






由于是一个虚拟机复制两次,作为三台主机使用,所以先在一个主机上安装完毕,然后再进行复制,不然到时候就无用功了
nginx 服务器的安装
同实验指导书
ping 检测
如果出现网络故障,检查VMWARE NetWork Adapter是否正常工作,

实验要求使用桥接模式,如果无法使用桥接模式,尝试以下博客
https://blog.csdn.net/qq_38093301/article/details/103429295
https://blog.csdn.net/qq_50698651/article/details/123997089
域名解析失败
dns 解析失败
https://blog.csdn.net/lsc_1893/article/details/118696693
这个也不好使啊
https://www.cnblogs.com/liongis/p/3265458.html
嗷,原来是因为主机名称的原因
**需要在 /etc/hosts 文件下 将 127.0.1.1 后面的名字改成master ,我无语
放弃了,但是现在我主机和我的虚拟机之间能够ping通了,那好办了,换种方式,使用xftp连接主机
xftp乱码
安装hadoop
前期配置
sudo gedit /etc/sudoers
添加 你本人的用户名
gkx1190201923 ALL=(ALL:ALL) ALL
设置主机名
- 修改 /etc/hostname 文件,master 节点的主机设置为master(那我就把我现在的这个主机设置为master就行了)
sudo gedit /etc/hostname

,其他两个虚拟机分别设置为slave1 ,
slave2 。
2. 修改/etc/hosts文件示例如下:
192.168.190.128 master
192.168.190.129 slave1
192.168.190.130 slave2
由于我还没有重启设置网卡,所以这个之后再做,先看看hadoop怎么安装吧
- 配置SSH免密码登录
- 首先安装ssh(使用whereis ssh 查看是否有ssh,发现有ssh)
sudo apt-get install ssh
进入根目录,并进入.ssh下
cd ~/.ssh
运行命令
sudo chown -R sam .ssh
发现提示无效的用户(我无语了,这实验不会是几年前的吧,我晕)
嗷,是因为用户无效的原因,看看这个用户应该怎么创建,新建一个名字为sam 的用户?算了,就用当前用户名称就创建成功了
生成RSA密钥对:
ssh-keygen -t rsa

一路回车就行
集群内共享密钥:
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
查看 authorized_keys 为:
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABgQCr5rd2EX9cNYdPypyagidtfa8bpwxqAlqKgd3hq7obvXRf7MWVswKF3sIJ/+yshKi7Ny/ZqzGPD5fubwRh2etdK6NqADPnQ6j+xIFVv9kjFvcWcUtRP5mXJb1UAKD205nJIJoMwQLJ7o4z9CBqDVjUotpfR+Cuq9PHMnwZ7gTRjvMvnPJPz4zbJcGcgVYVu8Vsyic1RvLk71SxxeIPHoGOBFEKv0j5/MdKkXwfyk1mLvBO209mBq1gxMWk3aZhGvzwab7axPONtmBajregh/EvCm65nVLolEF8ZxQqv6G5nKje4KUMNM3xWxSCDq0vCdO46UrGSfbIxA3iX40TSni4c6HlB65Wya0PBtpJi9D/YIEXNvnwu+8dzfVkh9KE6MI/kLqO+I5AqWi0SXhHA1PsxbYmsc9OX5Wvn7jyeTiv/aW4bY6lDOYiV5wHYkObghL2obJ8f623AbhaCTw1j7iRXFtuu7Buet84BvOvBoCG0TRegxe1gOKh1JmQoZAaDy8= gkx1190201923@master
欧克,用户名是我的用户名,然后master是我的主机名
配置slave1 和slave2 的节点,这个到时候再说,就是把这个authoriezed_keys复制到slave1和slave2中的.ssh/目录中就行,这个之后再确认
下载hadoop二进制文件
**注:**步骤2、 3、 4中除个别环节外,对各节点(master,slave1,slave2)的配置是相同的,建议在一个节点上完成2-4环节的配置后,采用克隆的方式复制出其他节点虚拟机,以节省时间(这个注解是实验快配置完了才告诉你,所以说啊,做实验得带脑子)
这里由于我虚拟机的桥接网络不好使,连不上外网,但与主机之间互相能ping通,所以我使用xftp进行连接
hadoop-3.2.3镜像网站下载

我是解压到了 ~/hadoop-3.2.3目录下
修改Hadoop安装目录/etc/hadoop/目录下的Hadoop-env.sh文件
cd ~/hadoop-3.2.3/etc/hadoop/
sudo gedit hadoop-env.sh
对照这两个文件,将其中的JAVA_HOME ,HADOOP_HOME ,PATH改成一样的


修改同目录下的core-site.xml文件如下

修改hdfs-site.xml文件以及mapred-site.xml文件

在进行Hadoop集群配置中,需要在"/etc/hosts"文件中添加集群中所有机器的IP与主机名,这样Master与所有的Slave机器之间不仅可以通过IP进行通信,而且还可以通过主机名进行通信。所以在所有的机器上的"/etc/hosts"文件中都要添加如下内容:
172.20.145.159 master
172.20.145.160 slave1
172.20.145.161 slave2
实验指导书狗都不看
一步步hadoop
配置三台主机的Hadoop文件
修改Hadoop安装目录/etc/hadoop/目录下的masters文件(新建一个masters文件)
gedit masters
修改文件内容为master
修改文件
gedit slaves
内容为
slave1
slave2
至此,主机的配置基本完成,现在进行虚拟机的复制,复制完成后要更改
修改slave1 ,slave2 中的/etc/hosts /etc/hostname 以及

修改完成后,使用
sudo netplan apply
命令,接受网络变化

查看主机名是否修改完成
正式开始nginx实验
由于我们已经配置好了我们的master主机上的nginx以及hadoop,所以我们可以进行虚拟机的复制,并设置基础的slave1,以及slave2.
检查主机之间的网络的联通性,
172.20.145.159 master
172.20.145.160 slave1
172.20.145.161 slave2
master ping slave1 slave2

slave1 ping master slave2

slave2 ping master slave1

由于我的slave1和slave2是直接对master的一个复制,猜测如果访问nginx应该是对应的master的主页(我对master 的nginx 主页没有进行更改)
修改nginx主页
查看文件/etc/nginx/sites-available 下的default

其中root /var/www/html 为nginx 初始页面,修改该html

另存为 index.html ,由于它位于debian.html之前,所以我们显示的应该是index.html ,修改后的显示效果如下
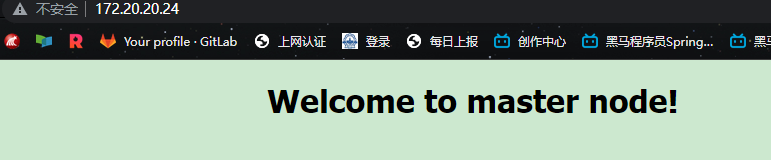
编辑负载均衡文件
首先编辑/etc/nginx/sites-available 下的default 文件,新增server 字段
server {
listen 8080;
server_name 192.168.3.36;
location / {
proxy_pass http://nodes; //请求转向nodes定义的服务器列表
include proxy_params; #需手动创建此文件
}
}
在同样的目录下创建 proxy_params
proxy_set_header Host $http_host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For
$proxy_add_x_forwarded_for;
proxy_connect_timeout 30;
proxy_send_timeout 60;
proxy_read_timeout 60;
proxy_buffering on;
proxy_buffer_size 32k;
proxy_buffers 4 128k;
在上级目录中修改nginx.conf文件,向其中添加upstream字段
upstream nodes {
server 172.20.20.25:8080;
server 172.20.20.26:8080;
}
别忘了修改/etc/hosts文件
配置两个节点的文件
如果主机重启,ip地址重新分配,需要记得重新修改/etc/netplan/ 下的配置文件
以及/etc/hosts
server{
listen 8080;
server_name 172.20.20.26;
location / {
root /var/www/html;
index node.html;
}
}

修改 /var/www/html/node.html 为:
<!DOCTYPE html>
<html>
<head>
<title>Welcome to slave1!</title>
<style>
body {
width: 35em;
margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif;
}
</style>
</head>
<body>
<h1>Welcome to slave1!</h1>
<h1>This is node 1</h1>
</body>
</html>
注意防火墙需要允许该端口号,我的系统是ubuntu 20.04,开放端口,重启防火墙的命令如下
sudo ufw allow 8080
sudo ufw reload
重启nginx
sudo nginx -s reload
访问该Ip:8080 结果

同理,设置slave2节点
访问结果:

最终负载均衡实现结果:

更改slave1,slave2 中的node.html 文件,内容分别修改为 slave1, slave2, 以便之后进行nginx测试负载均衡
使用apipost 软件,生成python request 脚本,进行测试:
python 脚本测试nginx
def process_bar(percent, start_str='', end_str='', total_length=0):
bar = ''.join(["\033[31m%s\033[0m"%' '] * int(percent * total_length)) + ''
bar = '\r' + start_str + bar.ljust(total_length) + ' {:0>4.1f}%|'.format(percent*100) + end_str
print(bar, end='', flush=True)
import requests
times = 10000
countSlave1 = 0
countSlave2 = 0
headers = {
'User-Agent': 'Apipost client Runtime/+https://www.apipost.cn/',
'Content-Type': 'application/json',
}
for i in range(times):
process_bar(i/times, start_str='',end_str='100%',total_length=15)
response = requests.get('http://172.20.20.24:8080/', headers=headers)
if(response.text=="slave1\n"):
countSlave1 +=1;
if(response.text=="slave2\n"):
countSlave2 +=1;
import matplotlib.pyplot as plt
import matplotlib
matplotlib.rcParams['font.sans-serif'] = ['SimHei']
matplotlib.rcParams['axes.unicode_minus'] = False
label_list = ["slave1", "slave2"] # 各部分标签
size = [countSlave1,countSlave2] # 各部分大小
color = ["red", "green"] # 各部分颜色
explode = [0.05, 0] # 各部分突出值
"""
绘制饼图
explode:设置各部分突出
label:设置各部分标签
labeldistance:设置标签文本距圆心位置,1.1表示1.1倍半径
autopct:设置圆里面文本
shadow:设置是否有阴影
startangle:起始角度,默认从0开始逆时针转
pctdistance:设置圆内文本距圆心距离
返回值
l_text:圆内部文本,matplotlib.text.Text object
p_text:圆外部文本
"""
patches, l_text, p_text = plt.pie(size, explode=explode, colors=color, labels=label_list, labeldistance=1.1, autopct="%1.1f%%", shadow=False, startangle=90, pctdistance=0.6)
plt.axis("equal") # 设置横轴和纵轴大小相等,这样饼才是圆的
plt.title("countSlave1 = "+str(countSlave1)+"\ncountSlave2 ="+str(countSlave2))
plt.legend()
plt.show()
测试结果(都为请求10000次)
1:1负载均衡

4:1 加权轮询
修改/etc/nginx/nginx.conf
重载nginx
nginx -s reload
upstream nodes {
server 172.20.20.25:8080 weight=4;
server 172.20.20.26:8080 weight=1;
}

ip绑定(ip_hash)
upstream nodes {
ip_hash;
server 172.20.20.25:8080;
server 172.20.20.26:8080;
}

由于这个负载均衡模式是每个请求按访问ip的hash结果分配,这样每个访客固定访问一个后端服务器,可以解决session的问题,在本机上进行测试则为ip地址不可变
热备
说明:backup是利用nginx的热备功能,这也是最典型的应用带来的重要好处之一,当非backup Server能够很好的为Client提供服务的时候,backup Server不对外界提供服务,此时backup Server处于冷状态;当所有非backup Server不能很好的为Client提供服务的时候,backup Server为Client提供服务,做到了热备,某台或者所有非backup Web Server宕机不会影响整个Web项目的访问功能,Web项目仍然可以为Client提供服务。
参数backup、max_fails和fail_timeout三者配合,可以用Nginx实现热备功能
使用slave1 作为backup 服务器,slave2 作为主请求服务器
upstream nodes {
server 172.20.20.25:8080 backup;
server 172.20.20.26:8080 max_fails=1 fail_timeout=9999999s;
}

推测timeout 时间设置的有点大,导致没有使用到backup,调低该参数为1s,结果还是一样的,down掉该服务器,进行测试(将slave2 的nginx挂掉)
sudo nginx -s stop

某个机器宕机,服务是否不可用?为什么?
可用,会负载到另一个服务器上,详见热备(如果是其他的负载均衡模式,则同热备)
请根据本步骤的实验对比,给出你对负载均衡算法的理解和认识
负载均衡算法是为了更好的分配服务器资源以及应对各种突发情况(如服务突然down,请求突然很多),
- 如果服务器的性能不均,可以分配不同的权重,进一步讲,权重和服务器性能成正比
- 如果用户数量较多,可以考虑使用ip_hash, 根据用户的不同的ip地址进行哈希,保证每个服务器的负载百分比差不多,但也有可能出现某个用户恶意攻击,这个时候应该设置其他参数来限制嘛?
- backup 热备设置,我认为是为了提升用户体验而存在的,如果请求某一服务器时间超过设定的阈值,则会转发到热备服务器上.
应用负载均衡技术改造遗留的进销存系统
假设:只考虑nginx 对于高并发的影响
- 支持海量用户高并发的场景
假设到达年货节,或者其他采购节日,进行大量的采购的时候,使用ip_hash 以及 加权轮询, 平均分配每个服务器的载荷,能有效提升用户的体验 - 设计细节
不使用负载均衡服务器的时候,所有用户的请求都将被发送到同一个Web服务器上,这样就会使得这个服务器的访问压力非常大。尤其在访问高发时间段,可能会导致服务器繁忙从而产生高延迟、无响应等现象。
通过对前面2种情况的对比可发现,使用负载均衡服务器可以将来自客户端的大量请求分摊到多个Web服务器上,从而缓解单个Web服务器的访问压力。
正式开始hadoop
测试是否可以通过ssh 进行免密连接
在master 主机上创建authorized_key
登录master 主机
由于我已经安装了java 环境以及系统自带的ssh ,所以这两步我跳过
为当前用户赋予权限:

cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
查看生成的authorized_keys

在slave1 和slave2 中创建目录~/.ssh
进入master 的~/.ssh 目录,使用
scp authorized_keys gkx1190201923@slave1:~/.ssh/

确认是否可以免密登录


gedit words 文件
输入
hello tom
hello kitty
hello world
hello tom
使用命令:
hadoop fs -put words hdfs://localhost:9000/input
出错:
Call From master/127.0.1.1 to localhost:9000 failed on connection exception: java.net.ConnectException: 拒绝连接; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
修改hosts文件后执行命令:
hadoop fs -put words hdfs://localhost:9000/input

终于搞好了
在我本机上访问主节点ip:9870端口,

下载该文件查看结果可得

下载飞鸟集
拷贝到同一目录下
hadoop fs -put Stray_Birds.txt hdfs://172.20.20.24:9000/stray_birds.input
hadoop jar hadoop-mapreduce-examples-3.2.3.jar wordcount hdfs://172.20.20.24:9000/stray_birds.input hdfs://172.20.20.24:9000/stray_birds.output

出现这种情况是因为域名解析错误,可以尝试在hosts主机里面添加域名解析,或者直接把域名改成ip地址

飞鸟集运行结果:

使用python生成假数据,用到了 faker 以及 numpy库
(改代码,如果想要最后count结果去重的话,还是命名为user i 把)
from faker import Faker
#导入Faker
fake = Faker()
print(fake.name())
import random
def random_num_with_fix_total(maxValue, num):
'''生成总和固定的整数序列
maxvalue: 序列总和
num:要生成的整数个数'''
a = random.sample(range(1,maxValue), k=num-1) # 在1~99之间,采集20个数据
a.append(0) # 加上数据开头
a.append(maxValue)
a = sorted(a)
b = [ a[i]-a[i-1] for i in range(1, len(a)) ] # 列表推导式,计算列表中每两个数之间的间隔
return b
tmp = random_num_with_fix_total(1000000, 10000)
name = []
for i in range(10000):
name.append(fake.name())
result = []
for i in range(10000):
for j in range(tmp[i]):
result.append(name[i]+" request")
import numpy as np
np.random.shuffle(result)
f = open("./jxc.txt","w",encoding = "utf8")
for i in range(1000000):
f.write(result[i]+"\n")
f.close()

最后输出结果概览:















 1398
1398











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









