






在数字化教育日益普及的今天,我们时常需要在电子试卷和纸质试卷之间进行转换。然而,许多时候我们并不需要答案部分,这就需要我们掌握一些工具来去除答案,以便打印出纯净的试卷。本文将为您详细介绍如何使用试卷星、拍试卷以及WPS Office三款软件,轻松去除答案,实现高效打印。

一、试卷星
这款强大的试卷制作软件,不仅可以帮助教师快速制作试卷,还提供了答案去除功能。使用试卷星去除答案的步骤如下:
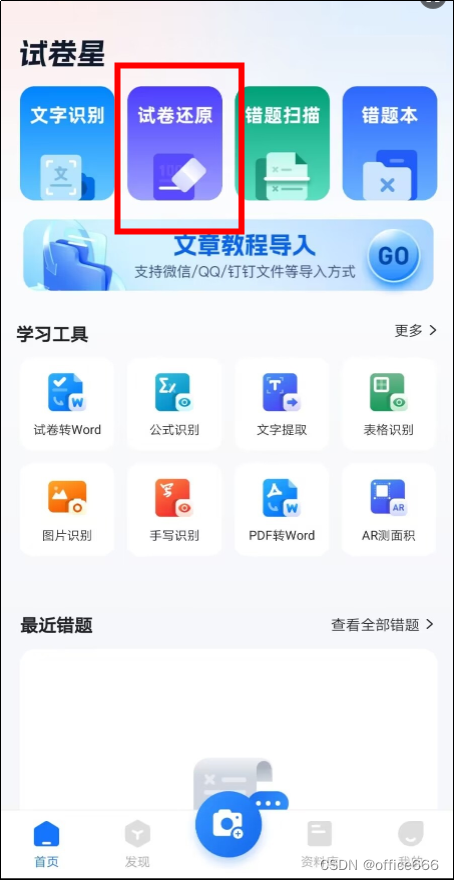
- 打开试卷星软件,在页面右上角找到“试卷还原”选项并点击。
- 导入需要去除答案的试卷。您可以通过扫描或拍照的方式将试卷导入软件。
- 导入试卷后,软件会自动识别试卷内容。此时,您可以选择不同的年级和学期进行分类,以便更好地管理试卷。
- 在识别结束后,软件会提供答案去除的选项。您只需点击该选项,软件便会自动将答案部分隐藏起来,只显示题目和选项。
- 最后,您可以轻松地将去除答案后的试卷打印出来,供学生使用。
- 拍试卷
这款软件以其简单易用的特点,赢得了广大用户的喜爱。使用拍试卷去除答案的步骤如下:
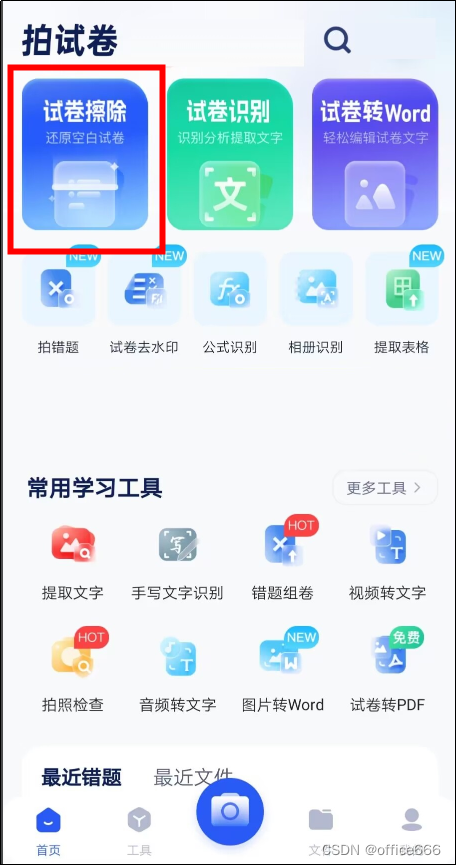
- 打开手机或扫描仪,将试卷放置在合适的位置。
- 打开拍试卷软件,对试卷进行拍照或扫描。
- 软件会自动识别试卷内容,并将答案部分进行去除。
- 您可以在软件内对去除答案后的试卷进行预览和调整,确保试卷的准确性和清晰度。
- 最后,将去除答案的试卷保存并打印出来即可。
- WPS Office
虽然WPS Office主要用于文档处理、表格制作和幻灯片制作等功能,但它同样可以帮助我们去除试卷中的答案。使用WPS Office去除答案的步骤如下:
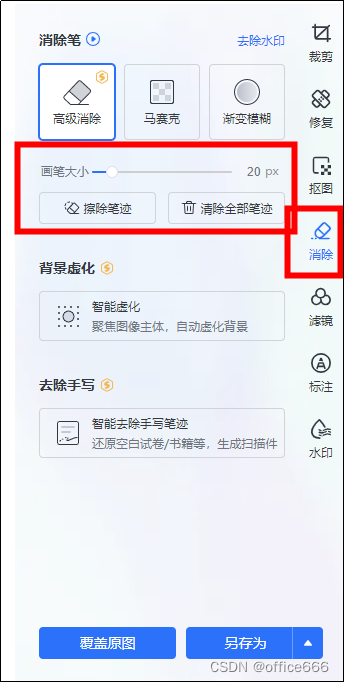
- 打开WPS Office软件,导入需要去除答案的试卷图。
- 使用WPS Office的图片功能,点击工具栏中的“消除”选项。
- 点击“清楚全部笔迹”按钮,软件会自动将文档中的答案去除。
- 最后,保存并打印去除答案后的试卷文档。
通过以上三款软件的操作步骤介绍,相信您已经掌握了如何轻松去除答案并打印纯净试卷的方法。在实际应用中,您可以根据自己的需求和习惯选择合适的软件进行操作。无论是试卷星、拍试卷还是WPS Office,它们都能帮助您高效地处理试卷,提升工作效率和学习体验。















 531
531











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









