






Chapter 1 - Meet ANTLR
本书Part I中,我们的目标是对ANTLR的能力有一个整体的认知,并尝试探索语言应用框架。一旦我们有了整体的概念,我们接下来就会在Part II 中通过大量的真实案例系统学习ANTLR。本书开始,我们要先安装ANTLR,然后尝试制作一个简单的“hello world”的grammer。
1.1 安装ANTLR
ANTLR是用Java编写的,所以在开始使用之前需要有完整的Java环境。ANTLR需要Java version 1.6或者更高。本章内容的的实时更新可见ANTLR的Github主页。
为什么这本书使用命令行工具?
在整本书中,我们会使用命令行(shell)运行ANTLR以及构建我们的应用。由于编程人员会使用不同的操作系统以及开发环境,操作系统的shell是我们唯一共同使用的“interface”。使用shell能够使得语言应用开发和构建过程的每一步变得更加明确。本书中我会一一直使用Mac OS X系统的Shell,不过使用的命令应该在Unix及Unix-like的shell中也能使用,在Windows系统中可能有一些细微的不同。
安装ANTLR本身其实仅仅就是下载最新的jar包,当前的jar包(这是本书写时最新的jar包,建议读者也下同样的包)是antlr-4.0complete.jar,将其下载并放到合适位置。这个jar包包含了运行ANTLR tool以及编译和执行由ANTLR生成的recognizers所需要的runtime library。在命令行中,ANTLR tool能够将识别grammar定义的语言的语句,将grammars转换成programs。比如,给定一个JSON的grammar,ANTLR tool能够使用ANTLR runtime library中的相关支持类,生成一个能够解析JSON输入流的程序。
这个jar包也包含了两个支持库:一个复杂树布局库(sophisticated tree layout library),以及一个StringTemplate。后者是用于生成代码和其它结构化文本的模板引擎。在version 4.0中,ANTLR仍然是在ANTLR v3中写的,所以这个jar包也包含了之前版本的ANTLR。
The StringTemplate Engine
StringTemplate 是一个用于生成源代码,网页,邮件或者任何格式化文本的Java模板引擎(with ports for C#, Python, Ruby, and Scala)。在多目标代码生成器,多种网站外观,以及国际化/本地化中尤为擅长。jGuru.com这个网站的构建过程一直在使用它。StringTemplate也为ANTLR v3和v4的code generators提供了大力的支持。更多信息可见About页面。
你可以从ANTLR网站通过浏览器手动下载ANTLR,或者在命令行中使用curl工具抓取它。
cd /usr/local/lib
curl -0 http://www.antlr.org/download/antlr-4.0-complete.jar在Unix中,/usr/local/lib是存储jar包的比较合适的目录。在Windows系统中,没有相关的建议,所以你可以将其简单存储在你的工程目录中。大多数的开发环境希望你能将你的jar包放到你的应用工程的依赖列表中。对于ANTLR来说,不需要配置脚本和配置文件,你只需要确保Java能够检测到该jar包即可。
由于本书通篇都在使用命令行,所以或许你有必要通过设置CLASSPATH环境变量以方便命令调用。在Unix系统中,你可以在shell中执行一下的命令,或者将其放到开机自动执行的脚本中(.bash_profile等等):
export CLASSPATH=".:/usr/local/lib/antlr-4.0-complete.jar:$CLASSPATH"设置好以后,可以通过直接运行不携带参数的ANTLR tool确保安装是否成功。有以下两种方式:
$ java -jar /usr/local/lib/antlr-4.0-complete.jar # launch org.antlr.v4.Tool
ANTLR Parser Generator Version 4.0
-o ___ specify output directory where all output is generated
-lib ___ specify location of .tokens files
...
$ java org.antlr.v4.Tool # launch org.antlr.v4.Tool
ANTLR Parser Generator Version 4.0
-o ___ specify output directory where all output is generated
-lib ___ specify location of .tokens files
...每次运行ANTLR的时候都使用上面的命令无疑是很痛苦的,因此我们最好使用alias命令或者写一个脚本。在本书中,我们使用alias命令定义antlr4:
$ alias antlr4='java -jar /usr/local/lib/antlr-4.0-complete.jar'然后,就可以用antlr4代替上面的java命令了:
$ antlr4
ANTLR Parser Generator Version 4.0
-o ___ specify output directory where all output is generated
-lib ___ specify location of .tokens files
...1.2 执行ANTLR以及测试Recognizers
下面是一个简单的grammar,能够理解像“hello world”这样的语句:
grammar Hello; // Define a grammar called Hello
r : 'hello' ID ; // match keyword hello followed by an identifier
ID : [a-z]+ ; // match lower-case identifiers
WS : [ \t\r\n]+ -> skip ; // skip spaces, tabs, newlines, \r (Windows)我们将这个grammar文件Hello.g4放到自己的目录下,比如tmp/test。然后我们能在其中运行ANTLR,并且编译结果。
$ cd /tmp/test
$ # copy-n-paste Hello.g4 or download the file into /tmp/test
$ antlr4 Hello.g4 # Generate parser and lexer using antlr4 alias from before
$ ls
Hello.g4 HelloLexer.java HelloParser.java
Hello.tokens HelloLexer.tokens
HelloBaseListener.java HelloListener.java
$ javac *.java # Compile ANTLR-generated code对Hello.g4文件执行ANTLR tool会生成一个由HelloParser.java和HelloLexer.java生成可执行的recognizer,但是我们没有一个main program来触发对语言的识别(下一个chapter中我们会学习到什么是parsers和lexers)。在构建实际应用之前,你可能会使用几个不同的grammars。因此不对每一个新生成的grammar都生成一个main program是比较好的行为。
这里理解没有man program,应该就是生成的java文件中,都没有包含main方法的意思吧。
ANTLR在runtime library中提供了一个灵活的测试工具,叫TestRig。它能够输出很多和recognizer如何匹配输入文本相关的有用的信息,TestTig使用Java的反射机制调用表一号的recognizers。和之前相似,此时最好用alias命令简化以下TestRig的调用:
$ alias grun='java org.antlr.v4.runtime.misc.TestRig'这个测试命令需要一个grammar名作为参数,一个rule名,以及指明输出相关的参数。在本例中,我们想输出在recognition期间创建的tokens。tokens是像keyword “hello”和identifier “part”这样的词汇符号(vacabulary symbols):
➾ $ grun Hello r -tokens # start the TestRig on grammar Hello at rule r
➾ hello parrt # input for the recognizer that you type
➾ EOF # type ctrl-D on Unix or Ctrl+Z on Window
❮ [@0,0:4='hello',<1>,1:0] # these three lines are output from grun
[@1,6:10='parrt',<2>,1:6]
[@2,12:11='<EOF>',<-1>,2:0]在输入grun命令,回车进入新的一行后,计算机会静默等待你的符合“hello parrt”类型的输入。其后,需要输入文件终止符来结束本次输入,否则命令行会一直等待下去。一旦recognizer已经读进来了所有的输入,由于使用了-tokens参数,TestRig会打印出使用tokens的列表。
输出的每一行都表示一个单独的token被使用,并且会显示我们对该token所知的所有信息。比如,[@1,6:10='parrt',<2>,1:6],按照顺序其表示意义如下:
- @1 —— 这是第二个token,token下标从0开始。
- 6:10 —— 这个token是从第6个字符到第10个字符(字符下标冲0开始,包括6和10。)。
- =’parrt’ —— 这个token的文本是parrt。
- <2> —— 这个token的type是2(ID)。
- 1:6 —— 这个token出现在输入文本的第一行(行数从第1行开始数),起始位置字符是6(起始位置字符下标从0开始,将tabs看作单个字符)。
我们也能以LISP风格的文本格式打印这个解析树:
➾ $ grun Hello r -tree
➾ hello parrt
➾ EOF
❮ (r hello parrt)最方便查看一个grammar如何recognize输入的方法是在可视化的解析树中查看。使用-gui参数可以做到。命令是:
$ grun Hello r -gui然后会生成下述的图形框:
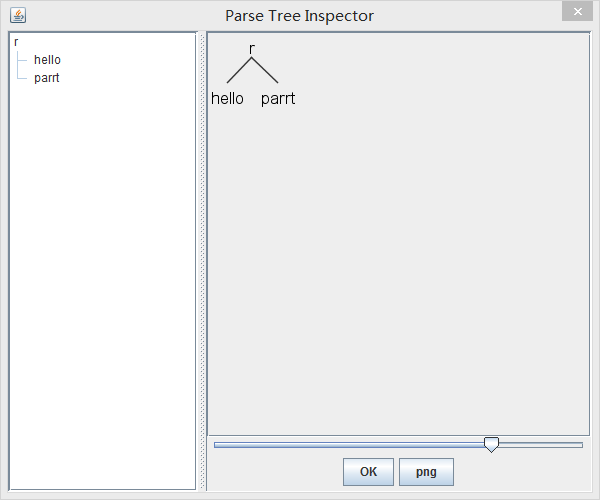
不使用任何参数运行TestRig,会打印一些帮助信息:
$ grun
java org.antlr.v4.runtime.misc.TestRig GrammarName startRuleName
[-tokens] [-tree] [-gui] [-ps file.ps] [-encoding encodingname]
[-trace] [-diagnostics] [-SLL]
[input-filename(s)]
Use startRuleName='tokens' if GrammarName is a lexer grammar.
Omitting input-filename makes rig read from stdin.在本书中,我们主要使用的参数及其简单解释如下:
- -tokens —— 打印token流
- -tree —— 以LISP风格打印解析树
- -gui —— 在对话框中显示解析树
- -ps file.ps —— 以PostScript方式生成解析树的可视化表现,并存储在
file.ps中。本chapter中解析树的图是由-ps生成的。 - -encoding encodingname —— 指定输入文件的编码格式。
- -trace —— 打印rule名以及当前的token,并且退出。
- -diagnostics —— 在解析过程中打开诊断信息。这会为不常见的场景生成详细,比如会引起歧义的短语。
- -SLL —— 使用一个更快,功能更弱的解析策略。















 590
590

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









