






随着当前大数据技术应用趋势,企业对单一的数据湖和数仓架构并不满意。越来越多的企业开始融合数据湖和数据仓库的平台,不仅可以实现数据仓库的功能,同时还实现了不同类型数据的处理功能、数据科学、用于发现新模型的高级功能。这个模式就是湖仓一体,那么什么是湖仓一体?在此之前我们首先对数据仓库和数据湖进行大致了解。
一、数据仓库和数据湖
数据仓库:是传统的数据存储方式,其核心概念是将不同来源的数据抽取、转化和加载到一个中心化的存储系统中,供企业进行决策分析使用。
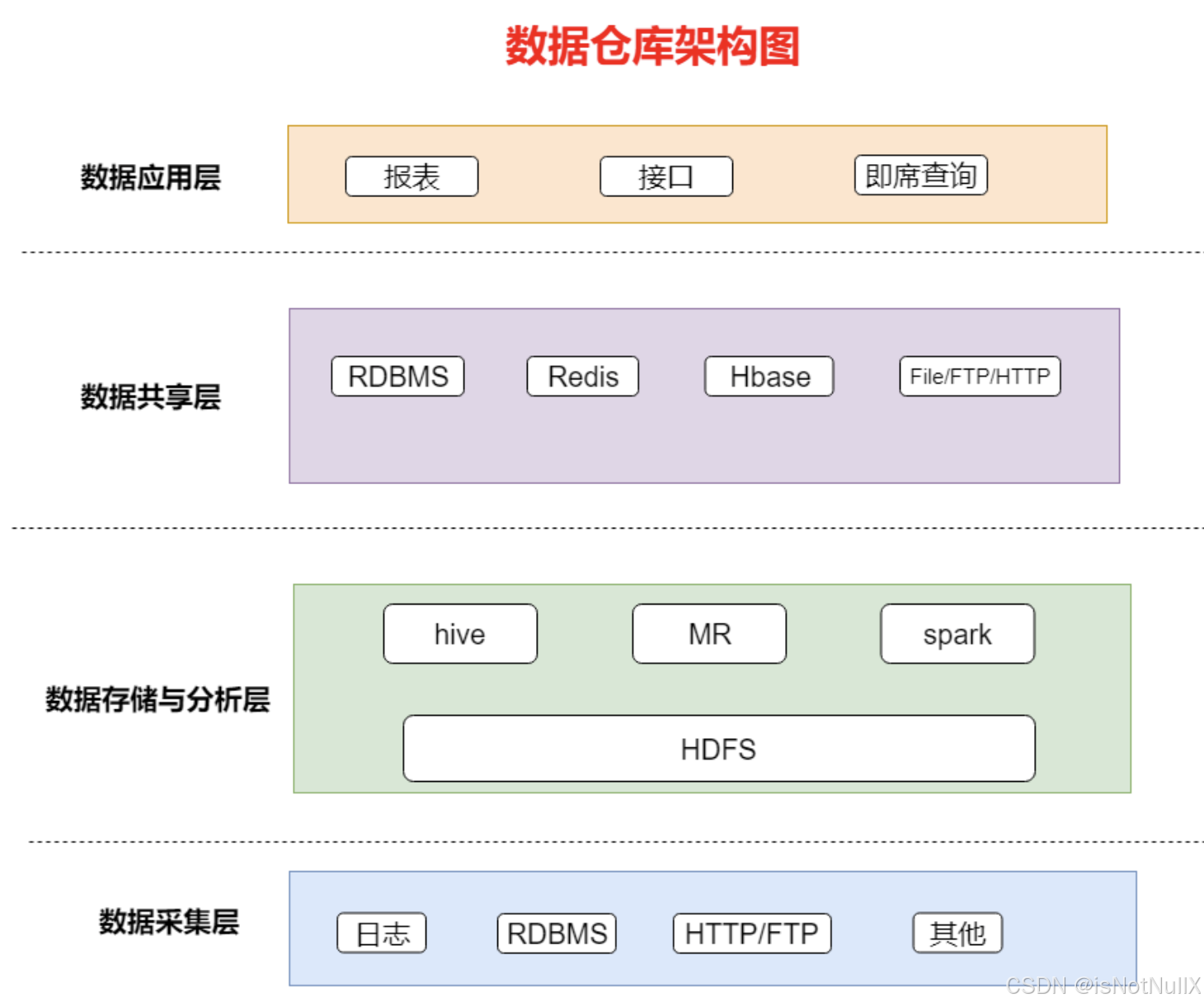
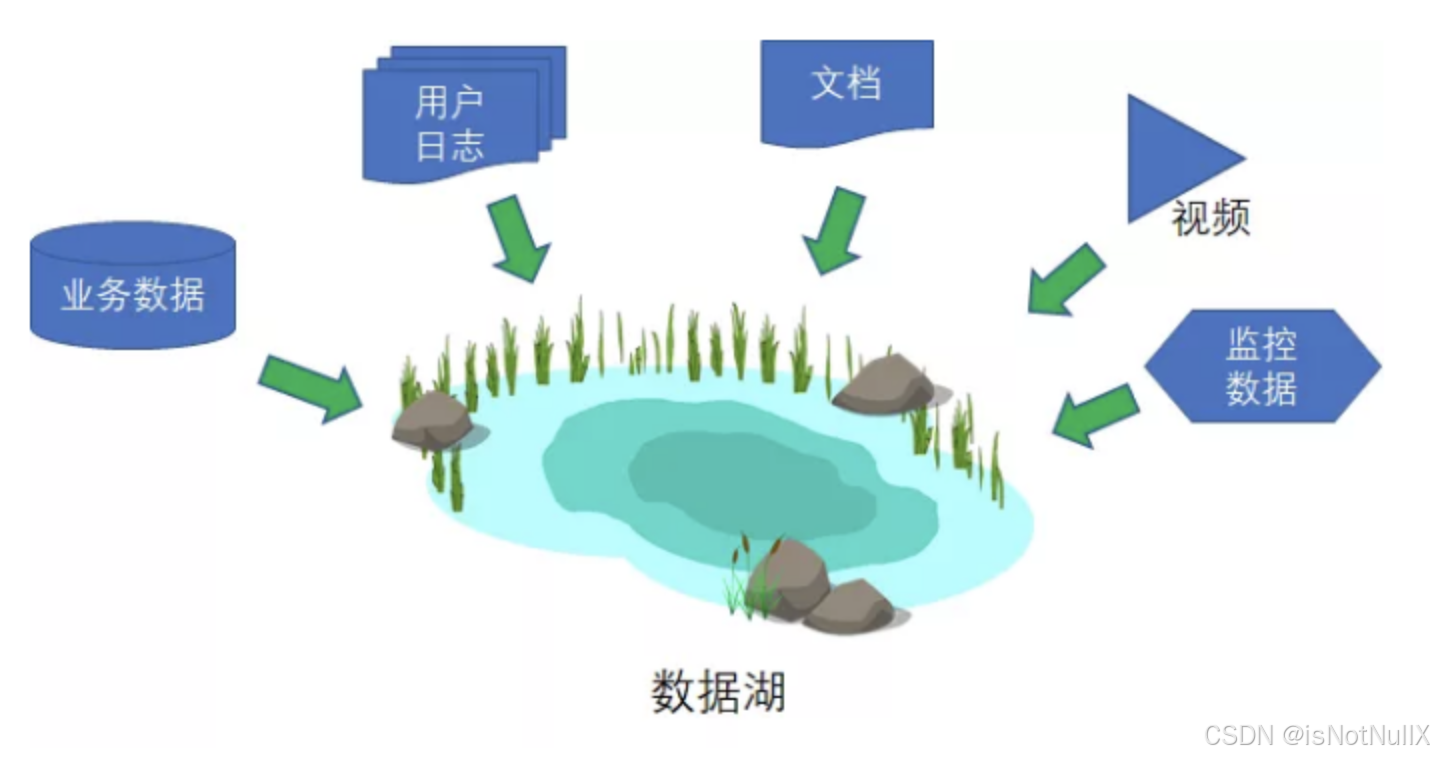
数据湖:是近年来兴起的一种新兴数据存储模式,它以原始、未处理的大量数据为基础,存储在云端或本地存储系统中。数据湖无需事先定义数据结构,可以灵活存储各种类型的数据,包括结构化、半结构化和非结构化数据。
二、湖仓一体出现的原因
而在面对以下难题时,单一的数据仓库和数据湖已无法满足需求,因此湖仓一体应运而生:
1、数据规模和复杂度增长的需求:随着互联网的发展,企业数据量呈指数级攀升,数据类型也日益多样化,包括大量的非结构化数据(如图片、视频、音频等)。传统的数据仓库难以应对如此庞大的数据规模和复杂的数据类型,而数据湖虽然可以存储各种类型的数据,但在数据管理和处理能力上有所欠缺。湖仓一体的出现能够满足企业对大规模、多类型数据的存储和处理需求。
2、业务对数据实时性要求的提高:在当今的商业环境中,企业需要实时获取数据并进行分析,以便及时做出决策。传统的数据仓库和数据湖架构在数据处理的时效性上存在不足,湖仓一体通过支持实时查询和分析,能够更好地满足业务对数据实时性的要求。
3、降低成本和提高效率的需求:企业同时维护数据仓库和数据湖两套系统,成本较高且管理复杂。湖仓一体可以在一个平台上实现数据的存储、处理和分析,减少了数据的冗余和迁移,降低了存储成本和管理成本,同时提高了数据处理的效率。
4、技术发展的推动:云计算、分布式存储和计算等技术的不断发展,为湖仓一体的实现提供了技术基础。例如,存算分离的架构使得系统能够扩展到更大规模的并发能力和数据容量,开放、标准化的存储格式和丰富的 API 支持使得各种工具和引擎可以高效地对数据进行直接访问。
三、湖仓一体
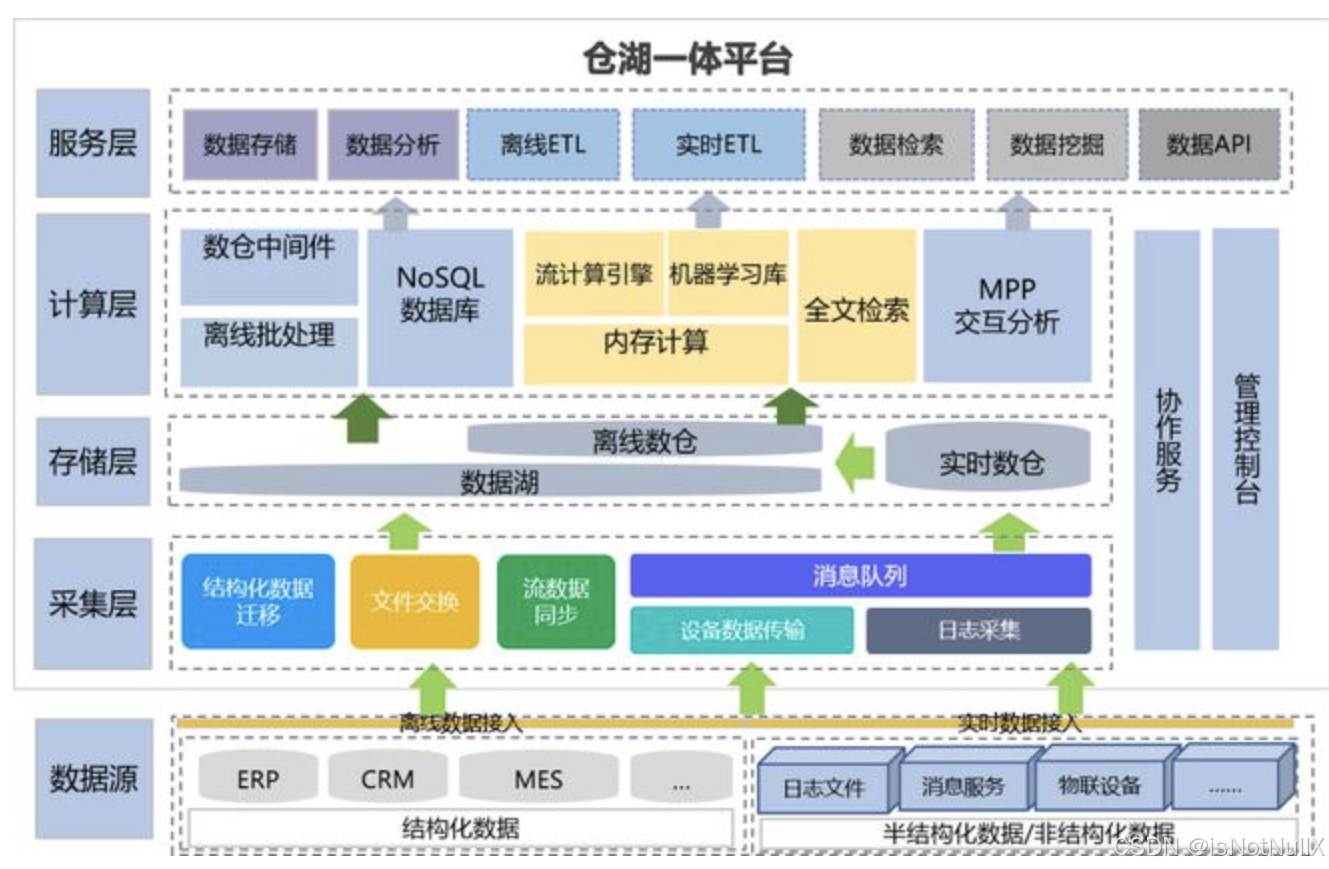
1、湖仓一体定义:是一种新兴的数据管理和分析架构,它结合了数据仓库和数据湖的优点,旨在提供一个统一、灵活且高性能的数据存储和处理平台。在传统的数据处理架构中,数据仓库通常用于存储结构化数据,以便进行快速查询和分析,而数据湖则用于存储大量原始的、非结构化的或半结构化的数据。在湖仓一体模式中,数据被原样加载到数据湖中,同时进行一定程度的模式定义和质量控制,以便更好地支持企业的数据分析和决策。湖仓一体的模式适用于数据量较大、多种数据类型混合存储的场景,提供了更好的查询性能和数据探索能力。
2、湖仓一体的优点:
· 统一的数据平台:减少了数据移动的需要,简化了数据治理和管理。
· 灵活性:可以处理各种类型的数据,包括结构化、半结构化和非结构化数据。
· 性能:利用现代的并行处理技术,如Apache Spark,提供快速的数据读写和查询能力。
· 成本效益:通过使用云存储服务,可以根据实际需求动态扩展存储和计算资源,避免了传统数据仓库的固定成本。
3、湖仓一体的流程:
1)数据接入:将来自不同数据源(如关系型数据库、文件系统、传感器等)的数据接入到湖仓一体平台中。这可能涉及到数据的抽取、转换和加载(ETL)过程,或者使用更高效的实时数据接入技术,如数据流式传输。
2)数据存储:根据数据的类型、访问频率、存储期限等因素,将数据存储在湖仓一体平台的合适位置。例如,对于经常访问的结构化数据,可以存储在数据仓库部分;对于非结构化数据,可以存储在数据湖部分。同时,要确保数据的存储格式符合湖仓一体平台的要求,以便后续的查询和分析。
3)数据处理和分析:使用湖仓一体平台提供的各种计算引擎和分析工具,对数据进行处理和分析。例如,使用批处理引擎对大规模的历史数据进行处理,使用流式计算引擎对实时数据进行处理,使用交互式分析引擎进行探索性分析。
4)数据应用:将分析结果应用到企业的业务决策、风险管理、市场营销等领域。这可能涉及到将数据可视化展示给用户,或者将数据提供给其他业务系统进行进一步的处理。
4、湖仓一体是通过一套架构,满足所有的分析需求,抽象化的描述,要能实现 One Data、All Analytics 的业务价值。
1)统一数据存储:在湖仓一体架构下,数据要统一存储管理,一份数据作为 Single source of truth,避免导来导去,造成数据冗余,分析口径不一致等问题;存储层通常采用 S3/HDFS 作为数据存储底层,并采用开放数据湖或者私有的数据格式去管理数据。
2)极速查询引擎:基于统一的数据存储,湖仓一体架构要能满足所有的业务分析场景的诉求,包括 BI 报表、交互式分析、实时分析、ETL 数据加工等场景,这就要求必须要有一个足够强大的分析引擎,能同时满足这些场景的查询需求。
3)按需查询加速:对于部分业务场景特别复杂的查询,数据源数据组织未针对分析优化,直接分析不一定能满足查询延时的需求,湖仓一体架构要具备通用的数据查询加速的能力,并且不破坏 Single source of truth 的原则。
5、湖仓一体的应用场景:
1)数据多样性场景:企业内部业务和数据系统众多,需要处理的结构化和非结构化数据规模急剧膨胀。湖仓一体可以实现统一的数据管理和共享,对非结构化数据进行有效治理,提升数据整体 “能效”,满足企业对多类型数据的存储、管理和分析需求。
2)与 AI 结合的机器学习场景:湖仓一体可以存储和处理大量的非结构化数据,为机器学习提供丰富的数据源。同时,它能够对接机器学习算法和平台,对非结构化数据进行特征提取和计算,更好地挖掘数据价值,支持企业的智能化应用。
3)服务于数据中台的实时数仓场景:数据中台要求数据库在分析处理过程中强调事务一致性,并保持低延迟和提升实时处理能力,湖仓一体的特性能够很好地满足这些要求,为数据中台提供实时的数据支持。
4)支撑微服务的数据融合底座场景:可以有效解决传统架构中扩展困难以及维护困难的问题,为微服务架构提供统一的数据存储和管理平台,促进微服务之间的数据共享和协同工作
数据湖和数据仓库,是在今天大数据技术条件下构建分布式系统的两种数据架构设计取向,要看平衡的方向是更偏向灵活性还是成本、性能、安全、治理等企业级特性。
但是数据湖和数据仓库的边界正在慢慢模糊,数据湖自身的治理能力、数据仓库延伸到外部存储的能力都在加强。在这样的背景之下,湖仓一体架构为业界和用户展现了一种数据湖和数据仓库互相补充,协同工作的架构。这样的架构同时为用户提供了数据湖的灵活性和数据仓库的诸多企业级特性,将用户使用大数据的总体拥有成本进一步降低,并成为是下一代大数据平台的演进方向。
了解更多数据仓库与数据集成关干货内容请关注>>>FineDataLink官网
免费试用、获取更多信息,点击了解更多>>>体验FDL功能

















 1958
1958

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









