Keras: 允许简单而快速的原型设计(由于用户友好,高度模块化,可扩展性)。 同时支持卷积神经网络和循环神经网络,以及两者的组合。 在 CPU 和 GPU 上无缝运行。
安装
pip install TensorFlow
pip install keras论文连接
keras代码实现
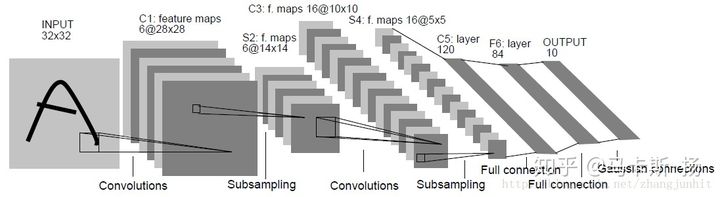
emmmm,我相信大家一定都看过最入门的lenet了吧,网上也是很多很多这个网络的代码实现,我就开门见山的直接教你这么用keras实现吧,这里有一点的是,我们用的是28*28的MNIST数据集。
头文件
#coding=utf-8
from keras.models import Sequential
from keras.layers import Dense,Flatten
from keras.layers.convolutional import Conv2D, MaxPooling2D
from keras.utils.np_utils import to_categorical
from keras.datasets import mnist
from keras.utils import plot_modelSequential:顺序模型 Dense:全连接,简称FC Flatten:上图中s4到c5的过程,相当于把1655的feature map展开成400的特征向量,在通过全连接压成120维的特征向量 Conv2D:2d卷积 MaxPooling2D:2d下采样,文章中的subsampling to_categorical:把一维的向量转换为num_class维的One-hot编码 from keras.datasets import mnist:keras自带了MNIST数据集 plot_model:打印我们等下建好的模型,相当于可视化模型
加载数据集
(X_train,y_train),(X_test,y_test)=mnist.load_data()
#print(X_train.shape,y_train.shape)
X_train = X_train.reshape(-1,28, 28,1)
X_test = X_test.reshape(-1, 28, 28,1)
#print(X_train.shape,y_train.shape)
y_train = to_categorical(y_train, num_classes=10)
y_test = to_categorical(y_test, num_classes=10)
print(X_train.shape,y_train.shape)X_train,y_train:训练的样本的数据和labels (X_test,y_test: 测试的样本的数据和labels (60000, 28, 28) (60000,) (60000, 28, 28, 1) (60000,) (60000, 28, 28, 1) (60000, 10)
搭建模型
model = Sequential()
#layer2
model.add(Conv2D(6, (3,3),strides=(1,1),input_shape=X_train.shape[1:],data_format='channels_last',padding='valid',activation='relu',kernel_initializer='uniform'))
#layer3
model.add(MaxPooling2D((2,2)))
#layer4
model.add(Conv2D(16, (3,3),strides=(1,1),data_format='channels_last',padding='valid',activation='relu',kernel_initializer='uniform'))
#layer5
model.add(MaxPooling2D(2,2))
#layer6
model.add(Conv2D(120, (5,5),strides=(1,1),data_format='channels_last',padding='valid',activation='relu',kernel_initializer='uniform'))
model.add(Flatten())
#layer7
model.add(Dense(84,activation='relu'))
#layer8
model.add(Dense(10,activation='softmax'))
#print
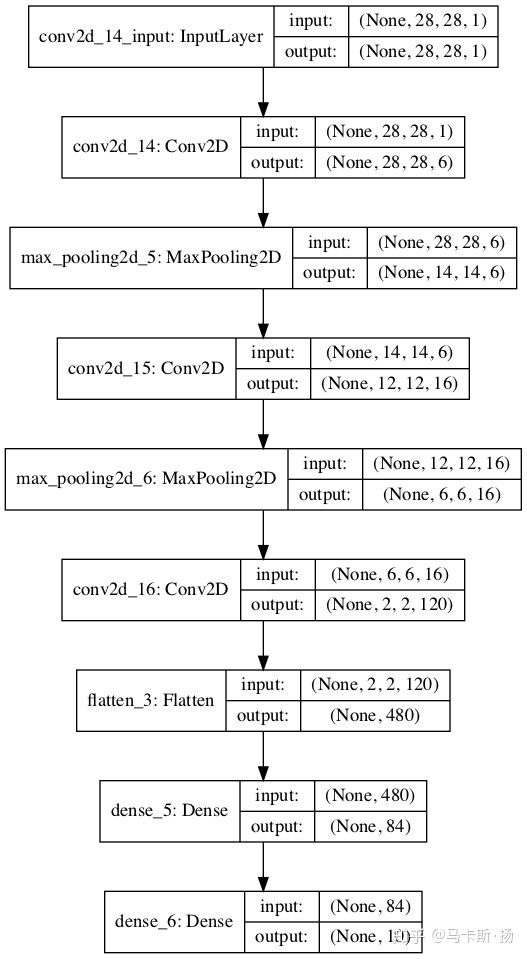
model.summary()第一,二层:6个(33)的卷积核,步长为1(默认也是1), 第一个网络层要有input_shape参数,告诉神经网络你的输入的张量的大小是多少,我推荐的写法是X_train.shape[1:],这样的话我换数据集就不用去换参数,网络会自适应。 data_format='channels_last'的意思是告诉keras你的channel是在前面还是后面,tensorflow后台默认是last,theano后台默认是first,我们这里是默认值(不用轻易改变,对训练时间有很大影响,要尽量符合后端的顺序,比如tensorflow后台就不用输入channels_first,如果是这样的话,实际训练还是会转成last,极大的降低速度)。 padding='valid'(默认valid),表示特征图的大小是会改变的,‘same’是周边补充空白表示特征图大小不变。 activation='relu'表示激活函数是relu,在卷积完之后运行激活函数,默认是没有。 kernel_initializer='uniform'表示卷积核为默认类型 第三层:Maxpooling,参数比较少,就一个池化核的大小,22,步长strides默认和池化大小一致。 第6层:Flatten:上图中s4到c5的过程,相当于把1655的feature map展开成400的特征向量,在通过全连接压成120维的特征向量 最后一层:Dense(10)表示把他压成和我们labels一样的维度10,通过softmax进行激活(多分类用softmax) model.summary():打印网络结构及其内部参数
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_14 (Conv2D) (None, 28, 28, 6) 60
_________________________________________________________________
max_pooling2d_5 (MaxPooling2 (None, 14, 14, 6) 0
_________________________________________________________________
conv2d_15 (Conv2D) (None, 12, 12, 16) 880
_________________________________________________________________
max_pooling2d_6 (MaxPooling2 (None, 6, 6, 16) 0
_________________________________________________________________
conv2d_16 (Conv2D) (None, 2, 2, 120) 48120
_________________________________________________________________
flatten_3 (Flatten) (None, 480) 0
_________________________________________________________________
dense_5 (Dense) (None, 84) 40404
_________________________________________________________________
dense_6 (Dense) (None, 10) 850
=================================================================
Total params: 90,314
Trainable params: 90,314
Non-trainable params: 0
_________________________________________________________________编译及训练
model.compile(optimizer='sgd',loss='categorical_crossentropy',metrics=['accuracy'])
print("train____________")
model.fit(X_train,y_train,epochs=1,batch_size=128,)
print("test_____________")
loss,acc=model.evaluate(X_test,y_test)
print("loss=",loss)
print("accuracy=",acc)model.compile:对模型进行编译, optimizer是优化器,我这里选的是随机梯度下降,具体还要许多优化器,你可以上官网查看 loss='categorical_crossentropy':多分类用的one-hot交叉熵 metrics=['accuracy']:表示我们要优化的是正确率 model.fit(X_train,y_train,epochs=10,batch_size=128,):进行10轮,批次为128的训练,默认训练过程中是会加入正则化防止过拟合。 loss,acc=model.evaluate(X_test,y_test):对样本进行测试,默认不使用正则化,返回损失值和正确率。
模型的画图和图片保存
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
from keras.utils import plot_model
plot_model(model,to_file='example.png',show_shapes=True)
lena = mpimg.imread('example.png') # 读取和代码处于同一目录下的 lena.png
#此时 lena 就已经是一个 np.array 了,可以对它进行任意处理
lena.shape #(512, 512, 3)
plt.imshow(lena) # 显示图片
plt.axis('off') # 不显示坐标轴
plt.show()祖传模型打印代码,我觉得注释已经足够详细了
模型的保存
config = model.get_config()
model = model.from_config(config)总结
在bilibili上上传的代码实现视频















 2486
2486











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









