






打开jmeter,添加后置处理器到接口请求后,在添加完成后将代码复制进入
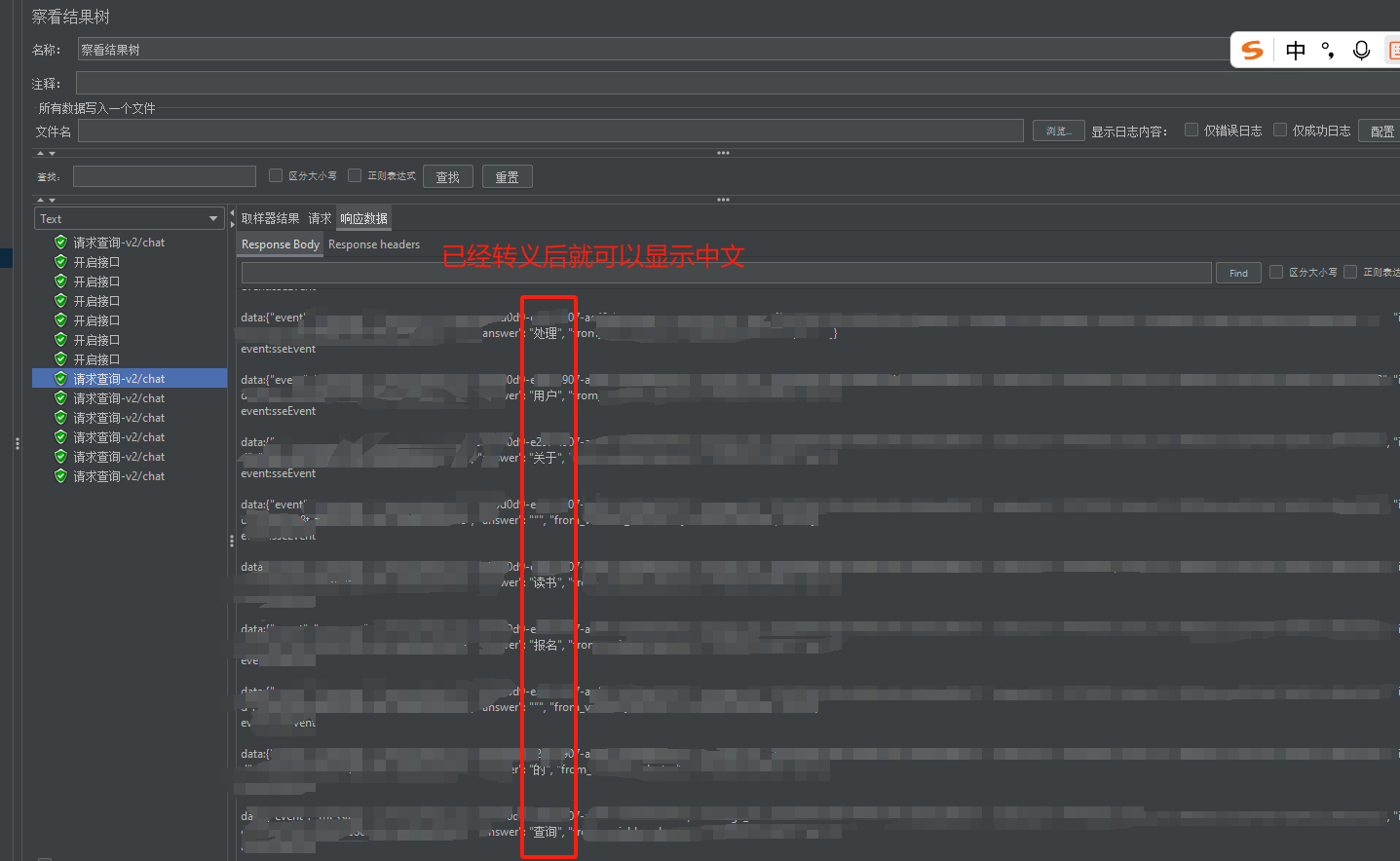
(注意:最后执行后需要到“察看结果树”里看,需要自行添加对应的监听器)
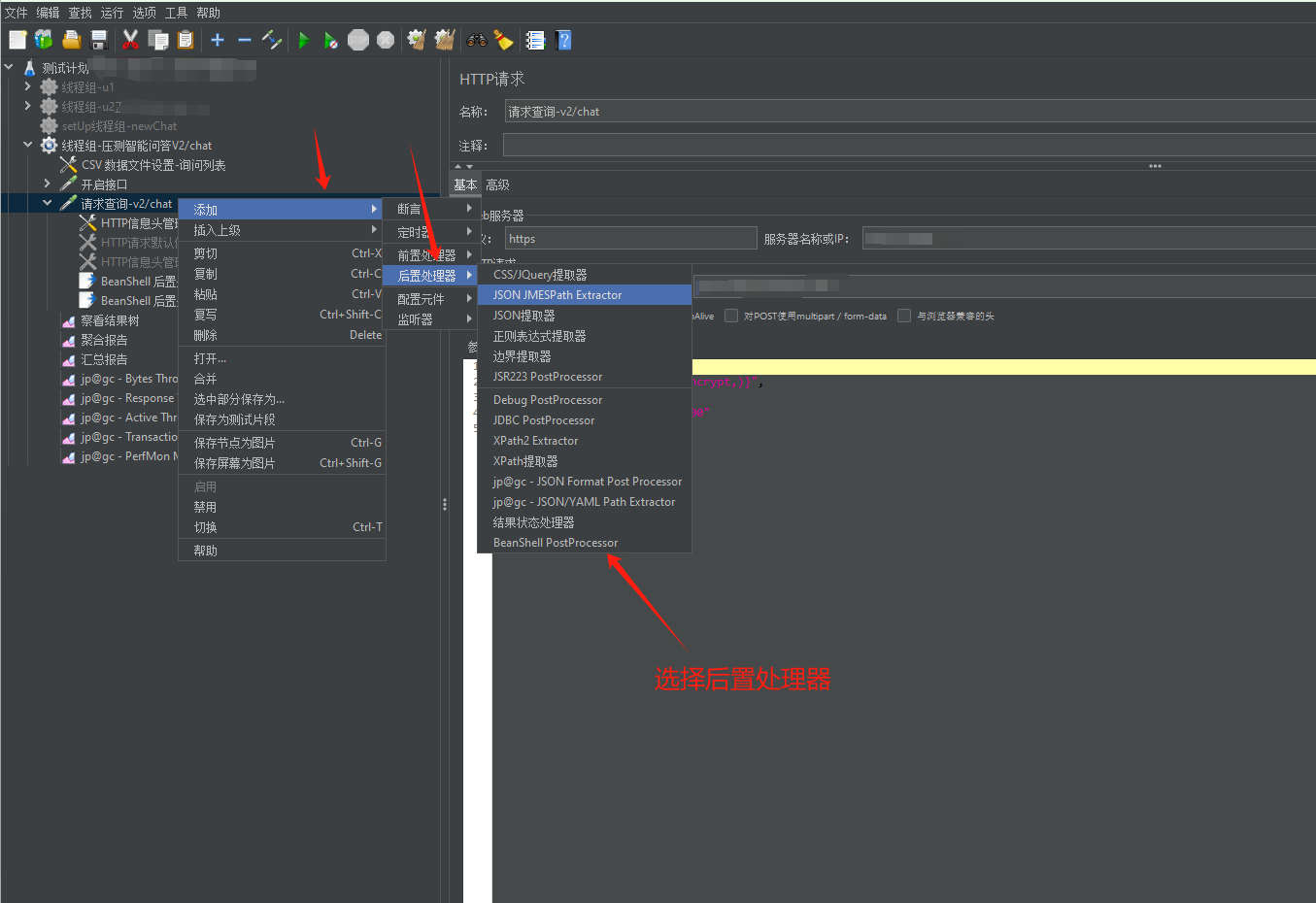
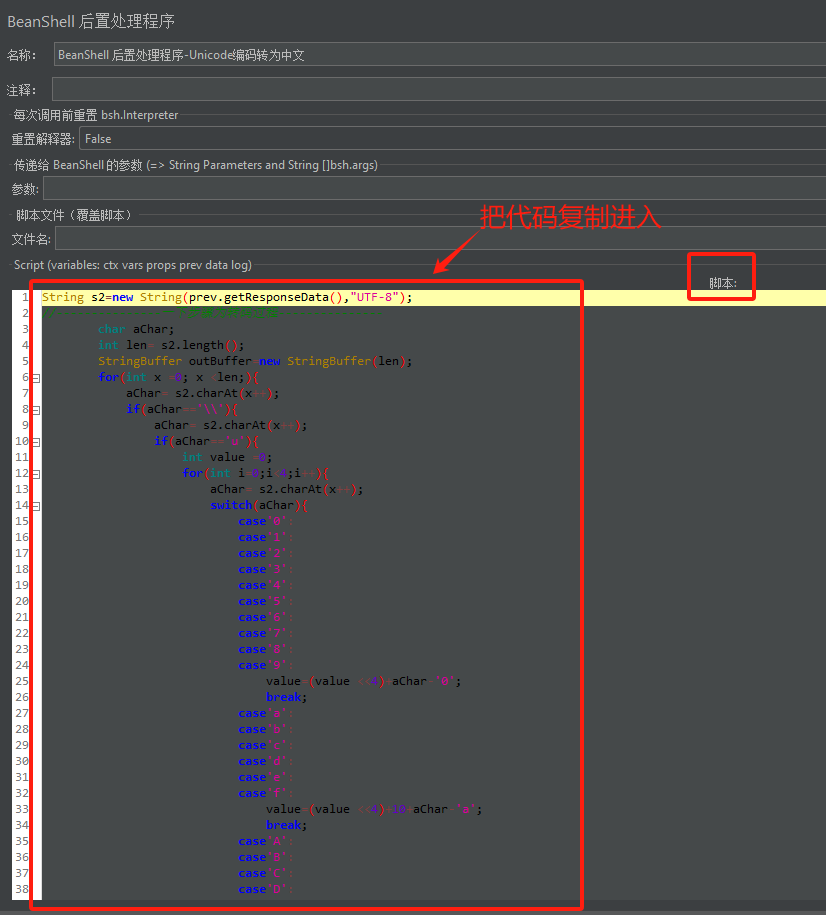
按如下添加代码进入上图位置:
//如下复制于链接(文章):https://blog.csdn.net/weixin_42675206/article/details/81064257
String s2=new String(prev.getResponseData(),"UTF-8");
//---------------一下步骤为转码过程---------------
char aChar;
int len= s2.length();
StringBuffer outBuffer=new StringBuffer(len);
for(int x =0; x <len;){
aChar= s2.charAt(x++);
if(aChar=='\\'){
aChar= s2.charAt(x++);
if(aChar=='u'){
int value =0;
for(int i=0;i<4;i++){
aChar= s2.charAt(x++);
switch(aChar){
case'0':
case'1':
case'2':
case'3':
case'4':
case'5':
case'6':
case'7':
case'8':
case'9':
value=(value <<4)+aChar-'0';
break;
case'a':
case'b':
case'c':
case'd':
case'e':
case'f':
value=(value <<4)+10+aChar-'a';
break;
case'A':
case'B':
case'C':
case'D':
case'E':
case'F':
value=(value <<4)+10+aChar-'A';
break;
default:
throw new IllegalArgumentException(
"Malformed \\uxxxx encoding.");}}
outBuffer.append((char) value);}else{
if(aChar=='t')
aChar='\t';
else if(aChar=='r')
aChar='\r';
else if(aChar=='n')
aChar='\n';
else if(aChar=='f')
aChar='\f';
outBuffer.append(aChar);}}else
outBuffer.append(aChar);}
//-----------------以上内容为转码过程---------------------------
//将转成中文的响应结果在查看结果树中显示
prev.setResponseData(outBuffer.toString());
————————————————

















 2720
2720

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









