







因为网页版的答题太烦了。就写了一段自动答题的js
https://www.bilibili.com/v/newbie/basic-1?score=0
var i=0
setInterval(function(){
$('.answer-outer').eq(i%$(".answer-outer").length).trigger("click")
i++
}, 1500)
用法: 打开F12, 到Console窗口
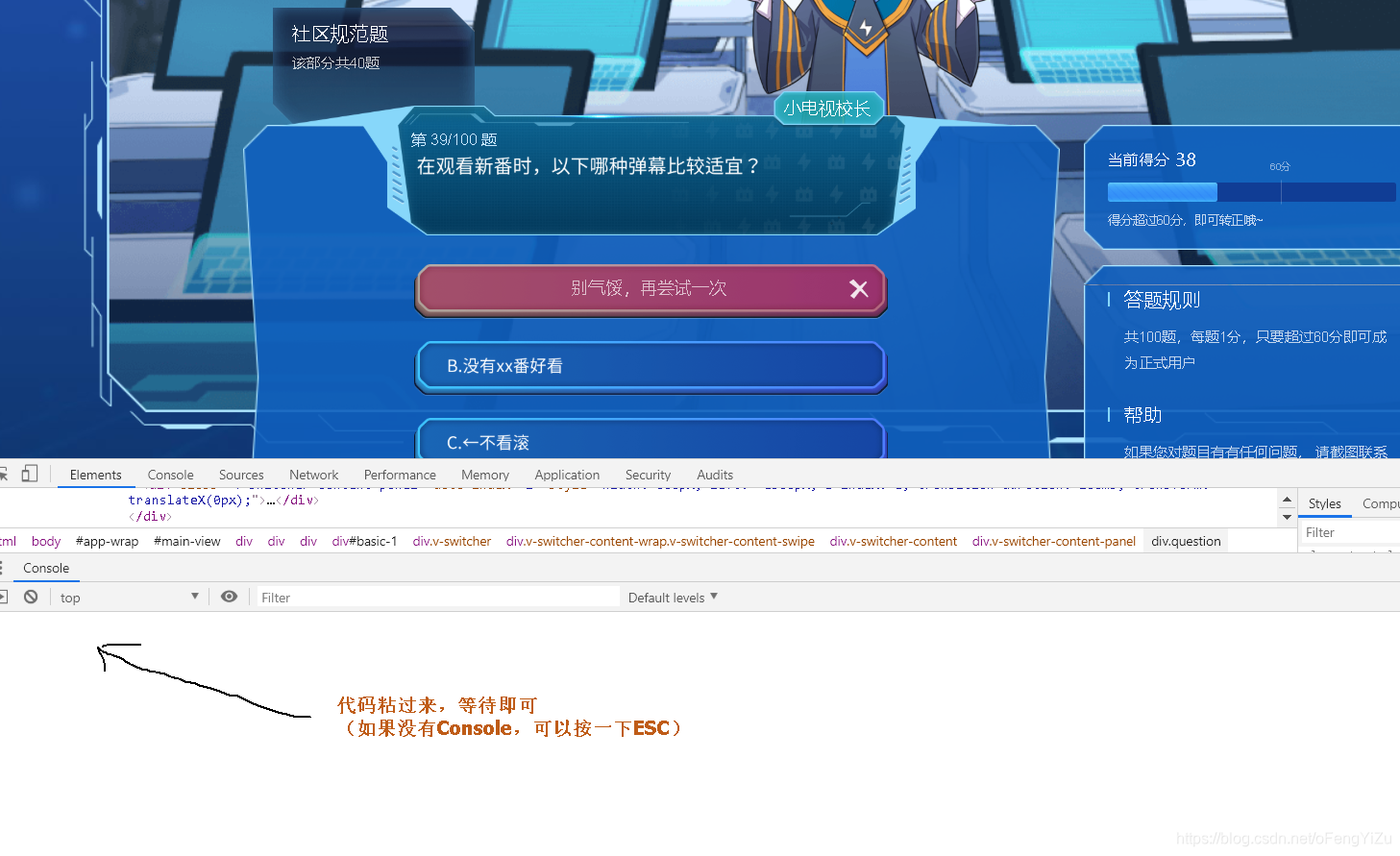
黏贴此处, 然后回车即可
到40+题的时候, 可以选择自己感兴趣的领域
卡住了就刷新一下。 继续上面操作

希望你能混到60分(雾)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









