







VMworkstation下载地址 (64位)http://rj.baidu.com/soft/detail/13808.html?ald
附上永久密钥 5A02H-AU243-TZJ49-GTC7K-3C61N
附上本次安装中所有需要用到的文件,请提前下载
https://pan.baidu.com/s/1zdoGZjuvwQMZJzwQtCyfSQ
下文里执行的命令 cd 其实就是进入到 如图红框的目录下(当前lionel账户的home目录)

hadoop平台安装
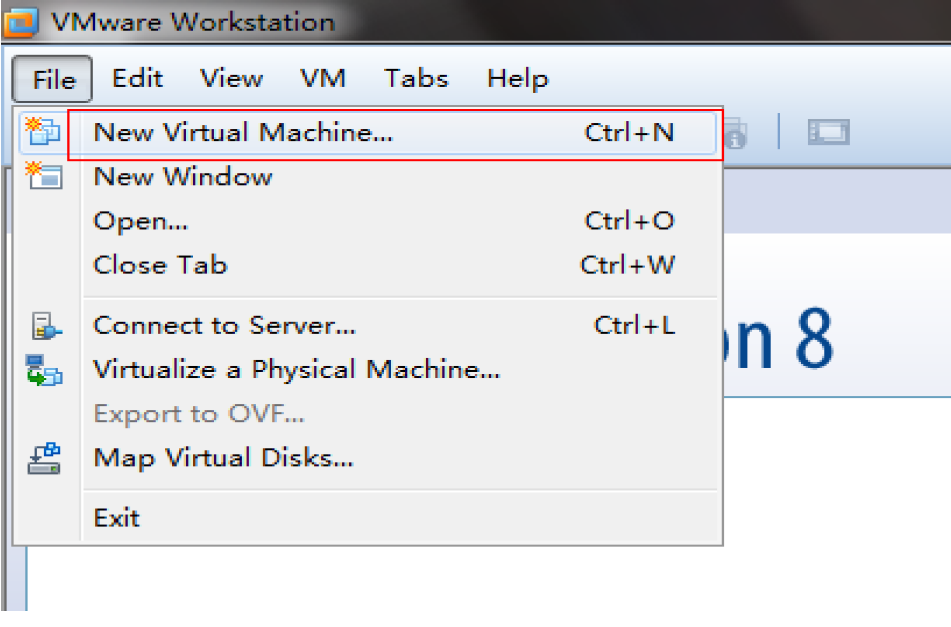
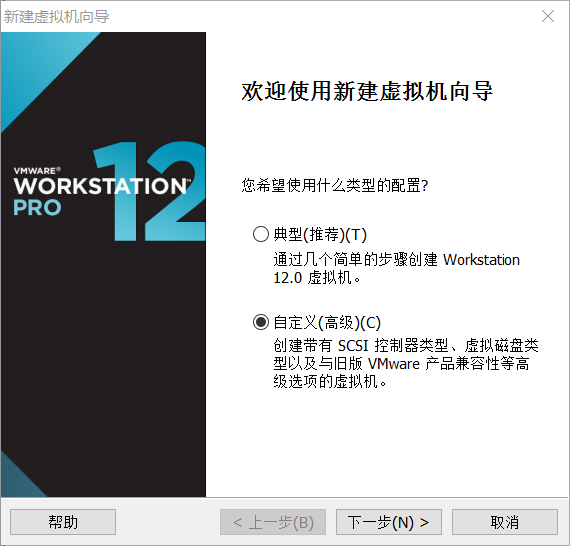
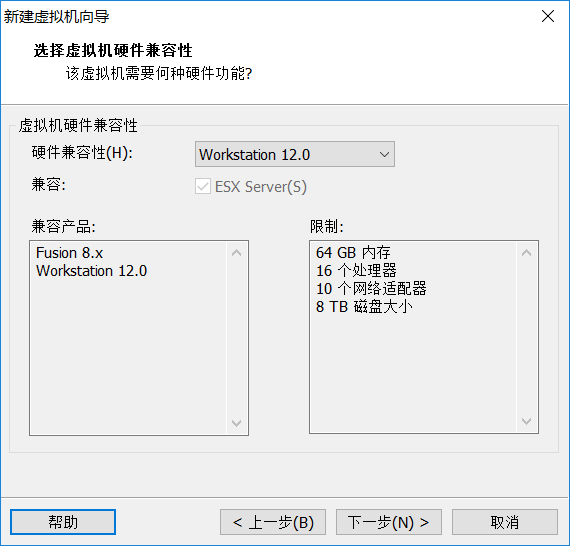
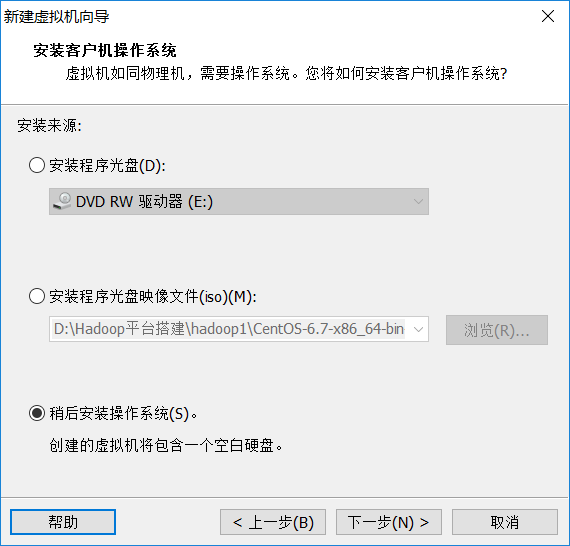
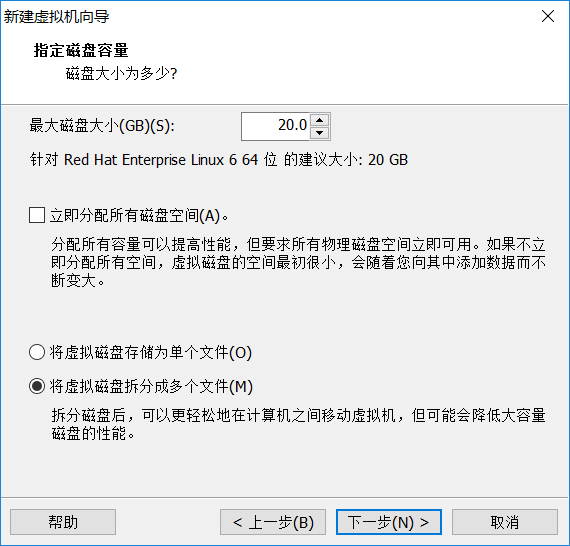
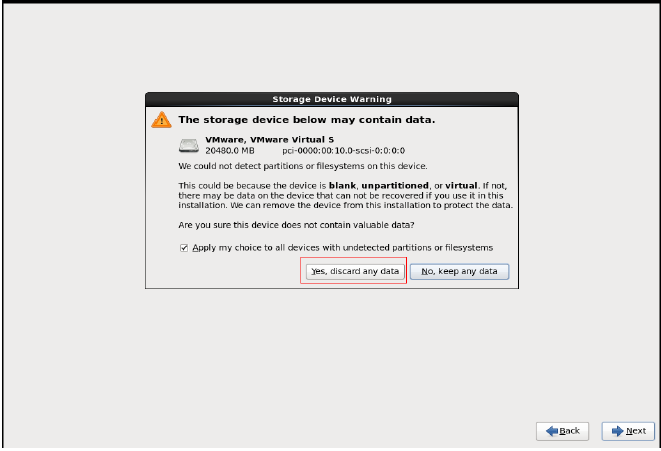
1新建虚拟机(因为hadoop需要运行在至少两台机器上,由于是自学,可以用VM虚拟出两台虚拟机,在其上运行hadoop。如果有足够的物理机,按照下文也一样的搭建平台)
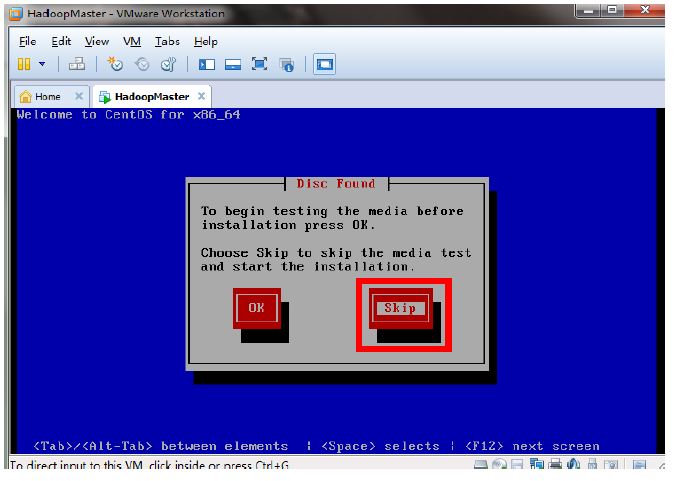
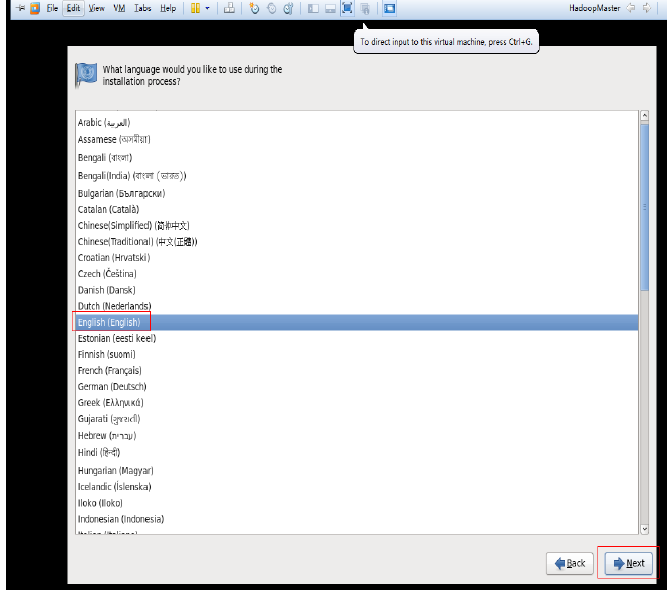
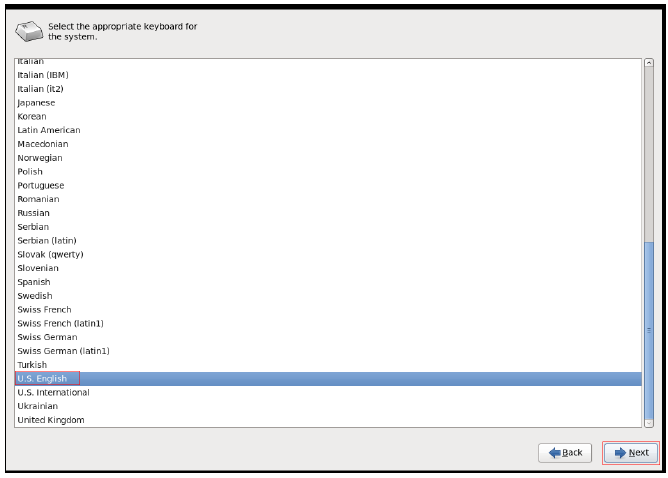
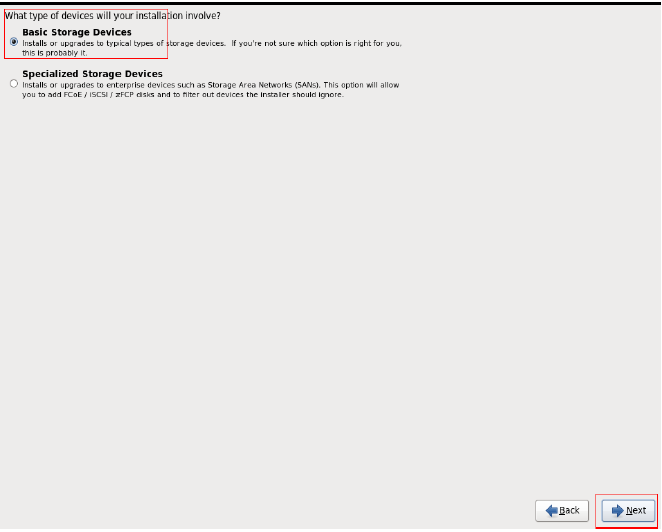
安装好VM12以后按图中设置新建虚拟机
未做特殊说明的,按照图中的设置直接下一步即可。
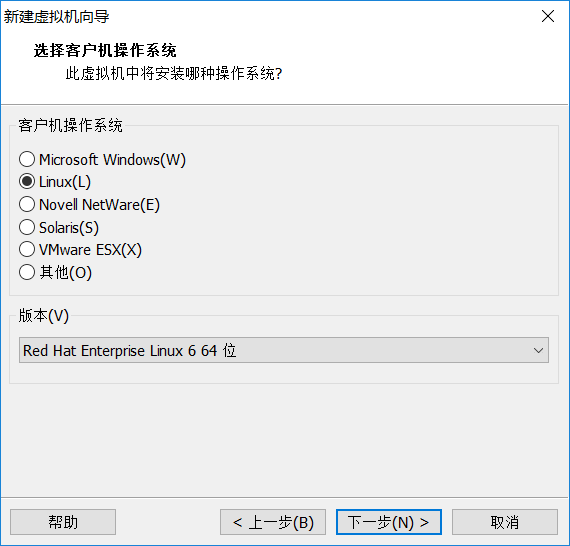
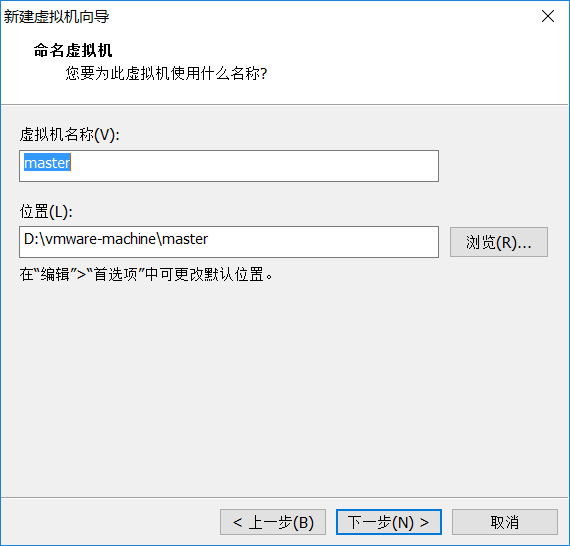
虚拟机的位置自己选择,名字自己选择
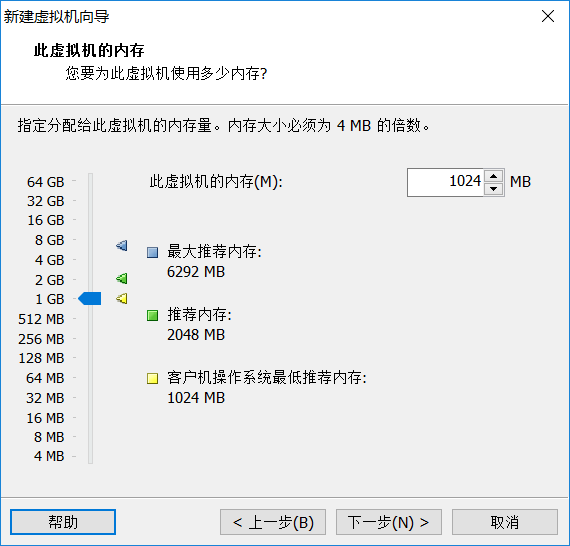
由于是笔记本这里建议是1G,如果自己机器配置可以的话,可以考虑2G
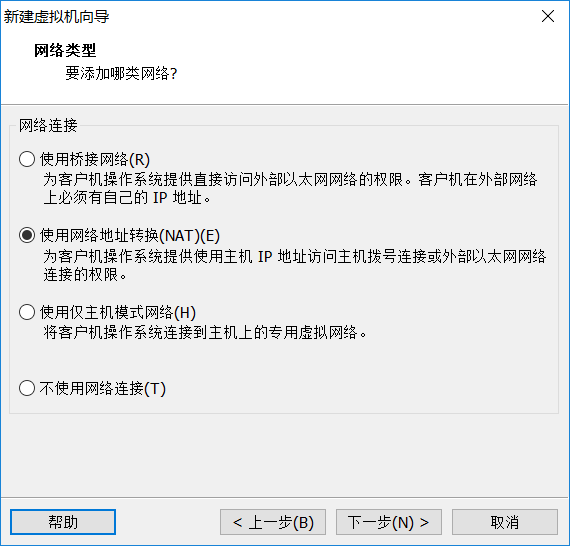
使用网络桥接模式
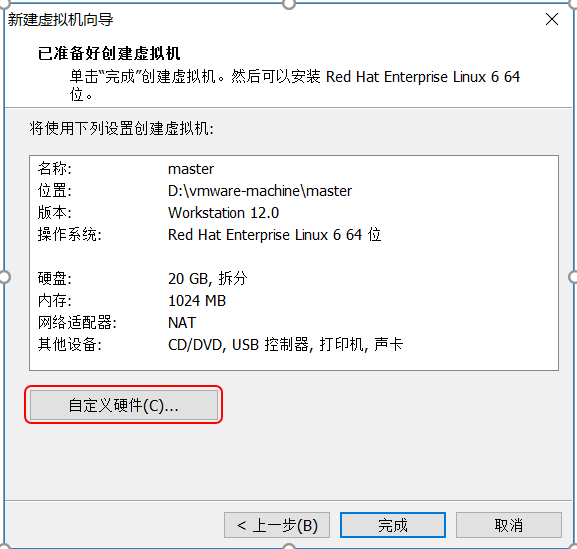
点击自定义硬件
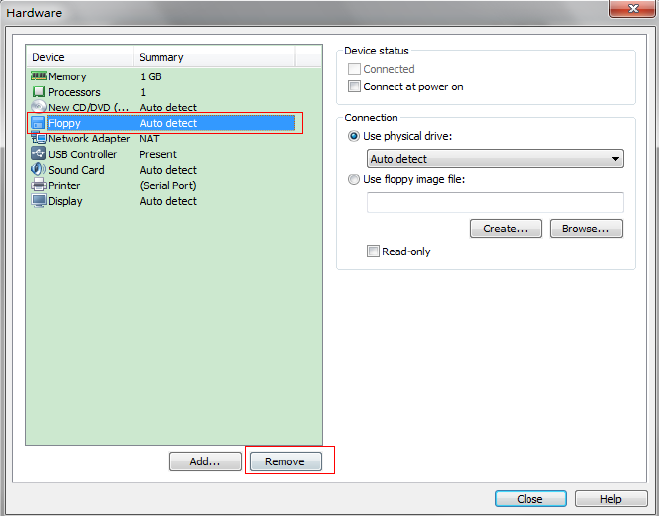
如果有软盘则删除软盘
浏览找到下载好的上面分享文件里的CentOS-6.7-x86_64-bin-DVD1光盘映像,然后关闭窗口
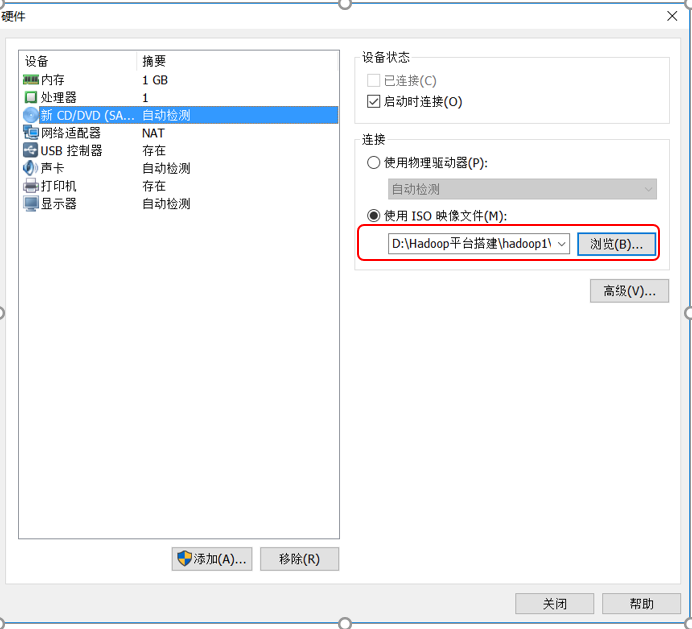
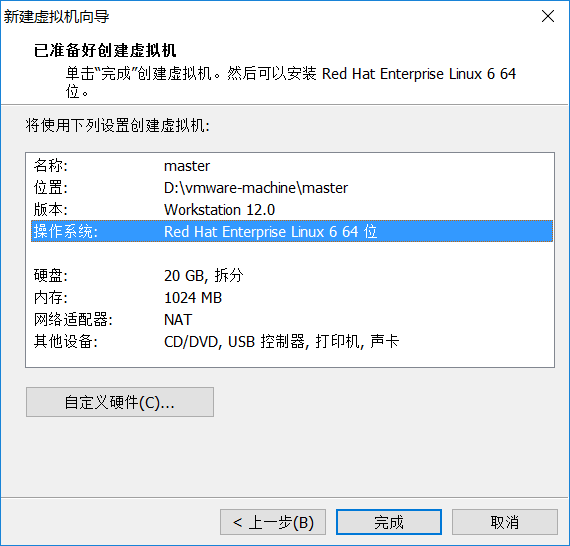
单击完成
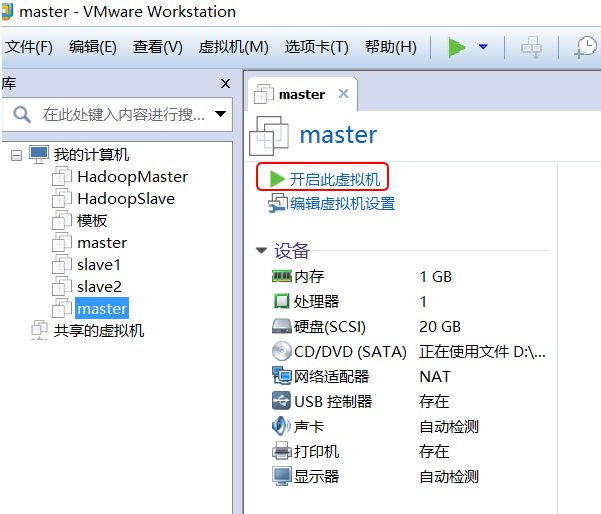
开启虚拟机

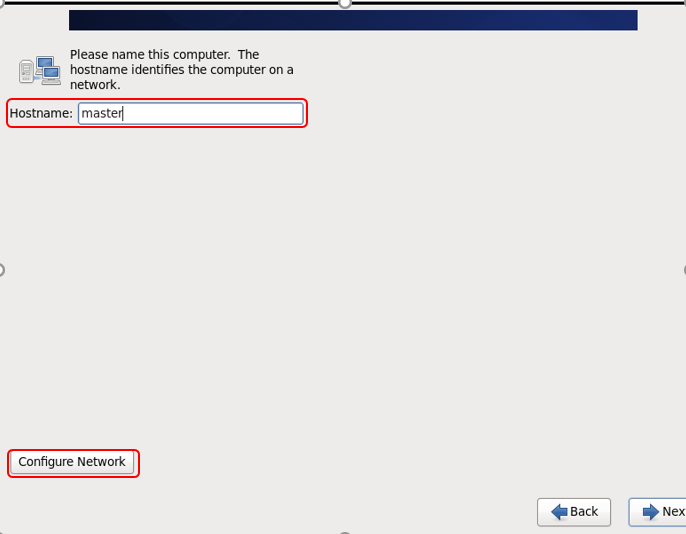
名字按照自己选的填,进入网络编辑
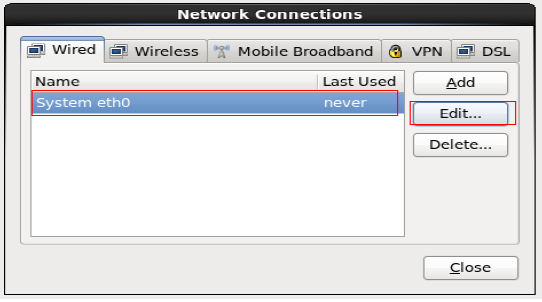
选择网卡开机自动连接,其他设置不用更改
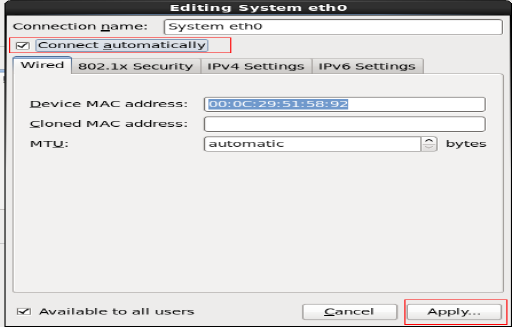
关闭窗口
继续next
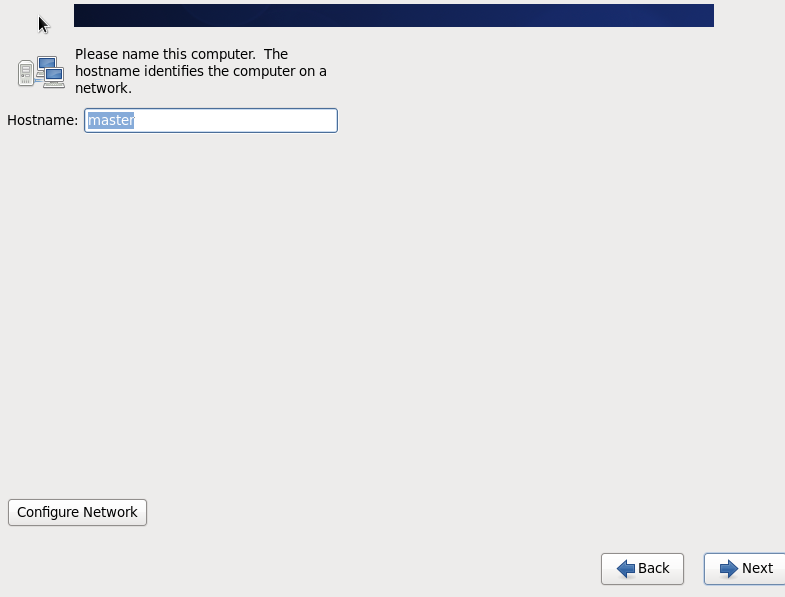
选择上海时区
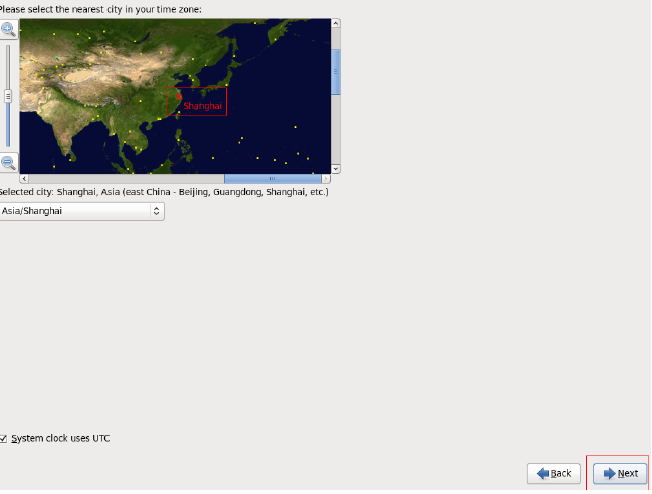
创建一个root账号
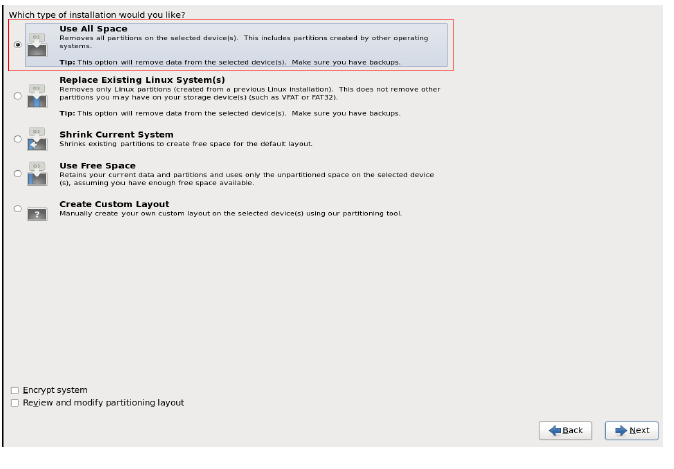
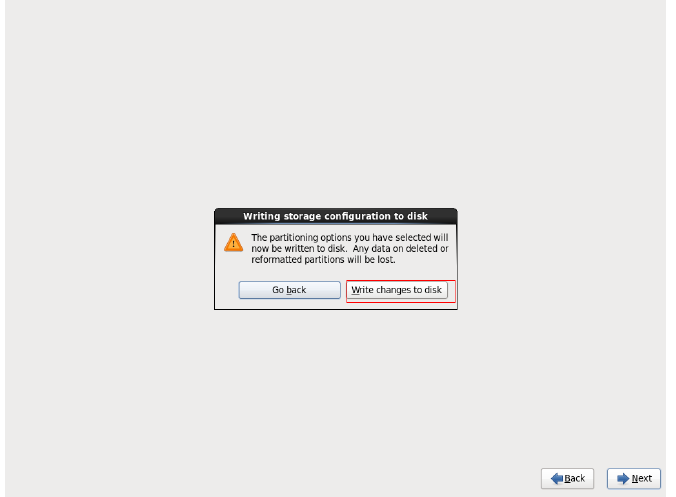
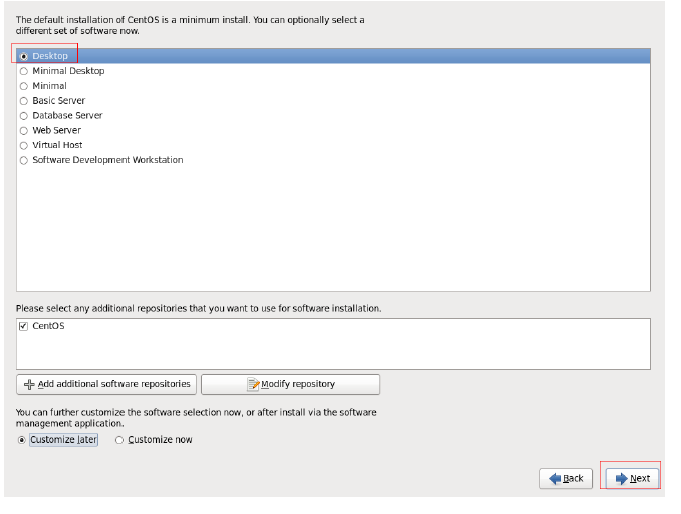
开始安装
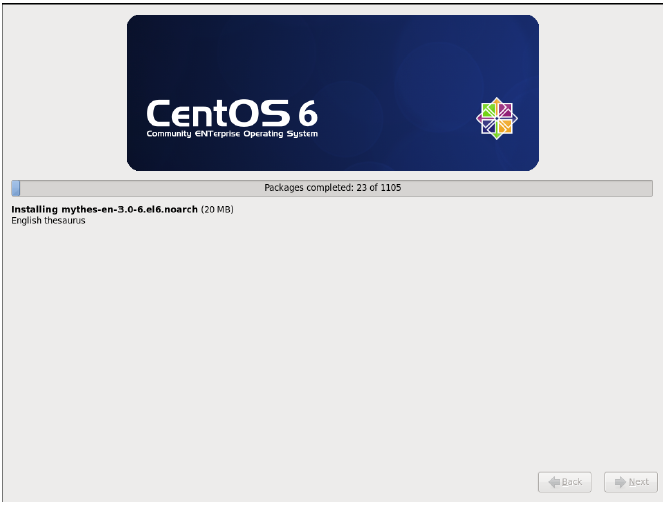
重启
点击forward

创建自己的独立账号,然后forward。我创建的账号名称是lionel,自选,所以下面的路径,home都是lionel
设置时间
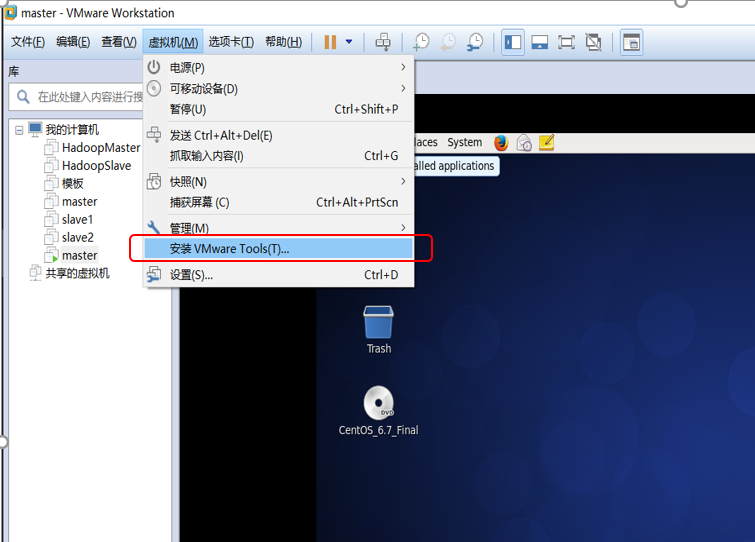
2安装VMtools,方便环境的搭建(后面会把物理机上的文件直接拖拽到虚拟机上)
这一步需要root权限才能执行,执行 su
然后输入你的root账号的密码
↓
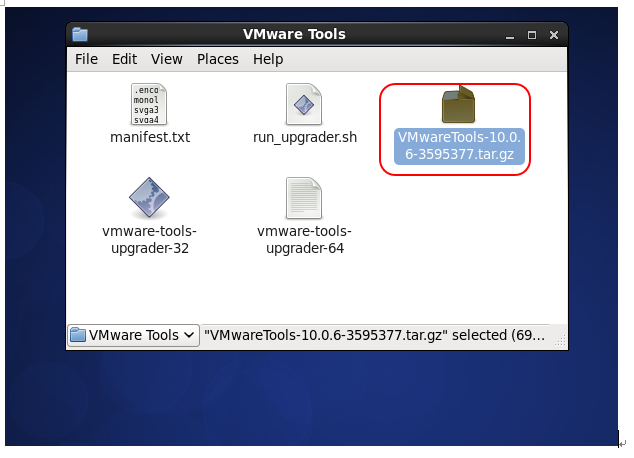
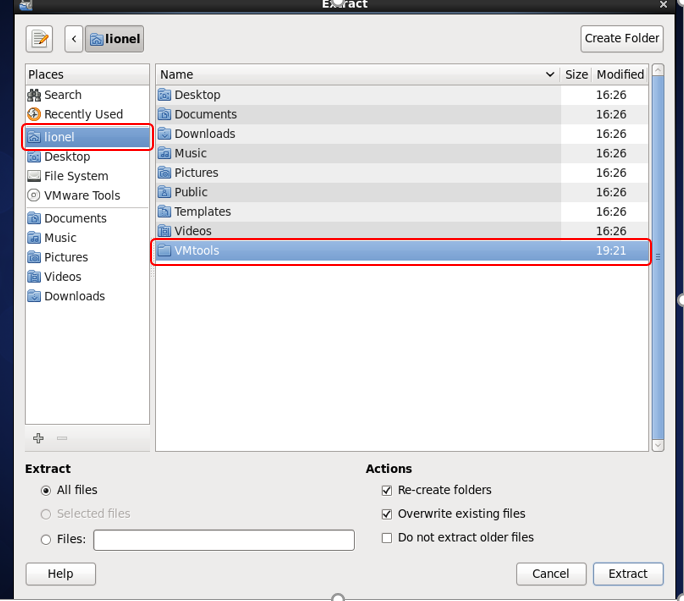
[root@master ~]# mkdir /home/lionel/VMtools然后会弹出一个窗口,解压里面的vmtools压缩包,到你指定的目录,我在/home/lionel下新建了一个目录
VMtools 目录,路径如图。(右键,解压到,Extract to)
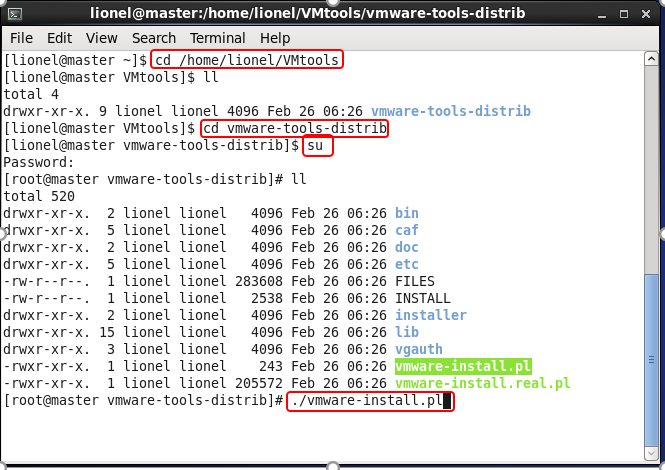
打开一个终端进入解压文件的目录下
我这里是输入命令
cd /home/lionel/VMtools↓
然后
cd vmware-tools-distrib↓
执行安装文件
./vmware-install.pl一路回车,安装完后再输入 reboot 重启一下虚拟机就可以了,新装的vmtools可能有点卡顿,重启后需要等一会才可以与物理机分享文件。
3卸载系统自带JDK,安装较为稳定的sun jdk
(这一步需要root权限,才能执行)
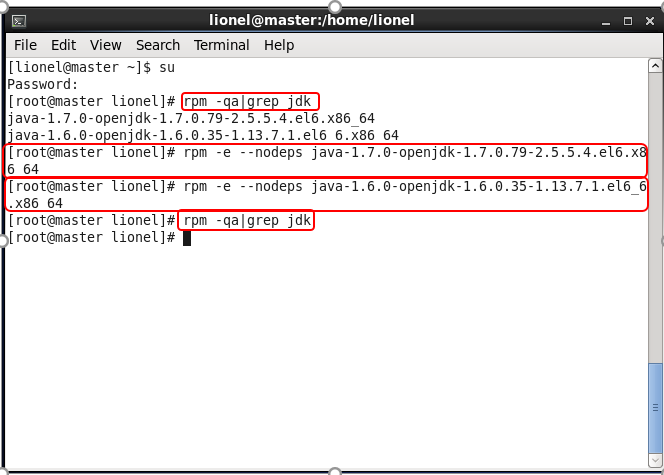
执行 su 输入密码
↓
执行 rpm -qa|grep jdk 查看jdk版本信息
↓
执行
rpm -e --nodeps java-1.6.0-openjdk-1.6.0.35-1.13.7.1.el6_6.x86_64
rpm -e --nodeps java-1.7.0-openjdk-1.7.0.79-2.5.5.4.el6.x86_64卸载系统自带的jdk
(rpm -e –nodeps 你的jdk名称)
↓
然后再次执行 rpm -qa|grep jdk 查看是否卸载完成,如果为输出任何信息,表示卸载完成
安装sum jdk
从上文中的分享文件里,下载jdk-7u71-linux-x64.gz,并放到虚拟机桌面上
↓
新建目录存放jdk(你也可以选择别的目录,不过以后的环境配置也要改成相应的路径) mkdir /usr/java
↓
把桌面上的jdk移动到新建的java目录下
mv /home/lionel/Desktop/jdk-7u71-linux-x64.gz /usr/java↓
进入目录
cd /usr/java↓
解压缩
tar -xvf /usr/java/jdk-7u71< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 423
423

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









