






今天讲述如何基于docker搭建namenode及resourcemanger
先继续把容器规划上图:
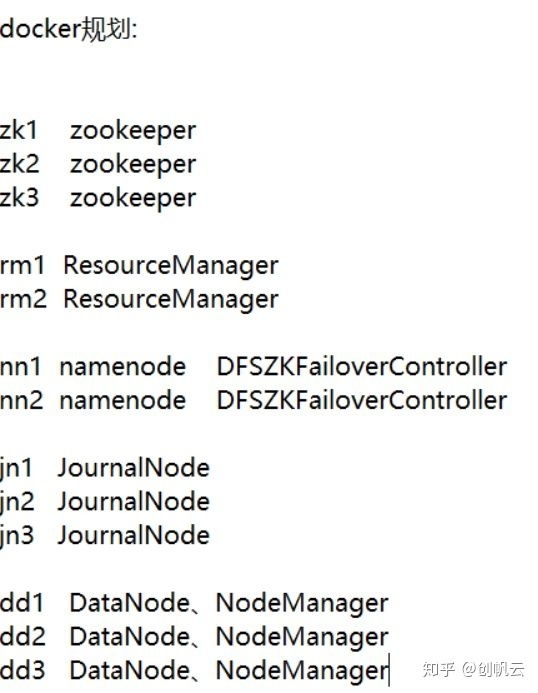
现在zookeeper已经搭建完了,接下来namenode和resourceManger思路一样
容器间通信、zookeeper搭建请参考上一篇文章
首先建立hadoop的一个基础容器
docker run -itd --name zk XXX /usr/sbin/init
XXX是镜像的名称,此镜像应该是之前已经制作好的镜像,里面包括了下载的SSH、hadoop3.0文件以及JDK
注意:镜像的环境变量需要提前配置好,参考如下:
vi ~/.bashrc
输入以下
#Hadoop 3.0
export HADOOP_HOME=/usr/local/hadoop-3.2.0
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_CONF_DIR=$HADOOP_HOME
export HADOOP_PREFIX=$HADOOP_HOME
export HADOOP_LIBEXEC_DIR=$HADOOP_HOME/libexec
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native:$JAVA_LIBRARY_PATH
export HADOOP_CONF_DIR=$HADOOP_PREFIX/etc/hadoop
export HDFS_DATANODE_USER=root
export HDFS_JOURNALNODE_USER=root
export HDFS_ZKFC_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export HDFS_NAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
不要问我为什么,就这么配(路径根据你实际安装的路径)
修改core-site.xml
<configuration> <!-- 指定hdfs的nameservice为ns1 --> <property> <name>fs.defaultFS</name> <value>hdfs://ns1</value> </property> <!-- 指定hadoop临时目录 --> <property> <name>hadoop.tmp.dir</name> <value>/hadoop/tmp</value> </property> <!-- 指定zookeeper地址 --> <property> <name>ha.zookeeper.quorum</name> <value>zk1:2181,zk2:2181,zk3:2181</value> </property> </configuration>
修改hdfs-site.xml
<configuration> <!--指定数据副本数量--> <property> <name>dfs.replication</name> <value>2</value> </property> <!--指定name数据存储路径--> <property> <name>dfs.namenode.name.dir</name> <value>/hadoop/name</value> </property> <!--指定data数据存储路径--> <property> <name>dfs.namenode.data.dir</name> <value>/hadoop/data</value> </property> <!--指定hdfs的nameservice为ns1,需要和core-site.xml中的保持一致 --> <property> <name>dfs.nameservices</name> <value>ns1</value> </property> <!-- ns1下面有两个NameNode,分别是nn1,nn2 --> <property> <name>dfs.ha.namenodes.ns1</name> <value>nn1,nn2</value> </property> <!-- nn1的RPC通信地址 --> <property> <name>dfs.namenode.rpc-address.ns1.nn1</name> <value>nn1:9000</value> </property> <!-- nn1的http通信地址 --> <property> <name>dfs.namenode.http-address.ns1.nn1</name> <value>nn1:50070</value> </property> <!-- nn2的RPC通信地址 --> <property> <name>dfs.namenode.rpc-address.ns1.nn2</name> <value>nn2:9000</value> </property> <!-- nn2的http通信地址 --> <property> <name>dfs.namenode.http-address.ns1.nn2</name> <value>nn2:50070</value> </property> <!-- 指定NameNode的元数据在JournalNode上的存放位置 --> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://jn1:8485;jn2:8485;jn3:8485/ns1</value> </property> <!-- 指定JournalNode在本地磁盘存放数据的位置 --> <property> <name>dfs.journalnode.edits.dir</name> <value>/hadoop/journaldata</value> </property> <!-- 开启NameNode失败自动切换 --> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> <!-- 配置失败自动切换实现方式 --> <property> <name>dfs.client.failover.proxy.provider.ns1</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行--> <property> <name>dfs.ha.fencing.methods</name> <value> sshfence shell(/bin/true) </value> </property> <!-- 使用sshfence隔离机制时需要ssh免登陆 --> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>~/.ssh/id_rsa</value> </property> <!-- 配置sshfence隔离机制超时时间 --> <property> <name>dfs.ha.fencing.ssh.connect-timeout</name> <value>30000</value> </property> </configuration>
——-修改mapred-site.xml,配置使用yarn框架执行mapreduce处理程序,与之前版本多了后面两部
不配置mapreduce.application.classpath这个参数mapreduce运行时会报错:
Error: Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.application.classpath</name> <value> $HADOOP_HOME/etc/hadoop, $HADOOP_HOME/share/hadoop/common/*, $HADOOP_HOME/share/hadoop/common/lib/*, $HADOOP_HOME/share/hadoop/hdfs/*, $HADOOP_HOME/share/hadoop/hdfs/lib/*, $HADOOP_HOME/share/hadoop/mapreduce/*, $HADOOP_HOME/share/hadoop/mapreduce/lib/*, $HADOOP_HOME/share/hadoop/yarn/*, $HADOOP_HOME/share/hadoop/yarn/lib/* </value> </property> </configuration>
修改yarn-site.xml
<configuration> </property> <!-- 开启RM高可用 --> <property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <!-- 指定RM的cluster id --> <property> <name>yarn.resourcemanager.cluster-id</name> <value>yrc</value> </property> <!-- 指定RM的名字 --> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <!-- 分别指定RM的地址 --> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>rm1</value> </property> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>rm2</value> </property> <!--指定当前机器使用id注意:拷贝到备用RM时,需要修改这里;其他的机器这里要删除掉--> <property> <name>yarn.resourcemanager.ha.id</name> <value>rm1</value> </property> <!-- 指定zk集群地址 --> <property> <name>yarn.resourcemanager.zk-address</name> <value>ha5:2181,ha6:2181,ha7:2181</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!--新版本添加--> <property> <name>yarn.resourcemanager.webapp.address.rm1</name> <value>rm1</value> </property> <property> <name>yarn.resourcemanager.scheduler.address.rm1</name> <value>rm1</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm2</name> <value>rm2</value> </property> <property> <name>yarn.resourcemanager.scheduler.address.rm2</name> <value>rm2</value> </property> </configuration>
——————–编辑workers,改为如下:
dd1
dd2
dd3
将配置好的hadoop基础容器提交为镜像
docker commit hadoop-base hadoop:base
再从该镜像创建如下容器:
nn1,nn2 –namenode节点
jn1,jn2,jn3 — journalnode节点
rm1,rm2 — yarn节点
dd1,dd2,dd3 — datanode节点
以其中一个启动命令为例,其他类似:
docker run -d --privileged=true -v /home/docker/hadoop/journalnode/jn1:/hadoop --name jn1 hadoop:base /usr/sbin/init
这是启动journalnode1容器的命令,其他的都一样,更改共享目录和容器名称就可以
启动所有容器后,登入nn1容器(namenode主节点)
格式化HDFS
#在nn1上执行命令: hdfs namenode -format #格式化后会在根据core-site.xml中的hadoop.tmp.dir配置生成个文件,这里我配置的是hadoop-2.4.1/tmp,然后将hadoop-2.4.1/tmp拷贝到nn2的hadoop-2.4.1/下。
//如果目标机存在目录,则先删除再SCP复制
rm -rf $HADOOP_HOME/tmp/
//进行复制
scp -r $HADOOP_HOME/tmp/ zhou@hadoop2:$HADOOP_HOME/
格式化ZKFC(在nn1上执行即可)
hdfs zkfc -formatZK
启动HDFS(在nn1上执行)
$HADOOP_HOME/sbin/start-dfs.sh
在rm1上启动yarn:
$HADOOP_HOME/sbin/start-yarn.sh
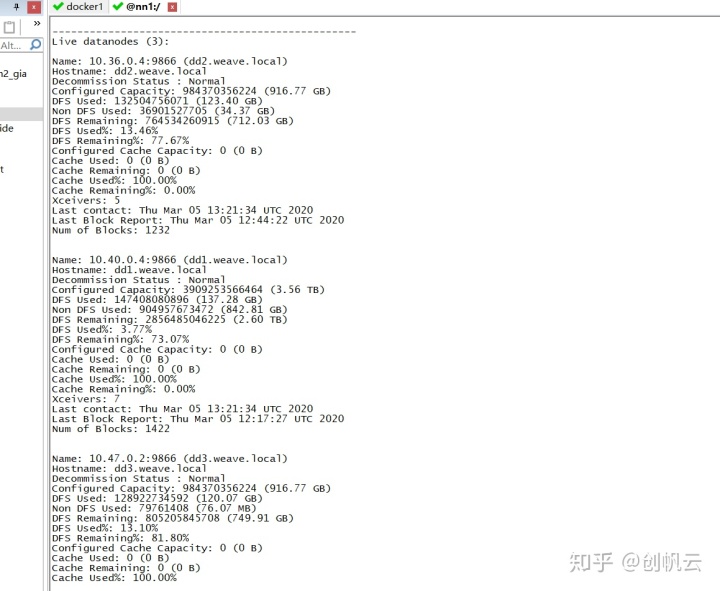
验证hdfs
在nn1上运行以下命令:
hdfs dfsadmin -report
如果和下图类似就成功
验证yarn: 在rm1上运行
运行一下hadoop提供的demo中的WordCount程序:
hadoop jar /usr/local/hadoop-3.2.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.0.jar wordcount /profile /out
如果能够启动成功,则yarn部署完成
到此,大功告成,下节讲述如何部署hbase
结尾发福利啦!免费云主机,下方链接领取:
免费云主机禁止转载,违者必究!














 415
415











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









