







继承体系
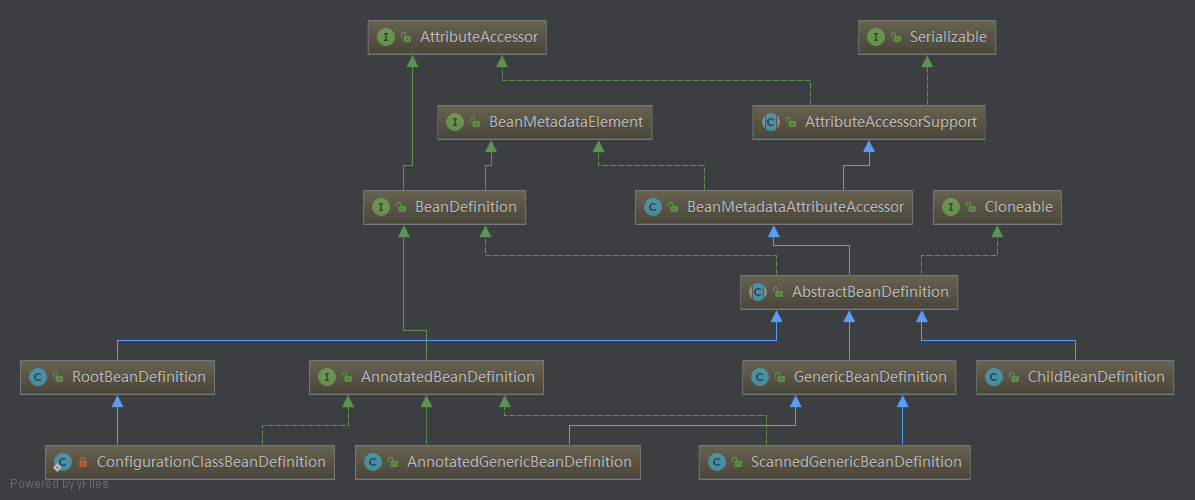
- BeanDefinition:定义了作为BeanDefinition的基本功能,主要由一系列的getter和setter方法组成。其继承的AttributeAccessor接口拥有get/set/removeAttribute方法(类似Map),所以BeanDefinition可以以键值对的方式任意扩展其属性,BeanMetadataElement接口的唯一方法getSource用来指明构建当前BeanDefinition的配置源。
- AnnotatedBeanDefinition: 提供了方便访问注解的方法。用@Component注解构建BeanDefinition时,可以根据其getMetadata()方法返回的AnnotationMetadata对象,方便地获取类的元数据及其注解属性;用@Bean注解构建BeanDefinition时,可以根据其getFactoryMethodMetadata()方法返回的MethodMetadata对象,方便地获取方法元数据及其注解属性,也可以用如同@Component注解构建BeanDefinition的方式获取类的元数据及其注解属性。AnnotationMetadata与MethodMetadata都是AnnotatedTypeMetadata的子接口,该接口可以方便地访问注解的属性值。与Java原生注解不同,Spring的注解可以通过元注解来标识其他注解,从而构建出父子关系,Spring的子注解是能够被当做父注解处理的。
- AbstractBeanDefinition:除了实现BeanDefinition的基本功能外,还做了一定的功能扩展,主要由代表各种意义的成员变量及其getter和setter组成。实际使用到的各种BeanDefinition基本上都是以AbstractBeanDefinition作为基类进行扩展的。
- GenericBeanDefinition:通过XML配置的bean一般会被直接解析为此类BeanDefinition,与AbstractBeanDefinition相比多了一个parent属性。
- ScannedGenericBeanDefinition:通过包扫描的方式扫描被 @Component(包括用@Component作为元注解的注解,如@Service、@Controller、@Configuration等)标记的类会被解析为此类BeanDefinition(不使用索引时)。
- ConfigurationClassBeanDefinition:以 @Bean标记的方法会被解析为此类BeanDefinition。
- AnnotatedGenericBeanDefinition:以AnnotatedBeanDefinitionReader.register(Class<?>…componentClasses) 方式直接将类解析为BeanDefinition进行注册时,这些类会被解析为此类BeanDefinition;在包扫描时,如果是通过索引进行的注册,那么也是使用此类BeanDefinition(很多博客认为被@Configuration标记的类会被解析为此类BeanDefinition,经过本座验证,此种说法纯属扯淡(至少在5.x版本后这种说法不成立))。
- RootBeanDefinition:不存在parent的BeanDefinition。在早期只能通过XML方式配置bean时,带有parent属性的bean会被解析为ChildBeanDefinition,不带parent属性的bean会被解析为RootBeanDefinition,但现在它们都已经被GenericBeanDefinition所取代,ChildBeanDefinition已经不再被使用,而RootBeanDefinition通常只作为MergedBeanDefinition使用。AbstractBeanFactory的getMergedBeanDefinition(…)方法会根据继承关系,将指定ID的BeanDefinition与其祖先BeanDefinition合并得到一个最终等效的MergedBeanDefinition,而这个MergedBeanDefinition不会再有parent,因此该方法返回的是一个RootBeanDefinition(或者定义一个继承自RootBeanDefinition的子类MergedBeanDefinition来作为返回类型更好,但实际上Spring并没有定义MergedBeanDefinition类,而是直接使用了RootBeanDefinition)。
创建BeanDefinition
对于各种原始材料,需要相应的解析器将其解析为BeanDefinition,从而以标准的形式提供给容器使用,BeanDefinitionReader就充当着解析器的角色。
BeanDefinitionReader拥有直接的虚拟实现类AbstractBeanDefinitionReader,而AbstractBeanDefinitionReader又派生出两个能实体化的子类XmlBeanDefinitionReader与PropertiesBeanDefinitionReader,它们分别能将XML与属性文件格式解析为BeanDefinition,其中使用最多的还是XmlBeanDefinitionReader。
AnnotatedBeanDefinitionReader与ClassPathBeanDefinitionScanner都不是BeanDefinitionReader的子类,但他们依然能够将相应的原材料解析为BeanDefinition,这两个类不属于spring-beans包,而是在spring-context包中的扩展。
AbstractBeanDefinitionReader
AbstractBeanDefinitionReader主要提供对外接口(如批量解析,决定是否对location进行正则解析),这些接口简单易用,但不会关心具体的解析方式,由其子类完成单个资源的具体解析。
在创建BeanDefinitionReader的时候,应该将其与一个BeanDefinitionRegistry关联,以便保存解析后的BeanDefinition。BeanDefinitionReader通过其loadBeanDefinitions方法来解析得到BeanDefinition并将其注册到BeanDefinitionRegistry。
public abstract class AbstractBeanDefinitionReader implements BeanDefinitionReader, EnvironmentCapable {
/**
* 对外提供的将资源解析为BeanDefinition的最为简单易用的方法
* @param locations 资源的字符串表示方式
* @return 本次解析成功注册的BeanDefinition的个数
*/
public int loadBeanDefinitions(String... locations) {
int count = 0;
for (String location: locations) {
count += loadBeanDefinitions(location, null);
}
return count;
}
/**
* 将location解析为资源格式,可能会进行正则解析
* @param location 资源的字符串表示方式
* @param actualResources 如果不为null,会将解析出的资源对象放入该集合中
* @return 本次解析并成功注册的BeanDefinition的个数
*/
public int loadBeanDefinitions(String location, @Nullable Set<Resource> actualResources) {
ResourceLoader resourceLoader = getResourceLoader();
// 根据资源加载器是否支持正则表达式,来决定是否对location进行正则解析,从而获取多个资源对象
Resource[] resources = resourceLoader instanceof ResourcePatternResolver ?
((ResourcePatternResolver) resourceLoader).getResources(location) : new Resource[] { resourceLoader.getResource(location) };
/*
1 if (actualResources != null) {
2 Collections.addAll(actualResources, resources);
3 }
4 return loadBeanDefinitions(resources);
* 以上注释部分的代码看起来更优雅,但Spring源码为什么不是这样的呢?
* 假设代码4的调用发生异常,那么本次方法调用是失败了,但却对actualResources造成了影响,这是不合理的
* 所以以方法参数的方式得到返回结果时,无论多少个这样的参数,都应该把改变这些参数的代码放在方法的最后阶段
*/
int count = loadBeanDefinitions(resources);
if (actualResources != null) {
Collections.addAll(actualResources, resources);
}
return count;
}
/**
* 针对不同的资源将委托给子类完成解析注册
* @param resources 资源对象
* @return 本次解析并成功注册的BeanDefinition的个数
*/
public int loadBeanDefinitions(Resource... resources) {
int count = 0;
for (Resource resource : resources) {
// 该方法由具体的子类针对不同的资源类型进行解析
count += loadBeanDefinitions(resource);
}
return count;
}
}
XmlBeanDefinitionReader
XmlBeanDefinitionReader能够将XML格式的资源解析为BeanDefinition。
XmlBeanDefinitionReader
将XML资源转换为Document对象,并创建一个BeanDefinitionDocumentReader来处理该Document对象。一个XML会被解析为一个Document对象,而其import的XML资源也会被解析为一个独立的Document对象。
public class XmlBeanDefinitionReader extends AbstractBeanDefinitionReader {
/**
* 主要用于解决了import循环加载问题
* @return 本次解析并成功注册的BeanDefinition的格式
*/
public int loadBeanDefinitions(EncodedResource encodedResource) {
// 解决循环import问题,因为import标签的解析会直接在当前线程调用该loadBeanDefinitions(EncodedResource encodedResource)方法
Set<EncodedResource> currentResources = this.resourcesCurrentlyBeingLoaded.get();
if (currentResources == null) {
currentResources = new HashSet<>(4);
this.resourcesCurrentlyBeingLoaded.set(currentResources);
}
// 如果currentResources集合中已经存在encodedResource则add方法返回false,表示处在着循环import
if (!currentResources.add(encodedResource)) {
throw new BeanDefinitionStoreException("Detected cyclic loading of " + encodedResource + " - check your import definitions!");
}
InputStream inputStream = encodedResource.getResource().getInputStream();
try {
InputSource inputSource = new InputSource(inputStream);
if (encodedResource.getEncoding() != null) {
inputSource.setEncoding(encodedResource.getEncoding());
}
// 用SAX方式将xml格式的inputSource解析为标准的Document对象,该过程回调了PluggableSchemaResolver.resolveEntity(...)来获取相应命名空间的验证文件(如.xsd、.dtd格式)
// 然后调用registerBeanDefinitions(Document doc, Resource resource)委托BeanDefinitionDocumentReader进行解析
return doLoadBeanDefinitions(inputSource, encodedResource.getResource());
} finally {
inputStream.close();
// 只有在向currentResources中添加和移除之间的代码进行了相同资源的加载才会出现循环import问题
currentResources.remove(encodedResource);
if (currentResources.isEmpty()) {
this.resourcesCurrentlyBeingLoaded.remove();
}
}
}
/**
* 创建BeanDefinitionDocumentReader对象并委托它解析Document
* @return 本次解析并成功注册的BeanDefinition的个数
*/
public int registerBeanDefinitions(Document doc, Resource resource) throws BeanDefinitionStoreException {
// BeanDefinitionDocumentReader通过BeanUtils.instantiateClass(this.documentReaderClass)创建
// 默认的this.documentReaderClass为DefaultBeanDefinitionDocumentReader.class
// 通过更改this.documentReaderClass成员可以指定自己定制的BeanDefinitionDocumentReader
BeanDefinitionDocumentReader documentReader = createBeanDefinitionDocumentReader();
int countBefore = getRegistry().getBeanDefinitionCount();
// 委托documentReader处理Document对象,其中ReaderContext提供了documentReader需要的对象,如BeanDefinitionRegistry对象
documentReader.registerBeanDefinitions(doc, createReaderContext(resource));
// 本次加载解析注册的BeanDefinition个数 = 加载解析后已注册的BeanDefinition个数 - 加载解析前已注册的BeanDefinition个数
return getRegistry().getBeanDefinitionCount() - countBefore;
}
}
BeanDefinitionDocumentReader
BeanDefinitionDocumentReader负责对Document进行处理,一个BeanDefinitionDocumentReader实例只负责解析一个Document对象。对于每一个具有root特性的Element(Document的根Element具有root特性,解析方式为直接调用doRegisterBeanDefinitions(…)的Element也具有root特性(实际上创建了一个子BeanDefinitionParserDelegate来处理该Element),默认只有<beans/>标签具有root特性),都会创建一个BeanDefinitionParserDelegate实例来对它及其内部标签进行解析。BeanDefinitionParserDelegate的父子关系可以用来解决具有root特性的Element的分层结构。
public class DefaultBeanDefinitionDocumentReader implements BeanDefinitionDocumentReader {
public void registerBeanDefinitions(Document doc, XmlReaderContext readerContext) {
this.readerContext = readerContext;
doRegisterBeanDefinitions(doc.getDocumentElement());
}
/**
* 每一个具有root特性的元素(每一个嵌套的<beans>元素都具有root特性)都会对应一个BeanDefinitionParserDelegate负责解析
* @param root 并不一定是xml资源的根元素
*/
protected void doRegisterBeanDefinitions(Element root) {
// delegate是最终用来解析各标签的代理
// 对于一个xml资源的根元素(包括被import进的xml资源的根元素),调用该方法时,当前BeanDefinitionReader肯定是刚创建,所以新建的delegate不会有parent
// 当root不是xml资源的根元素时(最常见的就是<beans>标签中内嵌的<beans>标签,对内嵌<beans>标签的处理就是直接调用了doRegisterBeanDefinitions(Element root)),解析上一层root的delegate会作为parent
// 创建delegate时会继承parent中的default-**属性
BeanDefinitionParserDelegate parent = this.delegate;
this.delegate = createDelegate(getReaderContext(), root, parent);
// 默认只有<beans/>标签可作为root元素,如果root元素带有非空的profile属性,只有环境激活了该属性才会继续解析子标签
if (this.delegate.isDefaultNamespace(root)) {
String profileSpec = root.getAttribute(PROFILE_ATTRIBUTE);
if (StringUtils.hasText(profileSpec)) {
String[] specifiedProfiles = StringUtils.tokenizeToStringArray(
profileSpec, BeanDefinitionParserDelegate.MULTI_VALUE_ATTRIBUTE_DELIMITERS);
if (!getReaderContext().getEnvironment().acceptsProfiles(specifiedProfiles)) {
return;
}
}
}
// preProcessXml(root)与postProcessXml(root)都是空函数,什么事都不做,主要提供给子类在Document解析前后进行功能扩展
// 前面说过可以通过指定XmlBeanDefinitionReader的documentReaderClass成员来定制自己的BeanDefinitionDocumentReader
// 自定义documentReaderClass最简单的方式就是继承DefaultBeanDefinitionDocumentReader,重写preProcessXml(root)与postProcessXml(root)
preProcessXml(root);
parseBeanDefinitions(root, this.delegate); // 真正的解析函数
postProcessXml(root);
// 当一层具有root特性的标签跳出时需要将其parent上调一层
this.delegate = parent;
}
/**
* 因为可以定制自己的BeanDefinitionDocumentReader,所以可以继承BeanDefinitionDocumentReader并重写该方法来定制自己的BeanDefinitionParserDelegate
*/
protected BeanDefinitionParserDelegate createDelegate(
XmlReaderContext readerContext, Element root, @Nullable BeanDefinitionParserDelegate parentDelegate) {
// 对于每一个具有root特性的标签都需要一个新的delegate对象来解析,而该标签的属性就用来初始化delegate
// 每个delegate都包含一个DocumentDefaultsDefinition对象(default成员),该对象用于存放默认值
// 在创建delegate的时候会根据<beans/>标签的default-**属性以及其父delegate的default来初始化当前delegate的default(default-**属性为默认值或空时使用父delegate的default的相应值来初始化)
BeanDefinitionParserDelegate delegate = new BeanDefinitionParserDelegate(readerContext);
delegate.initDefaults(root, parentDelegate);
return delegate;
}
protected void parseBeanDefinitions(Element root, BeanDefinitionParserDelegate delegate) {
if (delegate.isDefaultNamespace(root)) { // 默认的root标签只有<beans/>
NodeList nl = root.getChildNodes();
for (int i = 0; i < nl.getLength(); i++) {
Node node = nl.item(i);
if (node instanceof Element) {
Element ele = (Element) node;
// 判断一个元素是否是默认元素,主要看该元素的命名空间
// 只有命名空间为空或者http://www.springframework.org/schema/beans的元素才是默认元素
if (delegate.isDefaultNamespace(ele)) {
parseDefaultElement(ele, delegate); // 默认标签的处理方式
} else {
delegate.parseCustomElement(ele); // 自定义的标签委托delegate处理
}
}
}
} else { // 如果是自定义root标签,也委托delegate处理
delegate.parseCustomElement(root);
}
}
/**
* 默认标签的处理,默认命名空间下只有这些元素
*/
private void parseDefaultElement(Element ele, BeanDefinitionParserDelegate delegate) {
// 不同默认标签做不同处理,除了beans元素以外,其他元素处理完成后都会发布相应的事件通知
if (delegate.nodeNameEquals(ele, IMPORT_ELEMENT)) { // "import"
// 调用XmlBeanDefinitionReader.loadBeanDefinitions(...)加载xml资源
// import的xml文件的根元素并不会继承当前xml文件根元素的属性
importBeanDefinitionResource(ele);
} else if (delegate.nodeNameEquals(ele, ALIAS_ELEMENT)) { // "alias"
// 调用AliasRegistry.registerAlias(name, alias)进行别名注册
// BeanDefinitionRegistry本身继承自AliasRegistry,所以BeanDefinitionRegistry本身就可以作为别名注册中心
processAliasRegistration(ele);
} else if (delegate.nodeNameEquals(ele, BEAN_ELEMENT)) { // "bean"
// 先委托delegate的parseBeanDefinitionElement(ele)解析得到一个BeanDefinitionHolder
// 然后通过BeanDefinitionHolder进行BeanDefinition与别名的注册(BeanDefinitionHolder包含了解析后的BeanDefinition以及别名信息)
// delegate解析主要是就是创建一个BeanDefinition实例,然后用标签属性值对它进行初始化
processBeanDefinition(ele, delegate);
} else if (delegate.nodeNameEquals(ele, NESTED_BEANS_ELEMENT)) { // "beans"
// 直接当作具有root特性的元素迭代处理
doRegisterBeanDefinitions(ele);
}
}
protected void processBeanDefinition(Element ele, BeanDefinitionParserDelegate delegate) {
// 委托delegate的parseBeanDefinitionElement(...)进行默认解析
BeanDefinitionHolder bdHolder = delegate.parseBeanDefinitionElement(ele);
if (bdHolder != null) {
// 采用装饰模式对BeanDefinition做进一步处理(解析出标签的属性和子标签并分别委托给delegate.decorateIfRequired(...)处理)
bdHolder = delegate.decorateBeanDefinitionIfRequired(ele, bdHolder);
// 注册BeanDefinition
BeanDefinitionReaderUtils.registerBeanDefinition(bdHolder, getReaderContext().getRegistry());
// 发布通知
getReaderContext().fireComponentRegistered(new BeanComponentDefinition(bdHolder));
}
}
}
BeanDefinitionParserDelegate
BeanDefinitionParserDelegate用于解析标签,默默无闻地干最脏最累的活。它不仅用于默认标签的解析,还定义了自定义标签的框架。
bean标签默认处理
public class BeanDefinitionParserDelegate {
public BeanDefinitionHolder parseBeanDefinitionElement(Element ele, @Nullable BeanDefinition containingBean) {
// 解析id与name属性,name可以是由','或';'分割的多个值
// 当存在id时,以id为ID,name为别名,不存在id且存在name时,以name的第一个值为ID,其他值为别名
String id = ele.getAttribute(ID_ATTRIBUTE);
String nameAttr = ele.getAttribute(NAME_ATTRIBUTE);
List<String> aliases = new ArrayList<>();
if (StringUtils.hasLength(nameAttr)) {
String[] nameArr = StringUtils.tokenizeToStringArray(nameAttr, MULTI_VALUE_ATTRIBUTE_DELIMITERS);
aliases.addAll(Arrays.asList(nameArr));
}
String beanName = id;
if (!StringUtils.hasText(beanName) && !aliases.isEmpty()) {
beanName = aliases.remove(0);
}
// 检查ID与别名是否用过
if (containingBean == null) {
checkNameUniqueness(beanName, aliases, ele);
}
// 对bean标签的其他属性及子标签进行解析
AbstractBeanDefinition beanDefinition = parseBeanDefinitionElement(ele, beanName, containingBean);
if (beanDefinition != null) {
// 如果没有beanName,那么生成beanName,可能还会生成别名
if (!StringUtils.hasText(beanName)) {
if (containingBean != null) {
// 依次取BeanDefinition的beanClassName、parentName$child、factoryBeanName$created作为基本名
// 最后一个参数为true表示内部<bean/>标签,会在基本名后面加上 # + Integer.toHexString(System.identityHashCode(beanDefinition))
// 最后再加上 # + 确保beanName唯一的一个数字
beanName = BeanDefinitionReaderUtils.generateBeanName(
beanDefinition, this.readerContext.getRegistry(), true);
} else {
// BeanDefinitionReaderUtils.generateBeanName(beanDefinition, this.readerContext.getRegistry(), false)
beanName = this.readerContext.generateBeanName(beanDefinition);
String beanClassName = beanDefinition.getBeanClassName();
// 如果beanClassName没有作为其他BeanDefinition的ID或别名,将其作为当前BeanDefinition的别名
if (beanClassName != null &&
beanName.startsWith(beanClassName) && beanName.length() > beanClassName.length() &&
!this.readerContext.getRegistry().isBeanNameInUse(beanClassName)) {
aliases.add(beanClassName);
}
}
}
String[] aliasesArray = StringUtils.toStringArray(aliases);
return new BeanDefinitionHolder(beanDefinition, beanName, aliasesArray);
}
return null;
}
public AbstractBeanDefinition parseBeanDefinitionElement(Element ele, String beanName, BeanDefinition containingBean) {
this.parseState.push(new BeanEntry(beanName));
String className = null;
if (ele.hasAttribute(CLASS_ATTRIBUTE)) {
className = ele.getAttribute(CLASS_ATTRIBUTE).trim();
}
String parent = null;
if (ele.hasAttribute(PARENT_ATTRIBUTE)) {
parent = ele.getAttribute(PARENT_ATTRIBUTE);
}
try {
// 以标签的class属性作为BeanDefinition的beanClass属性、以标签的parent属性作为BeanDefinition的parentName属性
AbstractBeanDefinition bd = createBeanDefinition(className, parent);
// 将属性值解析出来保存到BeanDefinition中
parseBeanDefinitionAttributes(ele, beanName, containingBean, bd);
// 解析各个子标签并将解析结果保存到BeanDefinition中
bd.setDescription(DomUtils.getChildElementValueByTagName(ele, DESCRIPTION_ELEMENT));
parseMetaElements(ele, bd);
parseLookupOverrideSubElements(ele, bd.getMethodOverrides());
parseReplacedMethodSubElements(ele, bd.getMethodOverrides());
parseConstructorArgElements(ele, bd);
parsePropertyElements(ele, bd);
parseQualifierElements(ele, bd);
bd.setResource(this.readerContext.getResource());
bd.setSource(extractSource(ele));
return bd;
} finally {
this.parseState.pop();
}
return null;
}
}
自定义标签处理过程
XML校验原理
XML的根标签的xsi:schemaLocation属性的值由多个键值对组成,格式为"key1 value1 key2 value2 …",其中key是命名空间,value是一个标识systemId(一般习惯namespace + xxx.xsd),spring定义了如何根据systemId获取命名空间的定义文件(如dtd、xsd等)。
/**
* SAX解析过程中会根据命名空间获取到systemId,所以Spring只扩展了如何根据systemId获取定义文件的位置
*/
public class PluggableSchemaResolver implements EntityResolver {
public InputSource resolveEntity(@Nullable String publicId, @Nullable String systemId) throws IOException {
if (systemId != null) {
String resourceLocation = getSchemaMappings().get(systemId);
if (resourceLocation == null && systemId.startsWith("https:")) {
resourceLocation = getSchemaMappings().get("http:" + systemId.substring(6));
}
if (resourceLocation != null) {
Resource resource = new ClassPathResource(resourceLocation, this.classLoader);
InputSource source = new InputSource(resource.getInputStream());
source.setPublicId(publicId);
source.setSystemId(systemId);
return source;
}
}
return null;
}
private Map<String, String> getSchemaMappings() {
Map<String, String> schemaMappings = this.schemaMappings;
// 如果schemaMappings没有初始化,这里进行初始化,这里用了双重校验来解决多线程只初始化一次
if (schemaMappings == null) {
synchronized (this) {
schemaMappings = this.schemaMappings;
if (schemaMappings == null) {
// this.schemaMappingsLocation是配置的属性文件,默认为META-INFO/spring.schemas
// 属性文件格式为systemId=xml定义文件位置
Properties mappings = PropertiesLoaderUtils.loadAllProperties(this.schemaMappingsLocation, this.classLoader);
schemaMappings = new ConcurrentHashMap<>(mappings.size());
CollectionUtils.mergePropertiesIntoMap(mappings, schemaMappings);
this.schemaMappings = schemaMappings;
}
}
}
return schemaMappings;
}
}
XML解析过程
一组具有特定功能的标签被放在一个相同的命名空间中,由与该命名空间绑定的处理器NamespaceHandler进行处理。NameSpaceHandler的parse(…)与decorate(…)方法可用于解析该命名空间下的子标签,parse(…)用于直接解析标签得到独立的BeanDefinition(如解析<beans/>下的自定义标签),而decorate(…)解析标签对已存在的BeanDefinition进行修饰(如解析<bean/>下的自定义标签)。
/**
* 用于解析自定义标签
*/
public class BeanDefinitionParserDelegate {
public BeanDefinition parseCustomElement(Element ele, @Nullable BeanDefinition containingBd) {
// 获取元素的命名空间
String namespaceUri = getNamespaceURI(ele);
if (namespaceUri == null) {
return null;
}
// 根据命名空间获取相应的处理器
NamespaceHandler handler = this.readerContext.getNamespaceHandlerResolver().resolve(namespaceUri);
if (handler == null) {
return null;
}
// 命名空间处理器会根据元素标签找到相应的解析器来进行解析
return handler.parse(ele, new ParserContext(this.readerContext, this, containingBd));
}
public BeanDefinitionHolder decorateIfRequired(Node node, BeanDefinitionHolder originalDef, BeanDefinition containingBd) {
String namespaceUri = getNamespaceURI(node);
// 处理非默认命名空间的属性与标签
if (namespaceUri != null && !isDefaultNamespace(namespaceUri)) {
NamespaceHandler handler = this.readerContext.getNamespaceHandlerResolver().resolve(namespaceUri);
if (handler != null) {
// 命名空间处理器会根据元素标签找到相应的装饰器来进行解析
BeanDefinitionHolder decorated = handler.decorate(node, originalDef, new ParserContext(this.readerContext, this, containingBd));
if (decorated != null) {
return decorated;
}
}
}
return originalDef;
}
}
/**
* 每一个XML的命名空间都对应一个NamespaceHandler的实现类,而实际上都是NamespaceHandlerSupport的子类
* NamespaceHandlerSupport主要解决标签与parser以及decorator的对应关系,并能委托给相应parser或decorator进行标签解析
*/
public abstract class NamespaceHandlerSupport implements NamespaceHandler {
public BeanDefinition parse(Element element, ParserContext parserContext) {
// 从注册的解析器中找到与指定元素关联的解析器
BeanDefinitionParser parser = findParserForElement(element, parserContext);
// BeanDefinitionParser的parse方法负责标签的最终解析
return (parser != null ? parser.parse(element, parserContext) : null);
}
public BeanDefinitionHolder decorate(Node node, BeanDefinitionHolder definition, ParserContext parserContext) {
// 从注册的装饰器中找到与指定节点关联的装饰器,NamespaceHandlerSupport有两个装饰器注册中心,分别注册属性的装饰器与子元素的装饰器
// 此方法会根据node的类型从相应的注册中心获取装饰器
BeanDefinitionDecorator decorator = findDecoratorForNode(node, parserContext);
// BeanDefinitionDecorator的decorate方法负责最终的装饰
return (decorator != null ? decorator.decorate(node, definition, parserContext) : null);
}
// 将标签名与其对应的解析器绑定
protected final void registerBeanDefinitionParser(String elementName, BeanDefinitionParser parser) {
this.parsers.put(elementName, parser);
}
// 将子标签名与其对应的装饰器绑定
protected final void registerBeanDefinitionDecorator(String elementName, BeanDefinitionDecorator dec) {
this.decorators.put(elementName, dec);
}
// 将属性名与其对应的装饰器绑定
protected final void registerBeanDefinitionDecoratorForAttribute(String attrName, BeanDefinitionDecorator dec) {
this.attributeDecorators.put(attrName, dec);
}
/**
* 一般由子类实现,通常多次调用registerBeanDefinitionParser(...)与registerBeanDefinitionDecorator(...)方法
*/
void init();
}
/**
* 主要用于解决命名空间与NamespaceHandler的映射关系
*/
public class DefaultNamespaceHandlerResolver implements NamespaceHandlerResolver {
public NamespaceHandler resolve(String namespaceUri) {
// 获取所有命名空间和处理器的对应关系
Map<String, Object> handlerMappings = getHandlerMappings();
// 处理器最开始是类全名,只有在第一次使用之后才会被解析为对象
// 这是一种延后处理机制,节约内存和CPU资源,如果某个命名空间一直未被使用,将永远不会创建相应的处理器实例
Object handlerOrClassName = handlerMappings.get(namespaceUri);
if (handlerOrClassName == null) {
return null;
} else if (handlerOrClassName instanceof NamespaceHandler) { // 已经创建了处理器实例
return (NamespaceHandler) handlerOrClassName;
} else { // 未创建处理器实例进行创建并初始化,同时进行缓存
String className = (String) handlerOrClassName;
Class<?> handlerClass = ClassUtils.forName(className, this.classLoader);
// handlerClass必须是NamespaceHandler的实现类
if (!NamespaceHandler.class.isAssignableFrom(handlerClass)) {
throw new FatalBeanException("...");
}
NamespaceHandler namespaceHandler = (NamespaceHandler) BeanUtils.instantiateClass(handlerClass);
namespaceHandler.init(); // 初始化,通常用来进行标签解析器的注册
handlerMappings.put(namespaceUri, namespaceHandler); // 表示已经创建了处理器实例
return namespaceHandler;
}
}
private Map<String, Object> getHandlerMappings() {
Map<String, Object> handlerMappings = this.handlerMappings;
// 如果handlerMappings没有初始化,这里进行初始化,这里用了双重校验来解决多线程只初始化一次
if (handlerMappings == null) {
synchronized (this) {
handlerMappings = this.handlerMappings;
if (handlerMappings == null) {
// this.handlerMappingsLocation是配置的属性文件,默认为META-INFO/spring.handlers
// 属性文件格式为命名空间名=命名空间处理器的全类名
Properties mappings = PropertiesLoaderUtils.loadAllProperties(this.handlerMappingsLocation, this.classLoader);
handlerMappings = new ConcurrentHashMap<>(mappings.size());
CollectionUtils.mergePropertiesIntoMap(mappings, handlerMappings);
this.handlerMappings = handlerMappings;
}
}
}
return handlerMappings;
}
}
PropertiesBeanDefinitionReader
负责根据properties文件解析得到BeanDefinition,不常用,源码略。
根据注解构建BeanDefinition
工具介绍
AnnotationConfigUtils
public abstract class AnnotationConfigUtils {
/**
* 扩展注解功能
* 这里并没有进行PostProcessor的注册,所以基本BeanFactory不会进行扩展处理,但ApplicationContext会自动进行PostProcessor注册
* @return 本次注册的所有BeanDefinition的集合
*/
public static Set<BeanDefinitionHolder> registerAnnotationConfigProcessors(BeanDefinitionRegistry registry, Object source) {
DefaultListableBeanFactory beanFactory = unwrapDefaultListableBeanFactory(registry);
if (beanFactory != null) {
// Comparator -> OrderComparator -> AnnotationAwareOrderComparator
// beanFactory的dependencyComparator属性为Comparator类型,但实例一般是AnnotationAwareOrderComparator类型
// AnnotationAwareOrderComparator继承自OrderComparator,主要用于获取BeanDefinition的Order与Priority值
// OrderComparator的getOrder(...)实际上就是根据类是否继承自Ordered,调用其getOrder()来获取Order值
// OrderComparator的getPriority(...)返回null,表示它不知道怎么处理,只能由其子类去处理
// AnnotationAwareOrderComparator的getPriority(...)根据@Priority注解来获取值
// AnnotationAwareOrderComparator的getOrder(...)先调用父类的getOrder(...),如果无法获取到Order值,先取@Order注解值再取@Priority值
if (!(beanFactory.getDependencyComparator() instanceof AnnotationAwareOrderComparator)) {
beanFactory.setDependencyComparator(AnnotationAwareOrderComparator.INSTANCE);
}
// AutowireCandidateResolver -> SimpleAutowireCandidateResolver-> GenericTypeAwareAutowireCandidateResolver
// -> QualifierAnnotationAutowireCandidateResolver-> ContextAnnotationAutowireCandidateResolver
// 主要用于解决依赖注入过程中候选问题,如确定一个BeanDefinition是否能够作为候选
if (!(beanFactory.getAutowireCandidateResolver() instanceof ContextAnnotationAutowireCandidateResolver)) {
beanFactory.setAutowireCandidateResolver(new ContextAnnotationAutowireCandidateResolver());
}
}
Set<BeanDefinitionHolder> beanDefs = new LinkedHashSet<>(8);
// ConfigurationClassPostProcessor实现了BeanFactoryPostProcessor接口,用来完善BeanFactory
// 通过解析@Configuration、@ComponentScan、@ComponentScans、@Import等注解来创建并注册BeanDefinition
if (!registry.containsBeanDefinition(CONFIGURATION_ANNOTATION_PROCESSOR_BEAN_NAME)) {
RootBeanDefinition def = new RootBeanDefinition(ConfigurationClassPostProcessor.class);
def.setSource(source);
beanDefs.add(registerPostProcessor(registry, def, CONFIGURATION_ANNOTATION_PROCESSOR_BEAN_NAME));
}
// AutowiredAnnotationBeanPostProcessor用来处理@Autowired依赖注入以及@Value赋值问题
if (!registry.containsBeanDefinition(AUTOWIRED_ANNOTATION_PROCESSOR_BEAN_NAME)) {
RootBeanDefinition def = new RootBeanDefinition(AutowiredAnnotationBeanPostProcessor.class);
def.setSource(source);
beanDefs.add(registerPostProcessor(registry, def, AUTOWIRED_ANNOTATION_PROCESSOR_BEAN_NAME));
}
// 如果支持JSR-250,那么就注册CommonAnnotationBeanPostProcessor
// CommonAnnotationBeanPostProcessor用来解决JSR-250标准的@Resource、@PostConstruct和@PreDestroy注解
if (jsr250Present && !registry.containsBeanDefinition(COMMON_ANNOTATION_PROCESSOR_BEAN_NAME)) {
RootBeanDefinition def = new RootBeanDefinition(CommonAnnotationBeanPostProcessor.class);
def.setSource(source);
beanDefs.add(registerPostProcessor(registry, def, COMMON_ANNOTATION_PROCESSOR_BEAN_NAME));
}
// 如果支持JPA,那么就注册org.springframework.orm.jpa.support.PersistenceAnnotationBeanPostProcessor的BeanDefinition
// org.springframework.orm.jpa.support.PersistenceAnnotationBeanPostProcessor用来处理JPA相关注解
if (jpaPresent && !registry.containsBeanDefinition(PERSISTENCE_ANNOTATION_PROCESSOR_BEAN_NAME)) {
RootBeanDefinition def = new RootBeanDefinition();
def.setBeanClass(ClassUtils.forName(PERSISTENCE_ANNOTATION_PROCESSOR_CLASS_NAME, AnnotationConfigUtils.class.getClassLoader()));
def.setSource(source);
beanDefs.add(registerPostProcessor(registry, def, PERSISTENCE_ANNOTATION_PROCESSOR_BEAN_NAME));
}
// EventListenerMethodProcessor实现了BeanFactoryPostProcessor接口,用来完善BeanFactory
// 与DefaultEventListenerFactory一起处理事件发布处理
if (!registry.containsBeanDefinition(EVENT_LISTENER_PROCESSOR_BEAN_NAME)) {
RootBeanDefinition def = new RootBeanDefinition(EventListenerMethodProcessor.class);
def.setSource(source);
beanDefs.add(registerPostProcessor(registry, def, EVENT_LISTENER_PROCESSOR_BEAN_NAME));
}
if (!registry.containsBeanDefinition(EVENT_LISTENER_FACTORY_BEAN_NAME)) {
RootBeanDefinition def = new RootBeanDefinition(DefaultEventListenerFactory.class);
def.setSource(source);
beanDefs.add(registerPostProcessor(registry, def, EVENT_LISTENER_FACTORY_BEAN_NAME));
}
return beanDefs;
}
// 根据注解设置abd的属性
public static void processCommonDefinitionAnnotations(AnnotatedBeanDefinition abd) {
processCommonDefinitionAnnotations(abd, abd.getMetadata());
}
// 解析类上的@Lazy、@Primary、@DependsOn、@Role、@Description注解(包括被它们标记的注解),并根据其值设置abd的相应属性
static void processCommonDefinitionAnnotations(AnnotatedBeanDefinition abd, AnnotatedTypeMetadata metadata) {
// attributesFor(...)可以获取构建abd的类上指定注解实例(包括被该注解标记的注解)的所有属性与值
// 如果类被@Lazy注解,用其值来初始化abd的lazyInit属性
AnnotationAttributes lazy = attributesFor(metadata, Lazy.class);
if (lazy != null) {
abd.setLazyInit(lazy.getBoolean("value"));
} else if (abd.getMetadata() != metadata) {
lazy = attributesFor(abd.getMetadata(), Lazy.class);
if (lazy != null) {
abd.setLazyInit(lazy.getBoolean("value"));
}
}
// 如果类被@Primary注解,那么将abd的primary属性设为true
if (metadata.isAnnotated(Primary.class.getName())) {
abd.setPrimary(true);
}
// 如果类被@DependsOn注解,用其值来初始化abd的dependsOn属性
AnnotationAttributes dependsOn = attributesFor(metadata, DependsOn.class);
if (dependsOn != null) {
abd.setDependsOn(dependsOn.getStringArray("value"));
}
// 如果类被@Role注解,用其值来初始化abd的role属性
AnnotationAttributes role = attributesFor(metadata, Role.class);
if (role != null) {
abd.setRole(role.getNumber("value").intValue());
}
// 如果类被@Description注解,用其值来初始化abd的description属性
AnnotationAttributes description = attributesFor(metadata, Description.class);
if (description != null) {
abd.setDescription(description.getString("value"));
}
}
}
ScopedProxyUtils
public abstract class ScopedProxyUtils {
/**
* 创建一个新的BeanDefifinition作为原BeanDefinition的代理,新的BeanDefinition几乎保留了原BeanDefinition的所有属性
*/
public static BeanDefinitionHolder createScopedProxy(BeanDefinitionHolder definition,
BeanDefinitionRegistry registry, boolean proxyTargetClass) {
// 将代理BeanDefinition的beanName设置为目标BeanDefinition的beanName
// 将目标BeanDefinition的beanName改为scopedTarget. + originalBeanName
// 这样通过beanName来获取BeanDefinition实际上会得到代理BeanDefinition
String originalBeanName = definition.getBeanName();
BeanDefinition targetDefinition = definition.getBeanDefinition();
String targetBeanName = getTargetBeanName(originalBeanName);
// ScopedProxyFactoryBean实现了BeanFactoryAware接口,其setBeanFactory(BeanFactory beanFactory)用来生成了一个代理对象
// ScopedProxyFactoryBean也实现了FactoryBean接口,其getObject()方法返回的就是代理对象,也就是说通过工厂获取到的对象就是代理对象
// 调用代理对象的方法时,都会通过工厂的getBean(...)来获取目标对象,年后调用目标对象的方法
RootBeanDefinition proxyDefinition = new RootBeanDefinition(ScopedProxyFactoryBean.class);
proxyDefinition.setDecoratedDefinition(new BeanDefinitionHolder(targetDefinition, targetBeanName));
proxyDefinition.setOriginatingBeanDefinition(targetDefinition);
proxyDefinition.setSource(definition.getSource());
proxyDefinition.setRole(targetDefinition.getRole());
proxyDefinition.getPropertyValues().add("targetBeanName", targetBeanName);
if (proxyTargetClass) {
targetDefinition.setAttribute(AutoProxyUtils.PRESERVE_TARGET_CLASS_ATTRIBUTE, Boolean.TRUE);
} else {
proxyDefinition.getPropertyValues().add("proxyTargetClass", Boolean.FALSE);
}
proxyDefinition.setAutowireCandidate(targetDefinition.isAutowireCandidate());
proxyDefinition.setPrimary(targetDefinition.isPrimary());
if (targetDefinition instanceof AbstractBeanDefinition) {
proxyDefinition.copyQualifiersFrom((AbstractBeanDefinition) targetDefinition);
}
// 目标BeanDefinition不能作为候选BeanDefinition
targetDefinition.setAutowireCandidate(false);
targetDefinition.setPrimary(false);
// 注册目标BeanDefinition
registry.registerBeanDefinition(targetBeanName, targetDefinition);
return new BeanDefinitionHolder(proxyDefinition, originalBeanName, definition.getAliases());
}
}
ConditionEvaluator
class ConditionEvaluator {
// 根据注解信息判定是否忽略BeanDefinition注册
// ConfigurationPhase只有ConfigurationPhase.PARSE_CONFIGURATION与ConfigurationPhase.REGISTER_BEAN两值
public boolean shouldSkip(@Nullable AnnotatedTypeMetadata metadata, @Nullable ConfigurationPhase phase) {
// 没有Conditional(以及被其注解的注解)注解不会忽略
if (metadata == null || !metadata.isAnnotated(Conditional.class.getName())) {
return false;
}
if (phase == null) {
// 包含注解Component、ComponentScan、Import、ImportResource以及Bean时为ConfigurationPhase.PARSE_CONFIGURATION
// 否则为ConfigurationPhase.REGISTER_BEAN
if (metadata instanceof AnnotationMetadata &&
ConfigurationClassUtils.isConfigurationCandidate((AnnotationMetadata) metadata)) {
return shouldSkip(metadata, ConfigurationPhase.PARSE_CONFIGURATION);
}
return shouldSkip(metadata, ConfigurationPhase.REGISTER_BEAN);
}
// 将所有@Conditional注解的值(值为Condition类型,这里进行了实例化)取出放入conditions列表中
List<Condition> conditions = new ArrayList<>();
for (String[] conditionClasses : getConditionClasses(metadata)) {
for (String conditionClass : conditionClasses) {
Condition condition = getCondition(conditionClass, this.context.getClassLoader());
conditions.add(condition);
}
}
// 排序
AnnotationAwareOrderComparator.sort(conditions);
// 只有所有条件都满足才不会忽略
for (Condition condition : conditions) {
// 这里进行了两步检验,只有两步检验都通过才会通过,只要通过就会忽略
// condition不是ConfigurationCondition的子类或condition.getConfigurationPhase()为空时一定会通过第一步
// 当注解包含Import、Component等时,condition.getConfigurationPhase()为ConfigurationPhase.PARSE_CONFIGURATION时通过第一步
// 当注解不包含Import、Component等时,condition.getConfigurationPhase()为ConfigurationPhase.REGISTER_BEAN时通过第一步
// condition.matches(...)为第二步校验,false通过,即匹配不上通过
ConfigurationPhase requiredPhase = null;
if (condition instanceof ConfigurationCondition) {
requiredPhase = ((ConfigurationCondition) condition).getConfigurationPhase();
}
if ((requiredPhase == null || requiredPhase == phase) && !condition.matches(this.context, metadata)) {
return true;
}
}
return false;
}
}
AnnotatedBeanDefinitionReader
AnnotatedBeanDefinitionReader可以将某个类直接解析为BeanDefinition,就算该类并未被@Component标记。
创建实例
public class AnnotatedBeanDefinitionReader {
public AnnotatedBeanDefinitionReader(BeanDefinitionRegistry registry, Environment environment) {
this.registry = registry;
// 根据conditionEvaluator来决定指定的BeanDefinition是否会被注册
this.conditionEvaluator = new ConditionEvaluator(registry, environment, null);
// 注册常用的用于注解功能的扩展
AnnotationConfigUtils.registerAnnotationConfigProcessors(this.registry);
}
}
解析过程
public class AnnotatedBeanDefinitionReader {
// 将指定的类加载为BeanDefinition并进行注册
public void registerBean(Class<?> beanClass) {
doRegisterBean(beanClass, null, null, null, null);
}
/**
* @param instanceSupplier用来设置创建的BeanDefinition的instanceSupplier属性
* @param definitionCustomizers 可对创建的BeanDefinition进行一系列的额外处理,BeanDefinitionCustomizer是函数式接口
*/
<T> void doRegisterBean(Class<T> beanClass, @Nullable Supplier<T> instanceSupplier, @Nullable String name,
@Nullable Class<? extends Annotation>[] qualifiers, BeanDefinitionCustomizer... definitionCustomizers) {
// 通过AnnotatedBeanDefinitionReader创建的BeanDefinition为AnnotatedGenericBeanDefinition类型
AnnotatedGenericBeanDefinition abd = new AnnotatedGenericBeanDefinition(beanClass);
// this.conditionEvaluator为ConditionEvaluator类型对象,用来决定是否忽略当前BeanDefinition的注册
if (this.conditionEvaluator.shouldSkip(abd.getMetadata())) {
return;
}
abd.setInstanceSupplier(instanceSupplier);
// AnnotationScopeMetadataResolver.resolveScopeMetadata(...)首先会创建一个ScopeMetadata(默认单例,无代理)
// 然后通过解析@Scope注解(如果存在的话)来完成ScopeMetadata属性的赋值
ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(abd);
abd.setScope(scopeMetadata.getScopeName());
// 如果未传入name就由AnnotationBeanNameGenerator生成beanName
// AnnotationBeanNameGenerator会读取@Component(包括@Service等)、@Named、@ManagedBean的value值作为beanName
// 如果没有这些注解,会将简单类名的首字母小写作为beanName
String beanName = (name != null ? name : this.beanNameGenerator.generateBeanName(abd, this.registry));
// 根据类上的注解设置BeanDefinition的属性(包括lazyInit、primary、dependsOn、role、description)
AnnotationConfigUtils.processCommonDefinitionAnnotations(abd);
// 传入的注解可以覆盖类上的注解(签名获取的类上的注解是注解实例,而这里只是个注解类型)
if (qualifiers != null) {
for (Class<? extends Annotation> qualifier : qualifiers) {
if (Primary.class == qualifier) {
abd.setPrimary(true);
} else if (Lazy.class == qualifier) {
abd.setLazyInit(true);
} else {
abd.addQualifier(new AutowireCandidateQualifier(qualifier));
}
}
}
// 可自定义处理
for (BeanDefinitionCustomizer customizer : definitionCustomizers) {
customizer.customize(abd);
}
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(abd, beanName);
// 如果scopeMtedata的getScopedProxyMode()不为ScopedProxyMode.NO,那么调用ScopedProxyUtils.createScopedProxy(...)来创建一个代理BeanDefinition
definitionHolder = AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
BeanDefinitionReaderUtils.registerBeanDefinition(definitionHolder, this.registry);
}
}
ClassPathBeanDefinitionScanner
创建实例
ClassPathBeanDefinitionScanner通过扫描指定路径,获取满足条件的Java类来解析BeanDefinition。
public class ClassPathBeanDefinitionScanner extends ClassPathScanningCandidateComponentProvider {
public ClassPathBeanDefinitionScanner(BeanDefinitionRegistry registry, boolean useDefaultFilters,
Environment environment, @Nullable ResourceLoader resourceLoader) {
this.registry = registry;
// 成员变量includeFilters是TypeFilter类型的集合,可以通过其match(...)方法来过滤哪些类可以被注册为BeanDefinition
// 成员变量excludeFilters也是TypeFilter类型的集合,可以通过其match(...)方法来过滤哪些类不可以被注册为BeanDefinition
// excludeFilters里面的任意一个TypeFilter匹配成功,那么这些BeanDefinition就不会注册
// includeFilters里面的任意一个TypeFilter匹配成功,那么这些BeanDefinition就会注册
// excludeFilters的优先级高于includeFilters,默认情况下useDefaultFilters为true
if (useDefaultFilters) {
registerDefaultFilters();
}
// 如果传入的environment为null,在getEnvironment()时会根据getSystemProperties()与getSystemEnvironment()来创建environment变量
setEnvironment(environment);
// 设置资源加载器,这里会决定是否使用索引加速包扫描
setResourceLoader(resourceLoader);
}
public void setResourceLoader(@Nullable ResourceLoader resourceLoader) {
this.resourcePatternResolver = ResourcePatternUtils.getResourcePatternResolver(resourceLoader);
this.metadataReaderFactory = new CachingMetadataReaderFactory(resourceLoader);
// this.componentsIndex为CandidateComponentsIndex类型,这里用于获取索引组件
this.componentsIndex = CandidateComponentsIndexLoader.loadIndex(this.resourcePatternResolver.getClassLoader());
}
// 注册默认的TypeFilter
protected void registerDefaultFilters() {
// AnnotationTypeFilter根据注解类型筛选,当被指定的注解(或被其标记的注解)标记时匹配成功
this.includeFilters.add(new AnnotationTypeFilter(Component.class));
ClassLoader cl = ClassPathScanningCandidateComponentProvider.class.getClassLoader();
try {
this.includeFilters.add(new AnnotationTypeFilter(
((Class<? extends Annotation>) ClassUtils.forName("javax.annotation.ManagedBean", cl)), false));
} catch (ClassNotFoundException ex) {
... 加载失败,表示不支持JSR-250,什么也不用做 ...
}
try {
this.includeFilters.add(new AnnotationTypeFilter(
((Class<? extends Annotation>) ClassUtils.forName("javax.inject.Named", cl)), false));
} catch (ClassNotFoundException ex) {
... 加载失败,表示不支持JSR-330,什么也不用做 ...
}
}
}
// 加载索引组件
public final class CandidateComponentsIndexLoader {
private static CandidateComponentsIndex doLoadIndex(ClassLoader classLoader) {
// 不支持索引组件就什么也不做
if (shouldIgnoreIndex) {
return null;
}
// 解析所有META-INF/spring.components文件(由被索引的类=被@Indexed标记的注解构成的properties文件,如com.MyBean=...Component)
// 虽然可以手动编写META-INF/spring.components文件来指定注册的类,但一般不这么做,因为这会导致真正的包扫描不生效
// 索引目的主要用于加快包扫描速度,实际是在编译时通过插件的方式(引入jar包)生成META-INF/spring.components文件
// 而编译自动生成的META-INF/spring.components文件中,包含了所有被@Indexed(以及被其标记的注解)所标记的类
// @Component已被@Indexed标记,所以被@Component修饰的类已经放入META-INF/spring.components文件中,这就避免了文件扫描
Enumeration<URL> urls = classLoader.getResources(COMPONENTS_RESOURCE_LOCATION);
if (!urls.hasMoreElements()) {
return null;
}
List<Properties> result = new ArrayList<>();
while (urls.hasMoreElements()) {
URL url = urls.nextElement();
Properties properties = PropertiesLoaderUtils.loadProperties(new UrlResource(url));
result.add(properties);
}
int totalCount = result.stream().mapToInt(Properties::size).sum();
// 如果没有META-INF/spring.components文件或文件为空,那么就返回null
return (totalCount > 0 ? new CandidateComponentsIndex(result) : null);
}
}
解析过程
public class ClassPathBeanDefinitionScanner extends ClassPathScanningCandidateComponentProvider {
public int scan(String... basePackages) {
int beanCountAtScanStart = this.registry.getBeanDefinitionCount();
doScan(basePackages);
// 注册常用的用于扩展功能的BeanDefinition
if (this.includeAnnotationConfig) {
AnnotationConfigUtils.registerAnnotationConfigProcessors(this.registry);
}
// 根据BeanDefinition注册前后,BeanDefinitionRegistry中BeanDefinition的个数之差,来获取本次加载的BeanDefinition个数
return (this.registry.getBeanDefinitionCount() - beanCountAtScanStart);
}
protected Set<BeanDefinitionHolder> doScan(String... basePackages) {
Set<BeanDefinitionHolder> beanDefinitions = new LinkedHashSet<>();
// 循环着一个包一个包地处理
for (String basePackage : basePackages) {
// 找到一个包下,符合条件资源构建的BeanDefinition
Set<BeanDefinition> candidates = findCandidateComponents(basePackage);
// 循环着处理每个包下的beanDefinition
for (BeanDefinition candidate : candidates) {
// AnnotationScopeMetadataResolver.resolveScopeMetadata(...)首先会创建一个ScopeMetadata(默认单例,无代理)
// 然后通过解析@Scope注解(如果存在的话)来完成ScopeMetadata属性的赋值
ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(candidate);
candidate.setScope(scopeMetadata.getScopeName());
// AnnotationBeanNameGenerator类型的BeanNameGenerator,先以@Component、@Named、@ManagedBean的value作为beanName
// 否则以类名首字母小写作为beanName
String beanName = this.beanNameGenerator.generateBeanName(candidate, this.registry);
// 设置默认值
if (candidate instanceof AbstractBeanDefinition) {
postProcessBeanDefinition((AbstractBeanDefinition) candidate, beanName);
}
// 根据类上的注解设置BeanDefinition的属性(包括lazyInit、primary、dependsOn、role、description)
if (candidate instanceof AnnotatedBeanDefinition) {
AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate);
}
// 检查注册中心是否包含beanName
if (checkCandidate(beanName, candidate)) {
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);
// 如果scopeMtedata的getScopedProxyMode()不为ScopedProxyMode.NO,那么调用ScopedProxyUtils.createScopedProxy(...)来创建一个代理BeanDefinition
definitionHolder = AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
beanDefinitions.add(definitionHolder);
registerBeanDefinition(definitionHolder, this.registry);
}
}
}
return beanDefinitions;
}
public Set<BeanDefinition> findCandidateComponents(String basePackage) {
if (this.componentsIndex != null && indexSupportsIncludeFilters()) {
// 解决扫描加速的索引问题
return addCandidateComponentsFromIndex(this.componentsIndex, basePackage);
} else {
// 正常扫描包下组件
return scanCandidateComponents(basePackage);
}
}
private Set<BeanDefinition> scanCandidateComponents(String basePackage) {
Set<BeanDefinition> candidates = new LinkedHashSet<>();
// classpath*:将basePackage中的点换成斜杠路径/**/*.class
String packageSearchPath = ResourcePatternResolver.CLASSPATH_ALL_URL_PREFIX +
resolveBasePackage(basePackage) + '/' + this.resourcePattern;
// 实际上就是获取类路径下,指定包及其子包下的所有class文件资源
Resource[] resources = getResourcePatternResolver().getResources(packageSearchPath);
for (Resource resource : resources) {
// 一个resource代表一个class文件,文件必须可读才会解析
if (resource.isReadable()) {
// resource对应一个class文件,通过metadataReader可以获取此Class的元数据
MetadataReader metadataReader = getMetadataReaderFactory().getMetadataReader(resource);
// 根据excludeFilters、includeFilters,以及ConditionEvaluator来决定是否创建组件
if (isCandidateComponent(metadataReader)) {
// 通过扫描方式获取的BeanDefinition为ScannedGenericBeanDefinition类型
ScannedGenericBeanDefinition sbd = new ScannedGenericBeanDefinition(metadataReader);
sbd.setResource(resource);
sbd.setSource(resource);
// 要求类是顶层类或者static内部类,并且要是具体类(不能是接口或抽象类),总之是能够直接创建对象的类
if (isCandidateComponent(sbd)) {
candidates.add(sbd);
}
}
}
}
return candidates;
}
// 判断是否会作为候选组件
protected boolean isCandidateComponent(MetadataReader metadataReader) throws IOException {
// excludeFilters中的任意一个TypeFilter匹配成功,就不会作为候选组件
for (TypeFilter tf : this.excludeFilters) {
if (tf.match(metadataReader, getMetadataReaderFactory())) {
return false;
}
}
// includeFilters找那个的任意一个TypeFilter匹配成功且ConditionEvaluator不发生忽略时能作为候选组件
for (TypeFilter tf : this.includeFilters) {
if (tf.match(metadataReader, getMetadataReaderFactory())) {
// ConditionEvaluator校验是否忽略组件
// 等效于!this.conditionEvaluator.shouldSkip(metadataReader.getAnnotationMetadata())
return isConditionMatch(metadataReader);
}
}
return false;
}
private Set<BeanDefinition> addCandidateComponentsFromIndex(CandidateComponentsIndex index, String basePackage) {
Set<BeanDefinition> candidates = new LinkedHashSet<>();
// 先做一个初步筛选,获取所有初步筛选的类型
Set<String> types = new HashSet<>();
for (TypeFilter filter : this.includeFilters) {
// 获取注解类型(如org....Component)
String stereotype = extractStereotype(filter);
if (stereotype == null) {
throw new IllegalArgumentException("Failed to extract stereotype from " + filter);
}
// CandidateComponentsIndex中包含了候选类=过滤注解,如com.wanglang.MyBean=org....Component
// 筛选出所有value为stereotype(如org....Component)的key,即为被stereotype(如org....Component)标记的所有类型
types.addAll(index.getCandidateTypes(basePackage, stereotype));
}
// 此处与扫描根据Resource来解析BeanDefinition都一样了
for (String type : types) {
MetadataReader metadataReader = getMetadataReaderFactory().getMetadataReader(type);
if (isCandidateComponent(metadataReader)) {
// 通过索引方式获取的BeanDefinition为AnnotatedGenericBeanDefinition类型
AnnotatedGenericBeanDefinition sbd = new AnnotatedGenericBeanDefinition(metadataReader.getAnnotationMetadata());
if (isCandidateComponent(sbd)) {
candidates.add(sbd);
}
}
}
return candidates;
}















 906
906











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









