







WaterMark
一、什么是水位线?
- 通常情况下,由于网络或系统等外部因素影响,事件数据往往不能及时传输至Flink系统中,导致数据乱序或者延迟到达等问题,因此,需要有一种机制能够控制数据处理的过程和进度,这种机制就是水位线
- 水位线本质上是一个时间戳,且是动态变化的,会根据最大事件时间生成
watermark = 进入Flink窗口的最大事件时间(maxEventTime) - 一定的延迟时间(t)
//这个延迟时间t是在程序当中配置的
- watermark时间戳是与窗口结束时间比较的,当watermark大于窗口结束时间时,意味着窗口结束,需要触发窗口计算
- 举个例子,某条数据的事件时间为2023:03:16 9:00:00,它的下一条数据的事件时间为2023:03:16 9:06:00,窗口设置为滚动窗口为5分钟,延迟时间t设置为2分钟,此时窗口结束时间为2023:03:16 9:00:00,水位线是2023:03:16 9:06:00 - 2min = 2023:03:16 9:04:00,watermark < window endtime,这两条数据应该在同一个窗口内,下面是具体的例子
二、案例分析
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.api.common.typeinfo.TypeInformation
import org.apache.flink.api.scala.createTypeInformation
import org.apache.flink.api.java.tuple._
import org.apache.flink.api.scala.ExecutionEnvironment
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.table.api.scala._
import org.apache.flink.table.api.{TableEnvironment, Types}
import org.apache.flink.table.sinks.CsvTableSink
import org.apache.flink.table.sources.CsvTableSource
import org.apache.flink.types.Row
case class User(id:Int,name:String,age:Int,timestamp:Long)
object SqlTest {
def main(args: Array[String]): Unit = {
val streamEnv = StreamExecutionEnvironment.getExecutionEnvironment
val tEnv = TableEnvironment.getTableEnvironment(streamEnv)
//指定时间类型为事件时间
streamEnv.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
val stream = streamEnv.fromElements(
User(1,"nie",22,1511658000),
User(2,"hu",20,1511658000),
User(2,"xiao",19,1511658000)
).assignAscendingTimestamps(_.timestamp * 1000L) //指定水位线
tEnv.registerDataStream("testTable",stream,'id, 'name,'age,'event_time.rowtime)
val result = tEnv.sqlQuery(
"select id,sum(age) from testTable group by TUMBLE(event_time,INTERVAL '5' MINUTE),id"
)
result.toRetractStream[Row].print()
streamEnv.execute("windowTest")
}
}
- 如上述代码所示,三条数据时间戳一样,也就是事件时间相同,水位线为自带的时间戳*1000L转成毫秒,滚动窗口时间间隔为5min,这时计算结果应该是3条数据都在一个窗口中计算,最终会产生2条数据
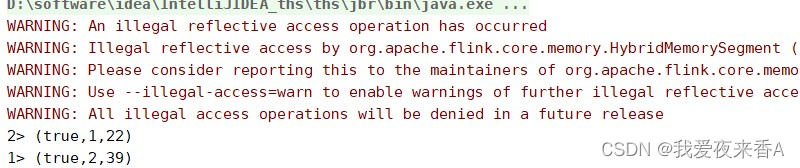
- 如下所示,把第三条时间戳增加300000,也就是增加了5分钟,下面三条数据的真实日期分别为2017-11-26 9:0:0、2017-11-26
9:0:0、2017-11-26 9:5:0
val stream = streamEnv.fromElements(
User(1,"nie",22,1511658000000L),
User(2,"hu",20,1511658000000L),
User(2,"xiao",19,1511658300000L)
).assignAscendingTimestamps(_.timestamp) //指定水位线
- 第三条数据正好晚了5分钟,此时前两条数据在一个窗口,第三条数据在一个窗口,最终应该产生三条数据,如下所示

我们直到可以利用水位线处理延迟情况,上面assignAscendingTimestamps方法针对的是数据有序,无法设定允许延迟时间,也就无法处理数据延迟的情况,下面介绍几种生成水位线的方式
三、如何生成水位线?
生成水位线分为两步:
- 第一步需要指定eventTime,可以通过StreamExecutionEnvironment的TimeCharacteristic指定,还需要在Flink程序中指定event
time时间戳在数据中的字段信息,在Flink程序中会通过指定字段抽取出对应的事件时间,该过程叫做Timestamps Assigning - 第二步就是创建相应的Watermarks,需要用户定义根据Timestamps计算出Watermarks的生成策略
- 目前Flink支持两种方式指定Timestamps和生成WaterMarks,一种方式在DataStream Source算子接口的Source Function定义,另一种方式是通过自定义Timestamp Assigner和Watermark Generator生成
(一)、在SourceFunction中直接定义Timestamps和Watermarks
(二)、自定义生成Timstamps和Watermarks
自定义生成分为两种:
- Periodic Watermarks:根据设定时间间隔周期性地生成Watermarks
- Punctuated Watermarks:根据接入数据的数量生成
1、Periodic Watermarks
- Periodic Watermark又分为两种:升序模式和固定时延间隔
1)、升序模式
- 会将数据中的Timestamp根据指定字段提取,并用当前的Timestamp作为最新的watermarks,适用于事件按顺序生成
- 调用DataStream API中的assignAscendingTimestamps来指定Timestamp字段
eg:
//指定时间类型为事件时间
streamEnv.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
val stream = streamEnv.fromElements(
User(1,"nie",22,1511658000),
User(2,"hu",20,1511658000),
User(2,"xiao",19,1511658300)
).assignAscendingTimestamps(_.timestamp * 1000L) //指定水位线
2)、使用固定时延间隔的Timestamp Assigner
- 通过设定固定的时间间隔来指定Watermark落后于Timestamp的区间长度,也就是最长容忍到多长时间内的数据到达系统
如下代码所示,通过创建BoundedOutOfOrdernessTimestampExtractor实现类来定义Timestamp Assigner,其中第一个参数Time.seconds(10)代表了最长的时延为10s,第二个为extractTimestamp抽取逻辑,选择样例类User的第三个元素作为Timestamps
eg:
case class User(id:Int,name:String,age:Int,timestamp:Long)
//指定时间类型为事件时间
streamEnv.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
val stream = streamEnv.fromElements(
User(1, "nie", 22, 1511658000),
User(2, "hu", 20, 1511658000),
User(2, "xiao", 19, 1511658000)
).assignTimestampsAndWatermarks(
new BoundedOutOfOrdernessTimestampExtractor[User](Time.seconds(10)) {
override def extractTimestamp(t: User): Long = t.timestamp
}
)
eg:
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.api.common.typeinfo.TypeInformation
import org.apache.flink.api.scala.createTypeInformation
import org.apache.flink.api.java.tuple._
import org.apache.flink.api.scala.ExecutionEnvironment
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.table.api.scala._
import org.apache.flink.table.api.{TableEnvironment, Types}
import org.apache.flink.table.sinks.CsvTableSink
import org.apache.flink.table.sources.CsvTableSource
import org.apache.flink.types.Row
case class User(id:Int,name:String,age:Int,timestamp:Long)
object SqlTest {
def main(args: Array[String]): Unit = {
val streamEnv = StreamExecutionEnvironment.getExecutionEnvironment
val tEnv = TableEnvironment.getTableEnvironment(streamEnv)
//指定时间类型为事件时间
streamEnv.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
val stream = streamEnv.fromElements(
User(1, "nie", 22, 1511658000000L),
User(2, "hu", 20, 1511658000000L),
User(2, "xiao", 19, 1511658003000L),
User(2, "feng", 31, 1511658002000L)
).assignTimestampsAndWatermarks(
new BoundedOutOfOrdernessTimestampExtractor[User](Time.seconds(1)) {
override def extractTimestamp(t: User): Long = t.timestamp
}
)
tEnv.registerDataStream("testTable",stream,'id, 'name,'age,'event_time.rowtime)
val result = tEnv.sqlQuery(
"select id,sum(age) from testTable group by TUMBLE(event_time,INTERVAL '2' SECOND),id"
)
result.toRetractStream[Row].print()
streamEnv.execute("windowTest")
}
}
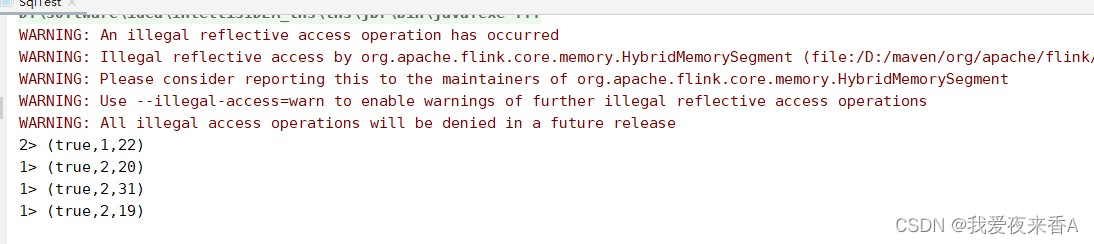
如上述代码所示,设置滚动窗口,窗口大小为2s,允许延迟时间为1s,四条数据的日期分别为2017-11-26 9:0:0、2017-11-26 9:0:0、2017-11-26 9:0:3、2017-11-26 9:0:2,可以看到第1、2、4条数据应该属于同一个窗口,只不过第四条数据延迟了,当第三条数据到达后,水位线应该为1511658003000L - 1000 = 1511658002000L,没有超过窗口结束时间1511658002000L,所以不触发窗口计算,第1、2、4条数据应该还是在一个窗口中计算的

这时候我们修改下代码,如下所示,修改了第三条数据的时间戳
val stream = streamEnv.fromElements(
User(1, "nie", 22, 1511658000000L),
User(2, "hu", 20, 1511658000000L),
User(2, "xiao", 19, 1511658004000L),
User(2, "feng", 31, 1511658002000L)
).assignTimestampsAndWatermarks(
new BoundedOutOfOrdernessTimestampExtractor[User](Time.seconds(1)) {
override def extractTimestamp(t: User): Long = t.timestamp
}
)
这时候当第三条数据到达的时候,水位线为1511658004000L - 1000 = 1511658003000L,超过了窗口结束时间1511658002000L,前两条数据触发计算,这时候第四条数据就没有加入计算
2、Punctuated Watermarks
- 上述两种是根据时间周期生成Periodic Watermark,用户也可以根据某些特殊条件生成Punctuated Watermarks
- 如判断数据流中某特殊元素的数量满足条件后生成Watermarks
- 生成Punctuated Watermarks的逻辑需要通过实现AssignerWithPunctuatedWatermarks接口定义,然后分别复写extractTimestamp方法和checkAndGetNextWatermark方法
eg:判断某个元素的当前状态,如果状态为0则触发生成Watermarks,如果状态不为0,则不触发生成Watermarks。
class PunctuatedAssigner extends AssignerWithPunctuatedWatermarks[(String,Long,Int)]{
//复写extractTimestamps方法,定义抽取Timestamp逻辑
override def extractTimestamp(element:(String,Long,Int),
previousElementTimestamp:Long):Long = {
element._2
}
//复写checkAndGetNextWatermark方法,定义Watermark生成逻辑
override def checkAndGetNextWatermark(lastElement:(String,Long,Int),
extractedTimestamp:Long):Watermark = {
//根据元素中第三位字段状态是否为0生成Watermark
if (lastElement._3 == 0) new Watermark(extractedTimestamp) else null
}
}

















 1287
1287











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











