







第二章
1. Hadoop 将mapreduce 的输入数据划分成等小的数据块,称为输入分片,每个分片对应一个map任务。分片不能太大也不能太小,太大了并行的速率较低,太小了io花费的时间太多,默认是一个hdfs块的大小,也就是64m,因为这样的话就不需要跨节点调度不同的hdfs文件,也可以自己调节。
2.map任务将输出写入本地硬盘而并不是hdfs,因为map的输出的是中间结果,需要reduce进行进一步处理。所以如果将map输入写入hdfs,删除的时候还要删除备份。难免小题大做。
3.单个reduce任务的输入通常来自所有mapper的输出,排过序的map输出通常通过网络传输到运行reduce任务的节点,数据在reduce端合并,然后由用户定义reduce处理,reduce结果写入hdfs。 reduce的数量由用户指定,map会为每个reduce建立一个分区,每个分区有很多键,通过hash来实现分区。
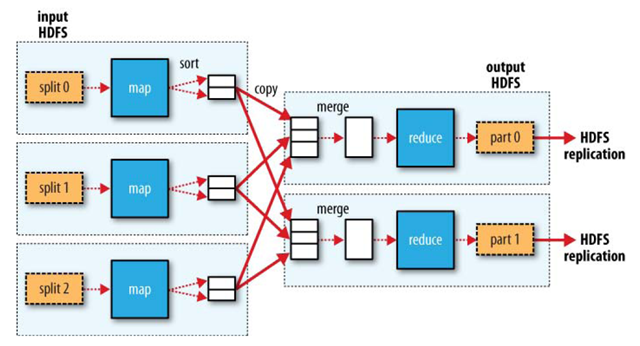
4. 集群中的可用带宽限制了mapreduce的数量,因此尽量避免map任务和reduce的数据传输。可以用combiner处理map的输出,combiner的输出作为reduce的输入。combiner可以将map中的结果进行合并,然后输出结果给reduce从而减少reduce的数量。
5.hadoop提供了maoreduce的API,允许使用非java语言编写程序。hadoop 的streaming 使用Unix 标准流作为hadoop 和应用程序之间的接口,所有可以使用标准输入输出流的程序都可以编写mapreduce程序。 map的输入数据是根据标准输入输出流传递给map函数的,map输出的键值对是以一个制表符号分隔开来的。 hadoop的pipes 是hadoop mapreduce的c++接口的代称,pipes使用套接字作为tasktracker与c++map函数或reduce函数之间的通道。c++的键和值按字节缓冲,这样简化了接口,但是用起来更麻烦。
第三章
1.hdfs 不适合低延迟的数据访问需求,因为集群建立在比较廉价的硬件上,节点的故障几率比较高。hdfs 是为高数据吞吐量应用优化的,这可能会以髙时间延迟为代价,对于低时间延迟的访问需求,hbase是更好的选择。
2.namenode将文件系统的元数据存储在内存中,所以hdfs所能存储的文件总数受限于namenode的内存容量。 根据经验,每个文件、目录和数据块的存储信息大约150字节,如果有一百万个文件,至少需要300m内存,存储数十亿个文件会超过当前的硬件能力。
3.hdfs 可能只有一个writer,写的操作总是将数据添加到文件的末尾,不支持多个写入者的操作,也不支持在文件的任意位置进行修改。
4.hdfs 有两类节点,分别是namenode (管理者) 和 多个datanode (工作者)。其中namenode 管理文件系统的命名空间,它维护者文件系统树及整理树内所有的文件和目录。客户端通过与namenode和datanode的交互来访问整个文件系统。
5.hdfs 的文件操作代码和命令行参考之前的整理: http://blog.csdn.net/nywsp/article/details/17915265
http://blog.csdn.net/nywsp/article/details/21862977
6.namenode 会挑选合适的datanode来存放存储副本,需要考虑可靠性、写入带宽和读取带宽之间进行权衡,既不能把所有的副本都存放到一个节点上,也不能放在所有的数据中心上,系统会根据均衡器来选择适当的节点,比如不是太繁忙,容量足够大等等。
7.hdfs 可以通过通配符等方法对数据进行并行复制,distcp 是作为一个mapreduce作业来实现的,通过在集中中执行map操作来完成。 如:
hadoop distcp hdfs://namenode1/foo hdfs://namenode2/bar
8. 每个文件都按照块的形式存储的话,每个块的元数据存储在namenode的内存中,会消耗很多的内存空间,hadoop存档文件或HAR文件是一个高效的文件存档工具,可以将多个文件放入hdfs块,减少内存的同时还能允许对文件的透明操作。
hadoop archive -archiveName file.har /my/files /my















 3108
3108

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









