






- 计算两个MultiIntervalSet对象的相似度:
double Similarity(MultiIntervalSet s1, MultiInterval Set s2)
具体计算方法:按照时间轴从早到晚的次序,针对同一个时间段内两个对象里的interval,若它们标注的label等价,则二者相似度为1,否则为0;若同一时间段内只有一个对象有interval或二者都没有,则相似度为0。将各interval的相似度与interval的长度相乘后求和,除以总长度,即得到二者的整体相似度。
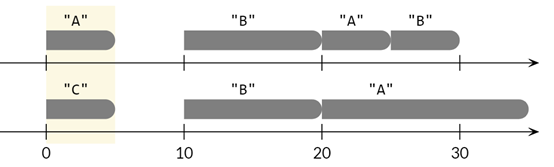
针对上图中的两个对象:
{ A = [[0,5),[20,25)], B = [[10,20),[25,30)] }
{ A = [[20,35)], B = [[10,20)], C = [[0,5)] }
它们的相似度计算如下:
( 5×0 + 5×0 + 10×1 + 5×1 + 5×0 + 5×0 ) ÷ ( 35 - 0 ) = 15 / 35 ≈ 0.42857
看到这个题目的首先想法就是计算公式的简化
分子的计算即为所有的相似度的总和
我们采用类似于括号匹配的方法来计算
设定一个double similar 来记录相似度总和。
指定一个标签label 从s1和s2中取出所有有关这个标签的集合并把它们放入一个treeset当中
当遇到一个start 的时候压栈,如果遇到end则弹栈,这一对区间必定属于A或者属于B
当遇到一个start压栈后,再次遇到start ,压栈,遇到end则弹栈,计算该end-start并将其加到similar当中
当遍历完所有(start,end)则结束计算,similar值即为相似度总和
分母的计算应该如下:
1.取s1和s2中起始点最小的那个为min
2.取s1和s2中结束点最大的那个为max
3.分母similarlength = max - min
最终代码:
public class APIs<L> {
public static final double POSITIVE_INFINITY = 1.0 / 0.0;
public double Similarity(MultiIntervalSet<L> s1, MultiIntervalSet<L> s2) {
double similarSum = 0, min = POSITIVE_INFINITY, max = 0;
Set<L> s1Labels = s1.labels();
Iterator<L> label = s1Labels.iterator();
while (label.hasNext()) {
TreeSet<time> tmpSet = new TreeSet<>();
L tmpL = label.next();
LinkedList<Long> startSet = new LinkedList<>();
LinkedList<Long> endSet = new LinkedList<>();
tmpSet.addAll(s1.intervals(tmpL));// 将s1中label的所有时间段加入tmpSet当中
for (time tmpTime : tmpSet) {
if (tmpTime.start() < min)
min = tmpTime.start(); // 计算区间最小值
if (tmpTime.end() > max)
max = tmpTime.end();// 计算区间最大值
startSet.add(tmpTime.start());
endSet.add(tmpTime.end());
}
for (time tmpTime : s2.intervals(tmpL)) {
if (tmpTime.start() < min)
min = tmpTime.start(); // 计算区间最小值
if (tmpTime.end() > max)
max = tmpTime.end();// 计算区间最大值
startSet.add(tmpTime.start());
endSet.add(tmpTime.end());
}
Collections.sort(startSet);
System.out.println(startSet);
Collections.sort(endSet);
System.out.println(endSet);
Stack<Long> stack = new Stack<Long>();
stack.empty();
while (!startSet.isEmpty() || !endSet.isEmpty()) // 当起始点集和终点集合不为空的时候
{
if (stack.isEmpty()) { // 如果栈为空 则压栈
Long tmp = startSet.getFirst(); // 取第一个元素
stack.push(tmp); // 将其压栈
startSet.removeFirst();// 从起始点集合中移除这个元
}
else if (stack.size() == 2) { // 如果栈里面有两个起始点,则其中一个与end对相似度有贡献,计算该值并记录
System.out.println(endSet.getFirst()+"sdf"+stack.peek());
similarSum += endSet.getFirst() - stack.pop();
endSet.removeFirst();
}
else if(stack.size()==1){// 如果栈里面已经有一个起始点集合了
if (startSet.size() > 0) {
if (startSet.getFirst() <= endSet.getFirst())// 如果起始点集的第一个元素小于终点集合的第一个元素,则压栈
{
stack.push(startSet.getFirst());
startSet.removeFirst();
} else {
stack.pop();
endSet.removeFirst();
}
} else {
stack.pop();
endSet.removeFirst();
}
}
}
}
return similarSum / (max-min);
}
public static void main(String[] args) {
MultiIntervalSet<String> s1 = new MultiIntervalSet<>();
MultiIntervalSet<String> s2 = new MultiIntervalSet<>();
APIs<String> method = new APIs<>();
s1.insert(0,5 , "A");
s2.insert(20, 35, "A");
assertEquals(0.0, method.Similarity(s1, s2));
}
}















 1217
1217











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









