






近年来很多企业都在使用数据湖,希望它能解决数据孤岛问题,先把原始数据“汇总起来再说”,最大的吸引力在于接收各种类型的数据:结构化的、半结构的、日志、API流、埋点……统统接得住。
理想很丰满,现实却是:
-
汇总慢、业务数据迟迟分析不了;
-
字段结构变了,结果数据和业务系统不匹配;
-
多个系统接入同一底座,数据乱、版本冲突、可读性差。
这些问题背后,不完全是技术架构的问题,更多是“数据怎么进来”这件事没做好,因此今天我们来探讨一个更基础但常被忽视的话题:数据同步。
一、什么是数据同步
数据同步(Data Synchronization)是指通过技术手段实现数据在不同系统、数据库或存储位置之间的实时或周期性一致化过程,其核心目标是确保数据的完整性、时效性和可用性。根据同步策略的不同,可分为全量同步(一次性完整复制)和增量同步(仅传输变化部分)。
数据同步与数据湖的关联
数据湖作为企业级海量数据的存储中心,需要从多源(如数据库、IoT设备、日志系统等)持续摄入数据,而数据同步技术正是实现这一过程的核心工具。
数据同步的作用主要体现在以下几个方面:
1、多源数据整合
企业的数据通常分散在多个系统中,包括关系型数据库、日志文件、传感器数据等。通过数据同步技术,这些异构数据可以实时或定期地汇聚到数据湖中,形成统一的数据视图,打破数据孤岛,支持全局分析和决策。
2、实时性保障
在快速变化的业务环境中,实时数据对于及时响应市场变化至关重要。数据同步支持将实时生成的数据,如用户行为日志、交易记录等,立即传输到数据湖,确保分析基于最新的数据,提升业务响应速度。
3、数据一致性维护
随着源系统的数据不断更新,数据同步机制确保这些变更能够及时反映到数据湖中,保持数据的一致性和完整性,避免因数据滞后或不一致导致的分析偏差。
在数据湖架构中,常用的数据同步策略包括:
-
全量同步(一次性搬运):定期将整个数据集从源系统复制到数据湖,适用于数据量较小或对实时性要求不高的场景。
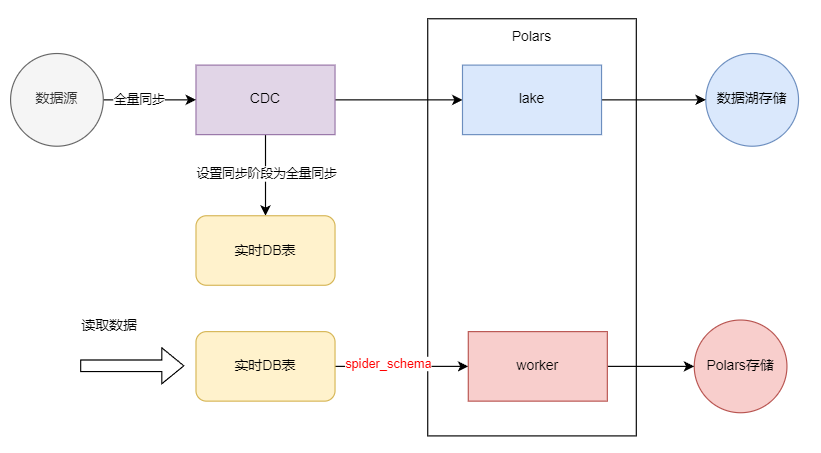
-
增量同步(只同步新增或变更数据):仅传输自上次同步以来发生变化的数据,减少数据传输量,提高同步效率,适用于数据量大且需要频繁更新的场景。
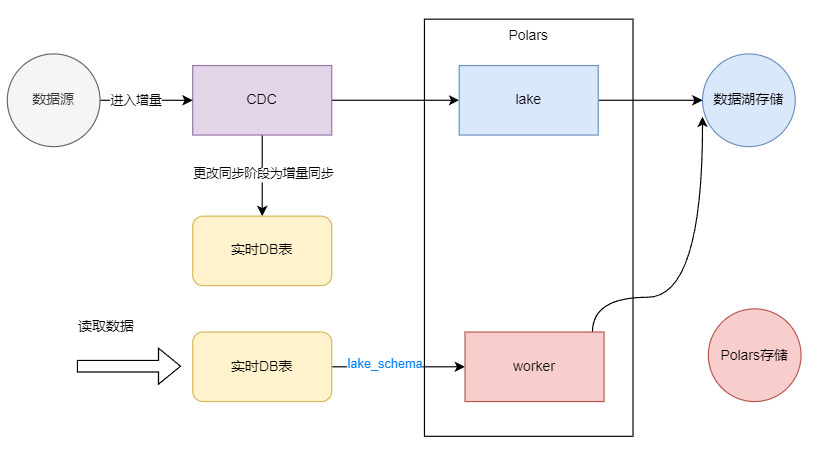
-
实时同步(CDC,变更数据捕获):通过监控源系统的日志或变更,实时捕获并传输数据更新,确保数据湖中的数据始终与源系统同步,适用于对实时性要求高的业务场景。CDC(Change Data Capture),是实现实时增量同步的核心机制,它通过监听数据库日志(如 binlog)实时捕获变更。
二、完整的数据同步
很多人默认“同步”这事就是定时拉个数据、往目标库里一塞就完了,一旦开始跑线上系统,就会发现表结构经常变、数据传过去了但业务却查出来不对、昨天还能跑通今天字段就对不上了等等问题,这些都表明同步不是简简单单的数据传输工作。
一套完整的同步系统,实际上是由多个阶段组成的协同链路,它不是“跑一次任务”,而是“持续在线的分工协作”。我们可以简单拆成三个部分来理解:源端(数据来源)、计算与传输层(数据处理)、目标端(数据存储)。
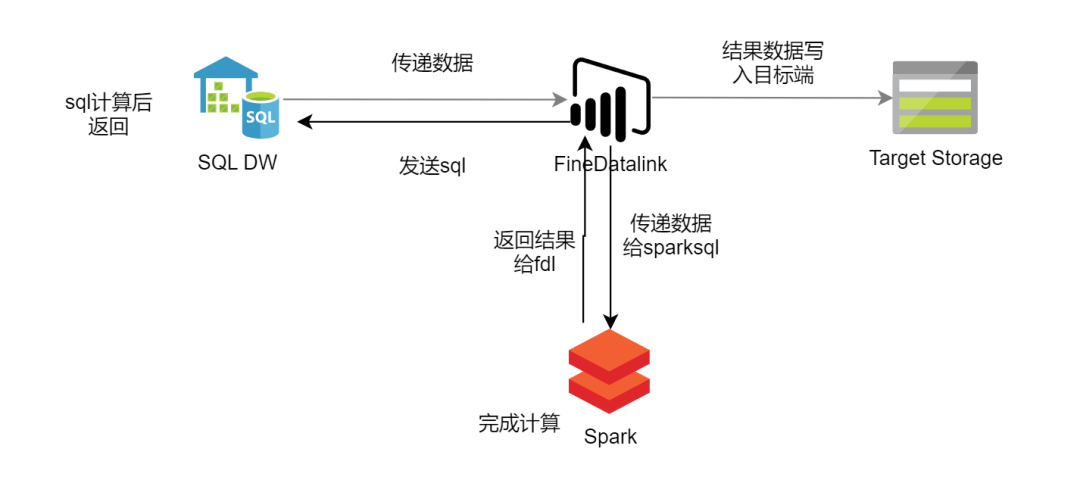
1、源端:数据的起点
源端是数据生成和存储的地方,可能包括关系型数据库(如MySQL、Oracle)、非关系型数据库(如MongoDB、Cassandra)、日志系统、传感器数据流等多种形式,每种数据源都有其独特的接口和访问方式,因此在同步数据时,需要针对不同的数据源制定相应的采集策略。
挑战:
-
接口多样性:不同的数据源可能有不同的协议、接口和认证方式。比如 MySQL 可以用 binlog 抓取,MongoDB 则需要监听 Oplog,Kafka 要用 Consumer Group,这些不统一造成接入门槛高,增加了数据采集的复杂性。
-
数据格式不统一:源端数据可能是结构化、半结构化或非结构化的,有的字段是 JSON,有的是数组,有的是枚举,需进行格式转换以适应目标端的存储要求。
解决方案:
-
使用通用的数据采集工具:采用支持多种数据源的采集工具或平台,自动识别主流数据库的结构变化,比如主键、索引、字段类型等,还能内嵌增量判断逻辑、CDC 订阅机制,极大简化开发成本。
-
引入接口标准与元数据管理机制:通过平台配置统一接口规范,例如源库信息、同步频率、字段命名、数据延迟容忍度等,形成一套可追踪、可管控的标准流程。
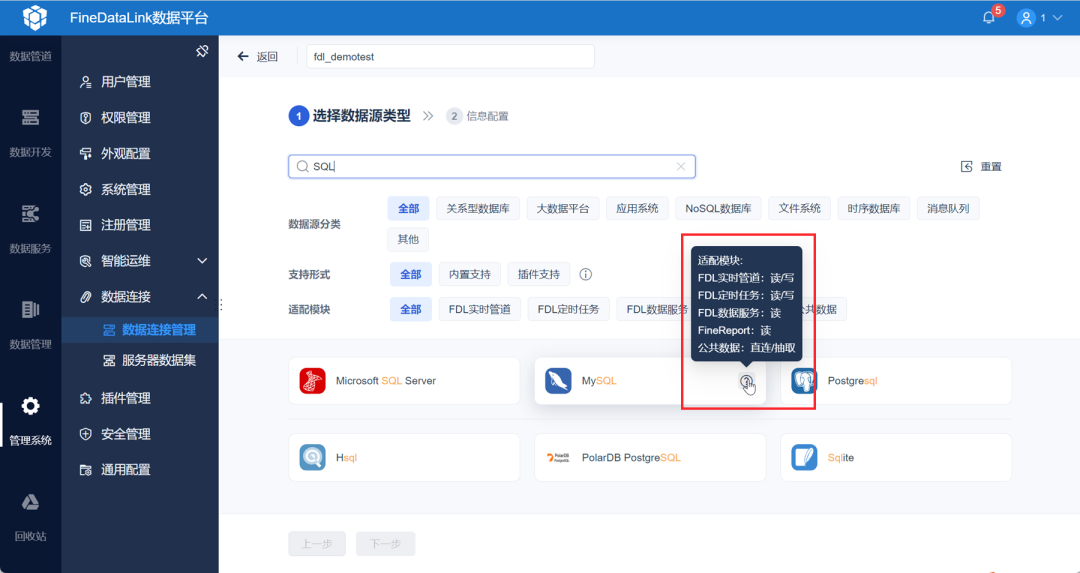
FDL 提供了强大的多源接入能力,支持多种异构数据源,包括关系型数据库、非关系型数据库、API接口等,通过可视化界面和向导式的配置流程,用户可以轻松配置和管理这些数据连接。
2、计算与传输层:数据的处理与移动
数据从源头采出来,并不意味着它就已经安全抵达目标系统了。在实际同步过程中,最常出问题的往往是在路上,尤其是数据量一旦上来,字段变更一多,网络一不稳定,各种同步失败、数据丢失、字段对不上、查数查错的情况就频繁出现了。
在数据从源端到达目标端的过程中,计算与传输层负责数据的清洗、转换、加密以及传输等工作,这一环节确保数据在传输过程中保持完整性、安全性,并满足目标端的存储和使用要求。
挑战:
-
数据质量:源端数据可能存在重复、缺失、错误等问题,需要在传输前进行清洗和校验。
-
传输效率:大规模数据的传输可能受到网络带宽和延迟的限制,影响同步的实时性。
-
安全性:数据在传输过程中可能面临窃听、篡改等安全威胁。
解决方案:
-
数据预处理:在传输前,对数据进行去重、补全、校验等处理,提升数据质量,尽可能在同步链路外解决“脏数据”问题。
-
增量传输:采用增量同步或变更数据捕获(CDC)技术,仅传输发生变化的数据,既减轻链路压力,也提高处理效率。
-
加密传输:使用安全的传输协议(如SSL/TLS)对数据进行加密,确保数据在传输过程中的安全性。
FDL 的数据管道任务支持同步源库DDL功能,开启相关选项后,在源库发生DDL(删除表、新增字段、删除字段、修改字段名称、修改字段类型(长度修改 & 兼容类型修改))时,管道任务可以自动同步这些来源端变化至目标端,不需人为介入修改目标表结构。
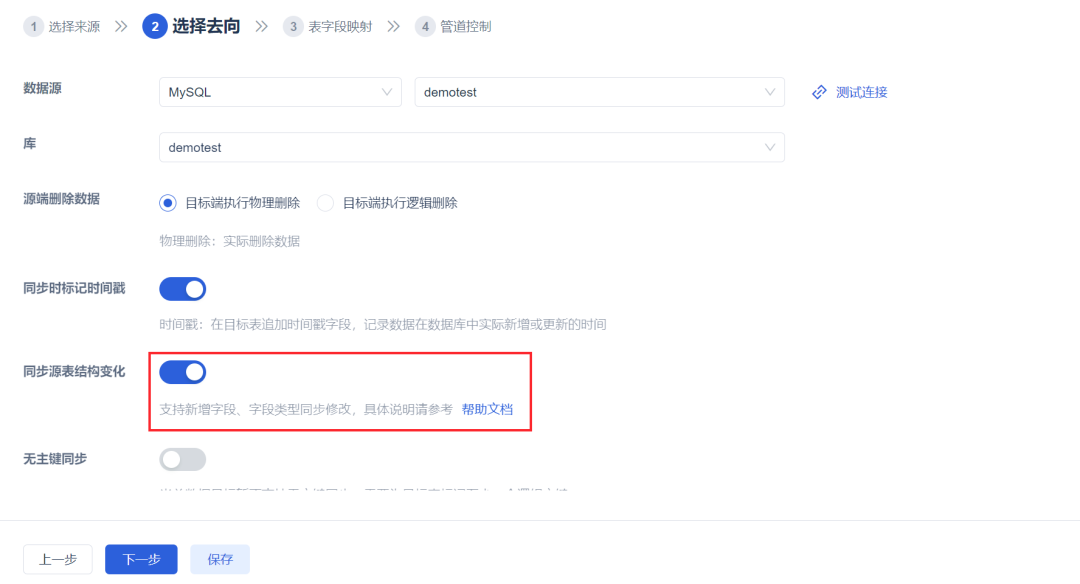
3、目标端:数据的落地与存储
目标端是数据链路中的最终归宿,通常是数据湖或数据仓库,也可以是对象存储、分析型数据库、甚至是第三方BI系统的中间库,数据在目标端的存储方式和结构,直接决定了后续的数据可用性、可查性与可治理性。
挑战:
-
数据格式兼容性:目标端可能有特定的数据格式要求,需要确保传输的数据与之兼容。
-
元数据管理:需要对数据的来源、更新时间、版本等元信息进行管理,方便后续追溯和使用。
-
数据一致性:确保目标端的数据与源端保持一致,避免数据丢失或重复。
解决方案:
-
统一的数据存储格式:采用如Parquet、ORC等列式存储格式,提升数据的存储和查询效率。
-
完善的元数据管理:建立元数据管理系统,记录数据的相关信息,支持数据的可追溯性。
-
一致性校验机制:定期对源端和目标端的数据进行比对,确保数据的一致性。
FDL在管道任务记录了详细的状态信息,包括时间、状态、异常情况等,这些信息实际上构成了元数据的一部分,有助于追踪数据的来源、变更历史和当前状态,方便后续的管理和审计。
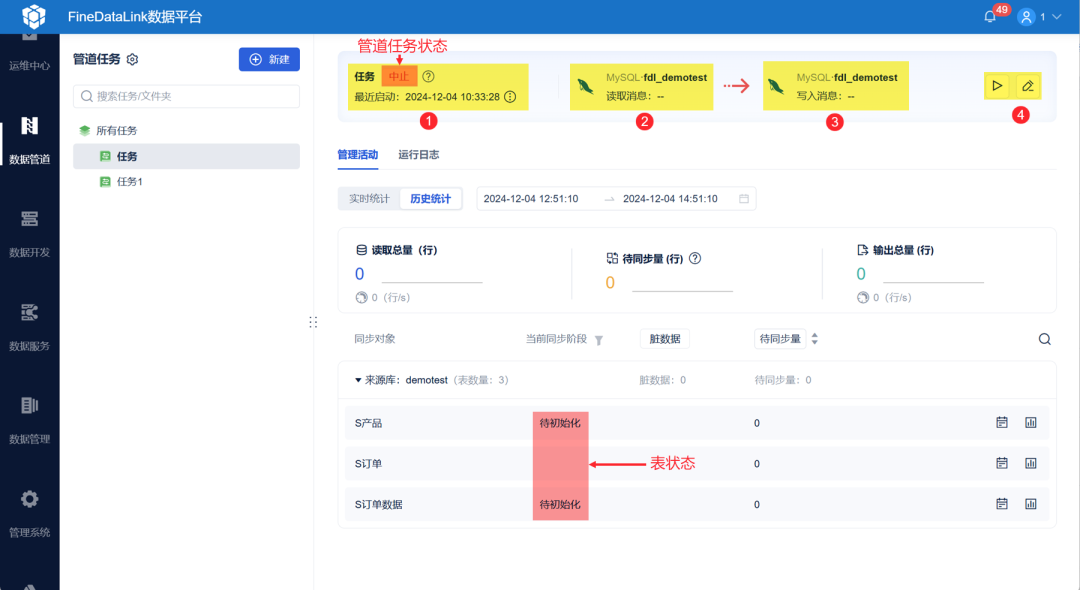
完整的数据同步过程涉及源端的数据采集、计算与传输层的数据处理,以及目标端的数据存储。每个环节都有其独特的挑战和解决方案。通过构建高效、可靠的数据同步机制,企业可以确保数据湖中的数据始终保持高质量和高可用性,从而为数据分析和业务决策提供坚实的基础。
FineDataLink是一款集实时数据同步、ELT/ETL数据处理、离线/实时数据开发、数据服务和系统管理于一体的数据集成工具,可在Windows或Linux环境上单机/集群部署,全程基于B/S浏览器端进行任务开发和任务运维,更多精彩功能,邀您体验,希望能帮您解决企业中数据从任意终端到任意终端的处理和传输问题,让流动的数据更有价值!
了解更多数据仓库与数据集成相关干货内容请关注>>>FineDataLink
免费试用、获取更多信息,点击了解更多>>>体验FDL功能

















 2062
2062

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









