







 本文主要对Theano库中的LSTM实现进行详细分析,包括整体框架理解、各函数的功能解析,帮助读者深入理解LSTM的工作流程。通过数据维度变化的示意图,配合代码阅读,便于更好地掌握LSTM的内部结构。同时提供了相关的参考资料链接,以供进一步学习。
本文主要对Theano库中的LSTM实现进行详细分析,包括整体框架理解、各函数的功能解析,帮助读者深入理解LSTM的工作流程。通过数据维度变化的示意图,配合代码阅读,便于更好地掌握LSTM的内部结构。同时提供了相关的参考资料链接,以供进一步学习。
因为需要使用 lstm,lstm的代码,和官方教程解释得不是很详细,故对 theano lstm进行一些分析理解。
整体框架理解
这份代码实现的功能是利用RNN(LSTM)对IMDB每部电影的评论页面的评论进行情感分类。
这里的数据集比较特殊。一个包含所有句子的二重列表,列表的每个元素也为一个列表。
大小为2的tuple,train[0][n] 代表一个句子(对于词库索引的List),train[1][n]为该句子的情感分类标签。
举个简单的栗子,
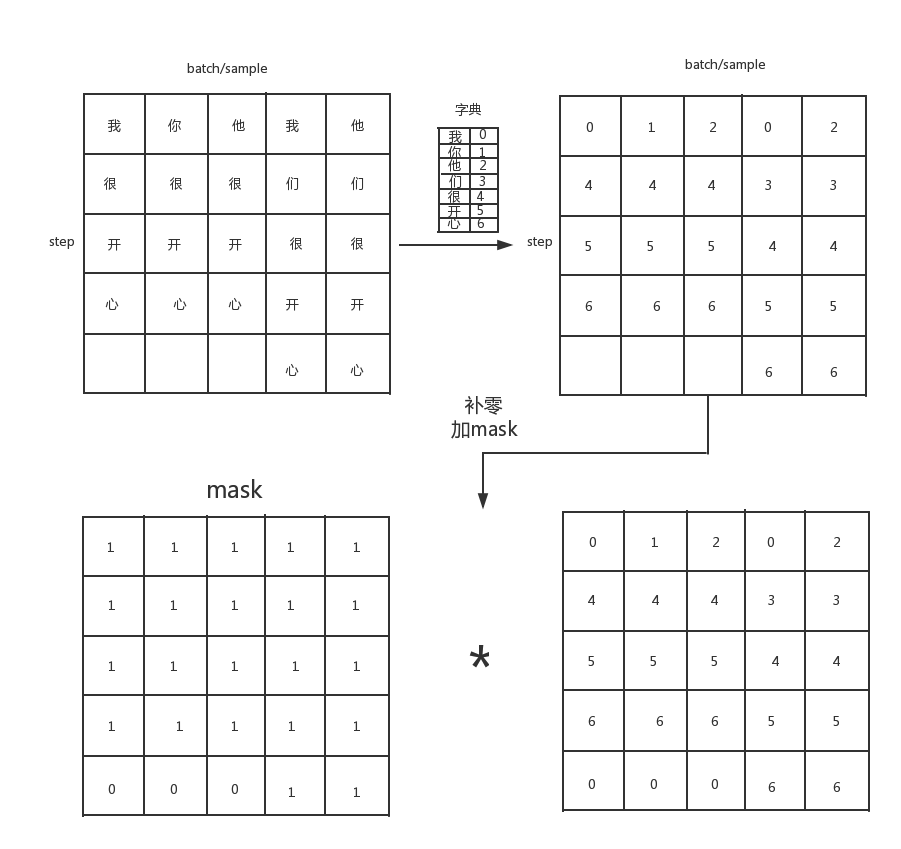
把整个过程中数据的维度的变化画出来,我觉得更利于理解程序的流程(结合代码看体验更佳)。
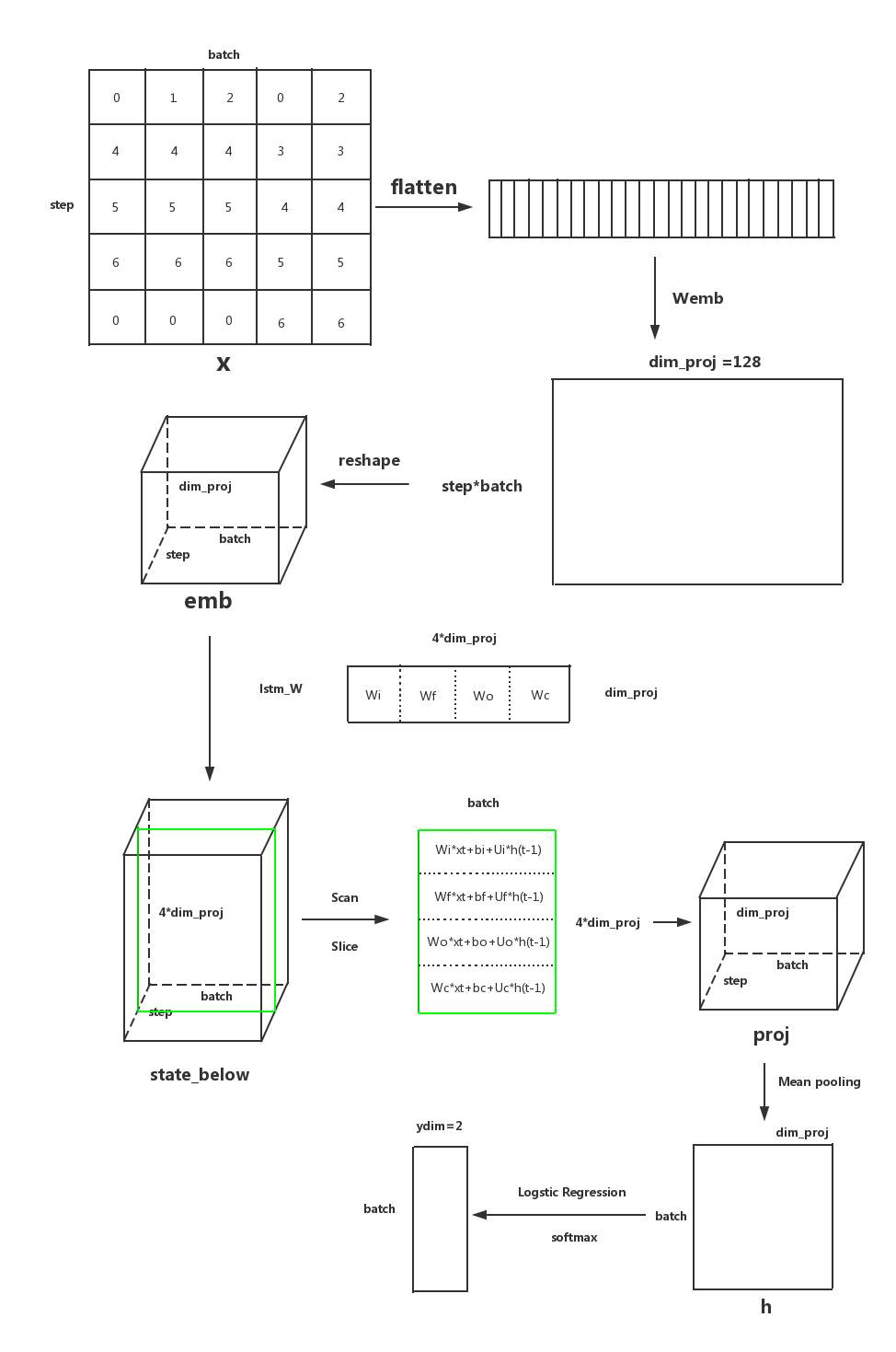
各个函数分析
def get_minibatches_idx(n, minibatch_size, shuffle=False):
返回值:zip(range(len(minibatches)), minibatches)
该函数得到了 shuffle 后的个数为 (n/batch_size)+1个batch,每个batch为minibatch_size的索引
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 9918
9918

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









