







一、视频异常检测
1.1 Exploiting Completeness and Uncertainty of Pseudo Labels for Weakly Supervised Video Anomaly Detection
利用伪标签的完整性和不确定性实现弱监督视频异常检测
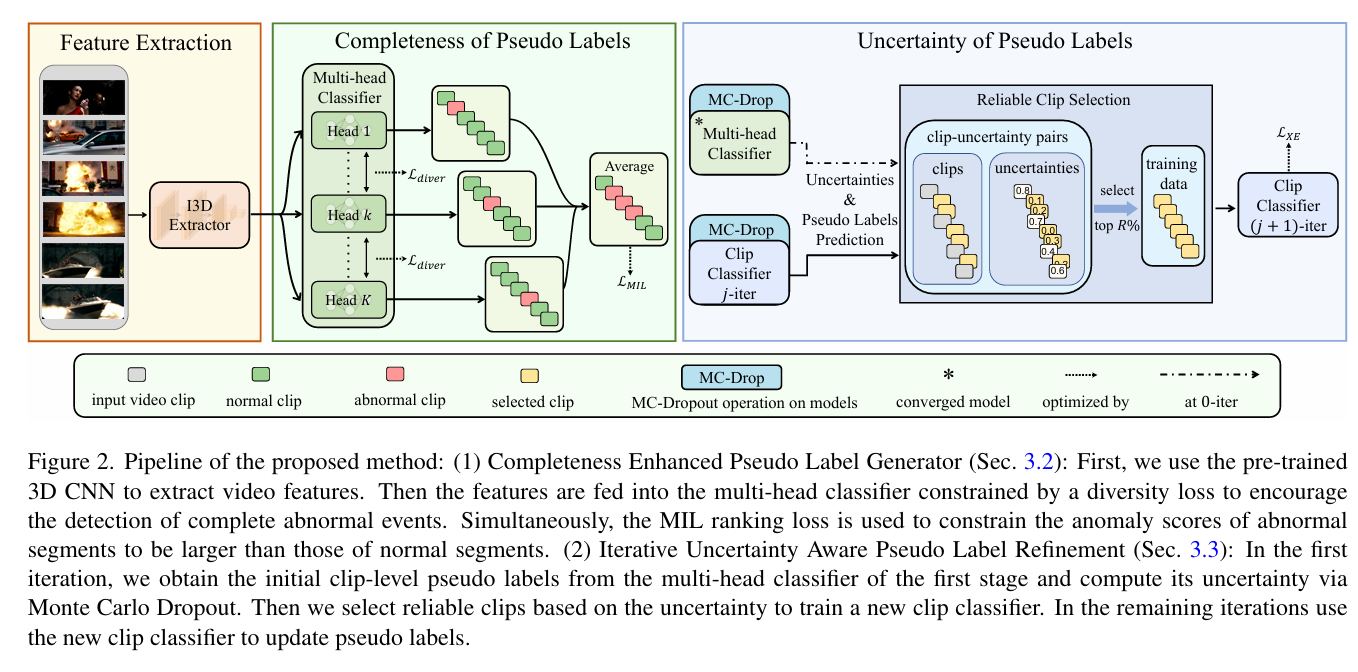
摘要: 弱监督视频异常检测旨在仅使用视频级标签来识别视频中的异常事件。最近,两阶段自训练方法取得了显著进展,即生成伪标签并利用这些伪标签完善异常分数。由于这些伪标签起着关键作用,我们提出一种增强框架,通过利用完整性和不确定性属性来实现有效的自训练。具体而言,我们首先设计了一个多头分类模块(每个头充当一个分类器),具有多样性损失,以最大限度地扩大预测伪标签之间的分布差异。这有助于生成尽可能多的作为异常事件的伪标签。然后,我们设计了一种迭代不确定性伪标签细化策略,它不仅改进了初始伪标签,还改进了在第二阶段由所需分类器获得的更新伪标签。大量实验结果表明,所提出的方法在 UCF - Crime、TAD 和 XD - Violence 基准数据集上的表现优于现有方法。
1.2 Look Around for Anomalies: Weakly-Supervised Anomaly Detection via Context-Motion Relational Learning
环顾四周找异常:通过上下文 - 运动关系学习实现弱监督异常检测
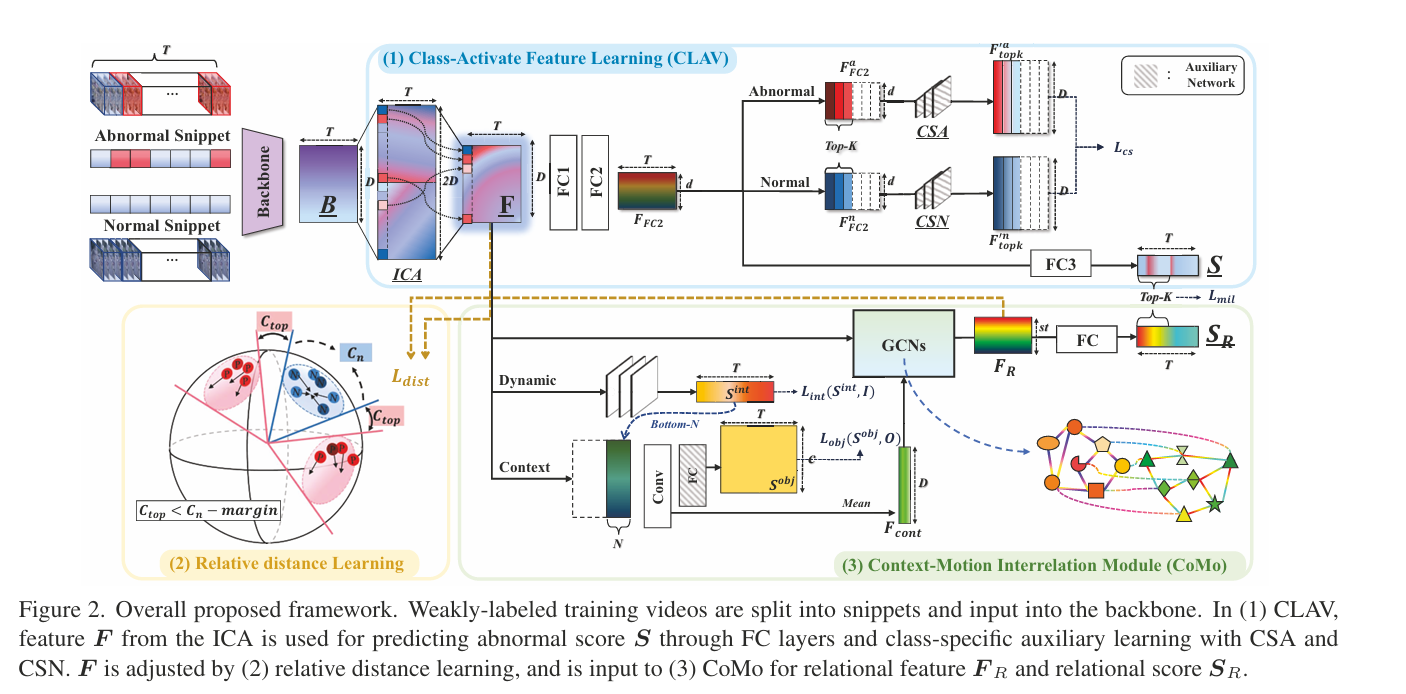
摘要: 弱监督视频异常检测是利用视频级标注的训练数据来检测帧级异常的任务。仅通过单个主干分支,利用弱标签的极少监督来探索类别代表性特征是很困难的。此外,在现实场景中,正常与异常之间的界限是模糊的,并且会因具体情况而异。例如,即使是同一个人跑步的动作,其异常与否也会因周围环境是操场还是道路而有所不同。因此,我们的目标是通过扩大单个分支中类别特征之间的相对差距,来提取具有判别性的特征。在提出的类别激活特征学习(CLAV)方法中,特征根据权重进行提取,该权重会隐式激活类别,并且通过相对距离学习来扩大差距。此外,由于上下文与运动之间的关系对于识别复杂多样场景中的异常至关重要,我们提出了上下文 - 运动关联模块(CoMo),该模块对周围环境外观与运动之间的关系进行建模,而不是仅利用运动的时间相关性。所提出的方法在包括大规模真实世界数据集在内的四个基准数据集上展现出了领先的性能,并且我们通过分析定性结果和泛化能力,证明了关系信息的重要性。
1.3 Unbiased Multiple Instance Learning for Weakly Supervised Video Anomaly Detection
用于弱监督视频异常检测的无偏多示例学习
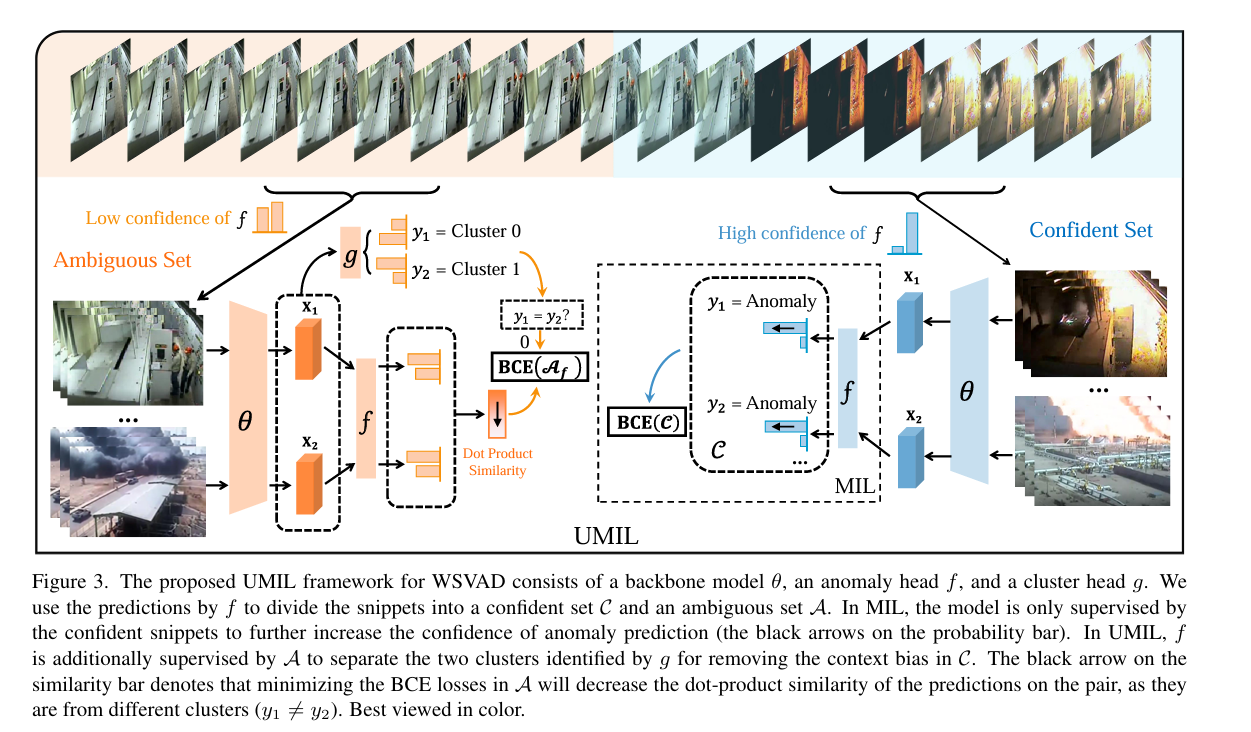
摘要: 弱监督视频异常检测(WSVAD)颇具挑战性,因为二元异常标签仅在视频级别给出,而输出却要求是片段级别的预测。因此,多示例学习(MIL)在 WSVAD 中应用广泛。然而,众所周知,MIL 存在大量误报问题,原因在于片段级检测器容易偏向于具有简单上下文的异常片段,被同样有偏差的正常情况所迷惑,并且会遗漏不同模式的异常。为此,我们提出一种新的 MIL 框架:无偏多示例学习(UMIL),用于学习无偏差的异常特征,以改进 WSVAD。在每次 MIL 训练迭代中,我们使用 当前检测器将样本分为具有不同上下文偏差的两组:最具置信度的异常 / 正常片段,以及其余模糊的片段。然后,通过寻找两组样本间的不变特征,我们可以消除可变的上下文偏差。在 UCF - Crime 和 TAD 等基准数据集上进行的大量实验证明了 UMIL 的有效性。我们的代码可通过此链接获取。
1.4 Self-Supervised Video Forensics by Audio-Visual Anomaly Detection
通过视听异常检测实现自监督视频鉴伪
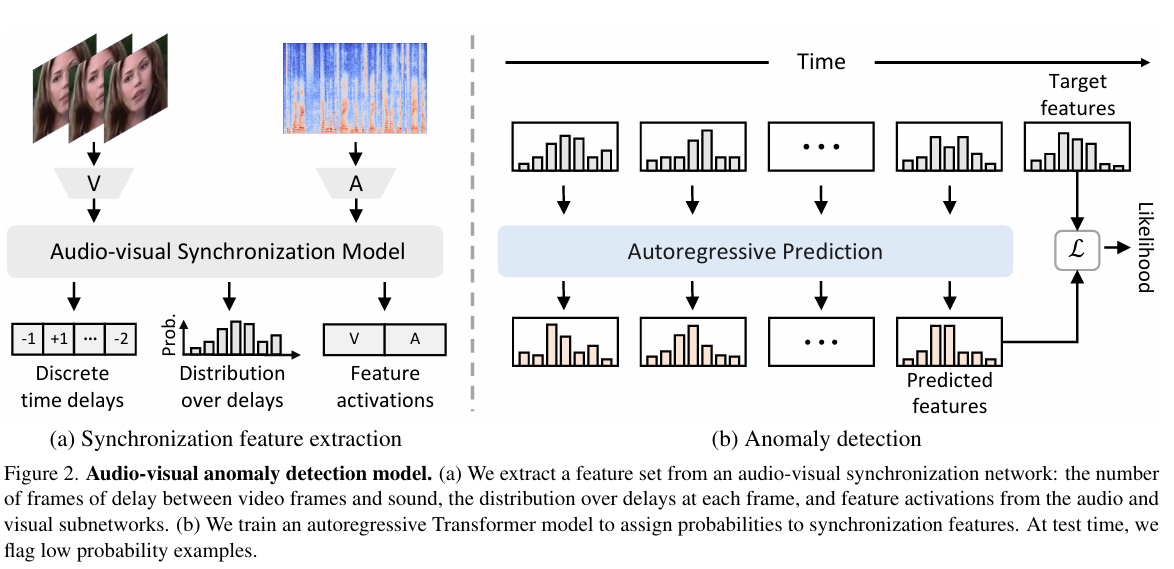
摘要: 经过篡改的视频,其视觉信号与音频信号之间往往存在细微的不一致性。我们提出一种基于异常检测的视频鉴伪方法,该方法能够识别这些不一致性,并且仅需使用真实的、未标注的数据进行训练。我们训练一个自回归模型,利用捕捉视频帧与声音之间时间同步性的特征集,生成视听特征序列。在测试阶段,我们将模型赋予低概率的视频标记出来。尽管该模型完全基于真实视频进行训练,但在检测篡改语音视频的任务中仍取得了出色的性能。项目网站:https://cfeng16.github.io/audio - visual - forensics
1.5 A New Comprehensive Benchmark for Semi-Supervised Video Anomaly Detection and Anticipation
一种用于半监督视频异常检测和预测的全新综合基准

摘要: 半监督视频异常检测(VAD)是智能监控系统中的一项关键任务。然而,VAD 中一种重要的异常类型 ——== 场景依赖型异常==,尚未得到研究人员的关注。此外,目前还没有研究针对异常预测展开,而异常预测对于预防异常事件的发生是一项更为重要的任务。为此,我们提出了一个新的综合数据集 NWPU Campus,该数据集包含 43 个场景、28 类异常事件,视频时长共计 16 小时。目前,它是最大的半监督 VAD 数据集,具有最多的场景数和异常类别数、最长的时长,并且是唯一考虑场景依赖型异常的数据集。同时,它也是首个用于视频异常预测的数据集。我们进一步提出了一种新颖的模型,该模型能够同时检测和预测异常事件。与近年来 7 种出色的 VAD 算法相比,我们的方法在处理场景依赖型异常检测和异常预测方面都表现出色,在上海科技大学、香港中文大学林荫道、印度理工学院孟买分校走廊以及新提出的 NWPU Campus 数据集上均取得了领先的性能。我们的数据集和代码可在https://campusvad.github.io获取。
1.6 Hierarchical Semantic Contrast for Scene-Aware Video Anomaly Detection
用于场景感知视频异常检测的分层语义对比
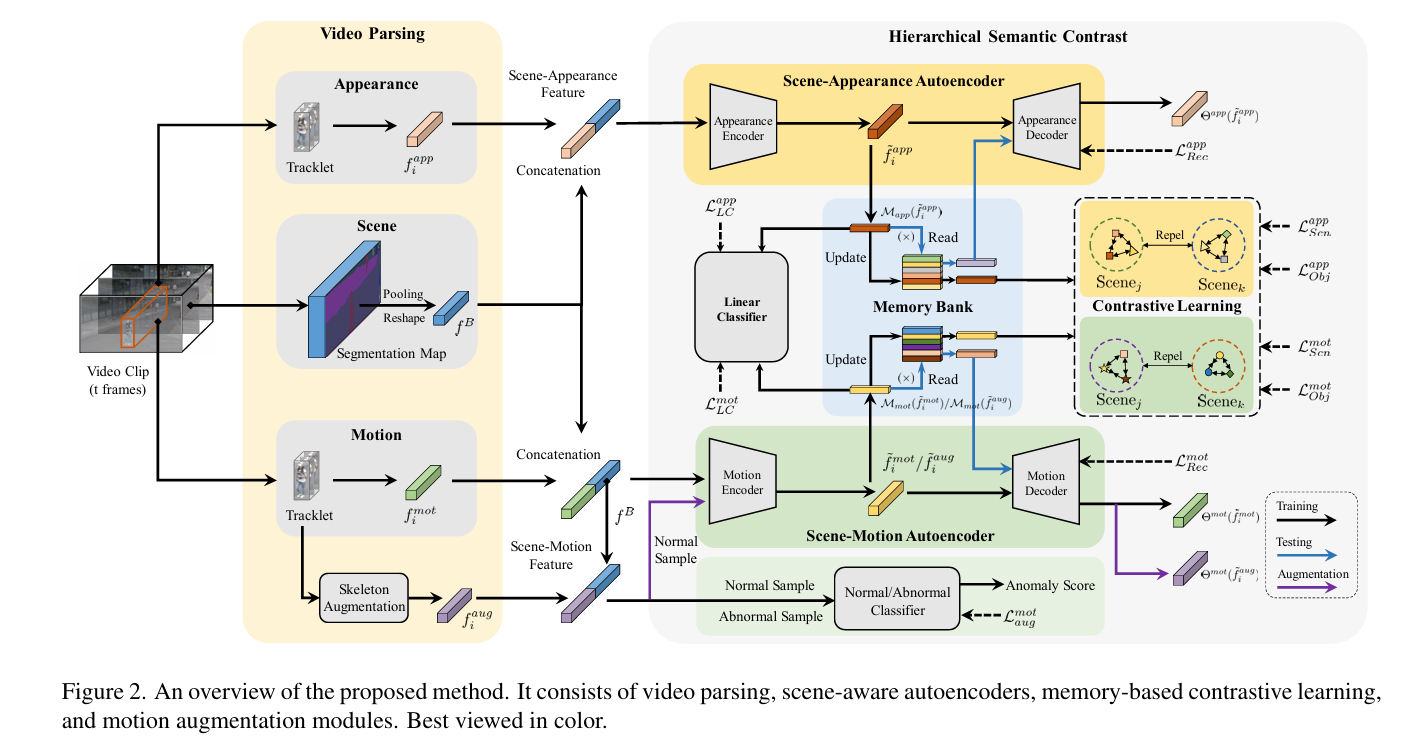
摘要: 提高场景感知能力是视频异常检测(VAD)中的关键挑战。在这项工作中,我们提出了一种分层语义对比(HSC)方法,用于从正常视频中学习场景感知的 VAD 模型。我们首先借助预训练的视频解析模型,将前景物体和背景场景特征与高级语义相结合。然后,在基于自动编码器的重建框架基础上,我们引入场景级和物体级对比学习,促使编码的潜在特征在相同语义类别内紧凑,在不同类别间可分离。这种分层语义对比策略有助于处理正常模式的多样性,同时增强其判别能力。此外,为应对罕见的正常活动,我们设计了基于骨架的运动增强方法,以增加样本数量并进一步优化模型。在三个公开数据集和场景依赖混合数据集上进行的大量实验验证了我们所提方法的有效性。
1.7 Generating Anomalies for Video Anomaly Detection With Prompt-Based Feature Mapping
通过基于提示的特征映射生成用于视频异常检测的异常样本
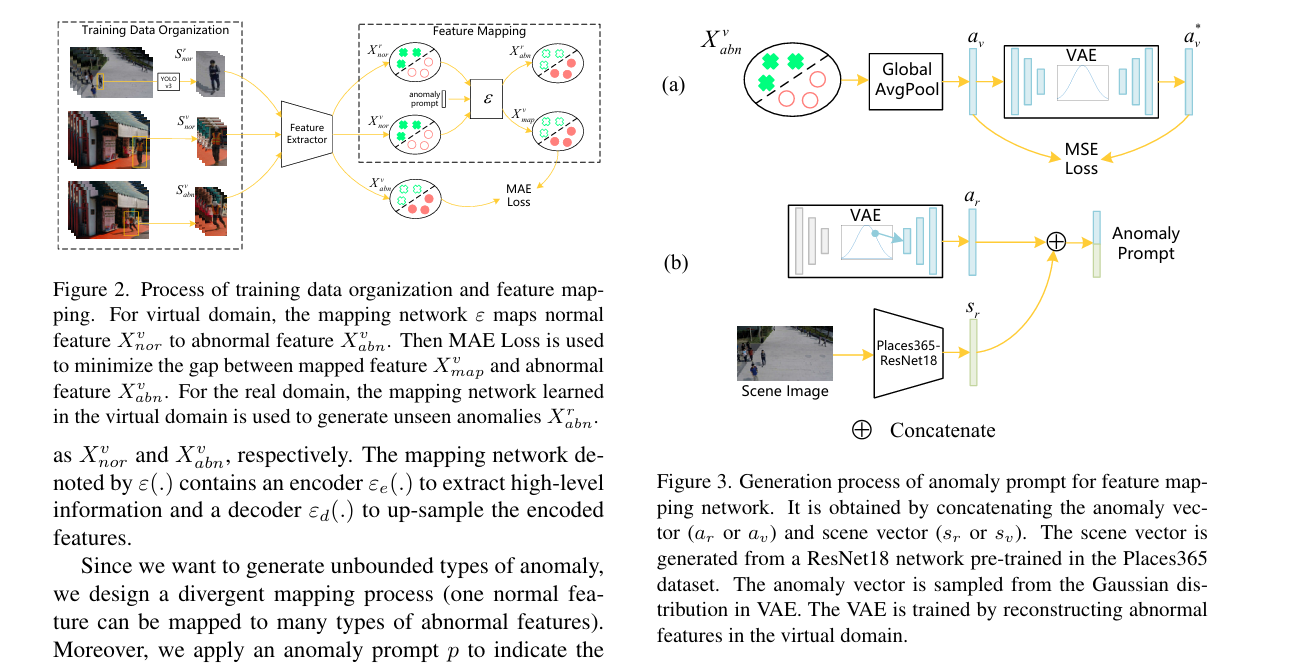
摘要: 监控视频中的异常检测是一项具有挑战性的计算机视觉任务,在训练过程中仅能获取正常视频。近期的研究发布了首个虚拟异常检测数据集,以辅助现实世界中的检测。然而,由于虚拟数据集中的异常类型有限,而现实世界中的异常类型是无界的,因此存在异常差距,这降低了虚拟数据集的泛化能力。此外,虚拟场景与现实场景之间还存在场景差距,包括特定场景的异常(在一个场景中属于异常但在另一个场景中属于正常的事件 )以及特定场景的属性,例如监控摄像头的视角。在本文中,我们旨在通过提出一种基于提示的特征映射框架(PFMF)来解决异常差距和场景差距问题。PFMF 包含一个由异常提示引导的映射网络,用于在现实场景中生成类型无界的未见异常,以及一个映射适配分支,通过应用域分类器和异常分类器来缩小场景差距。所提出的框架在三个基准数据集上的性能优于当前最先进的方法。大量的消融实验也证明了我们框架设计的有效性。
1.8 Video Event Restoration Based on Keyframes for Video Anomaly Detection
基于关键帧的视频事件修复用于视频异常检测
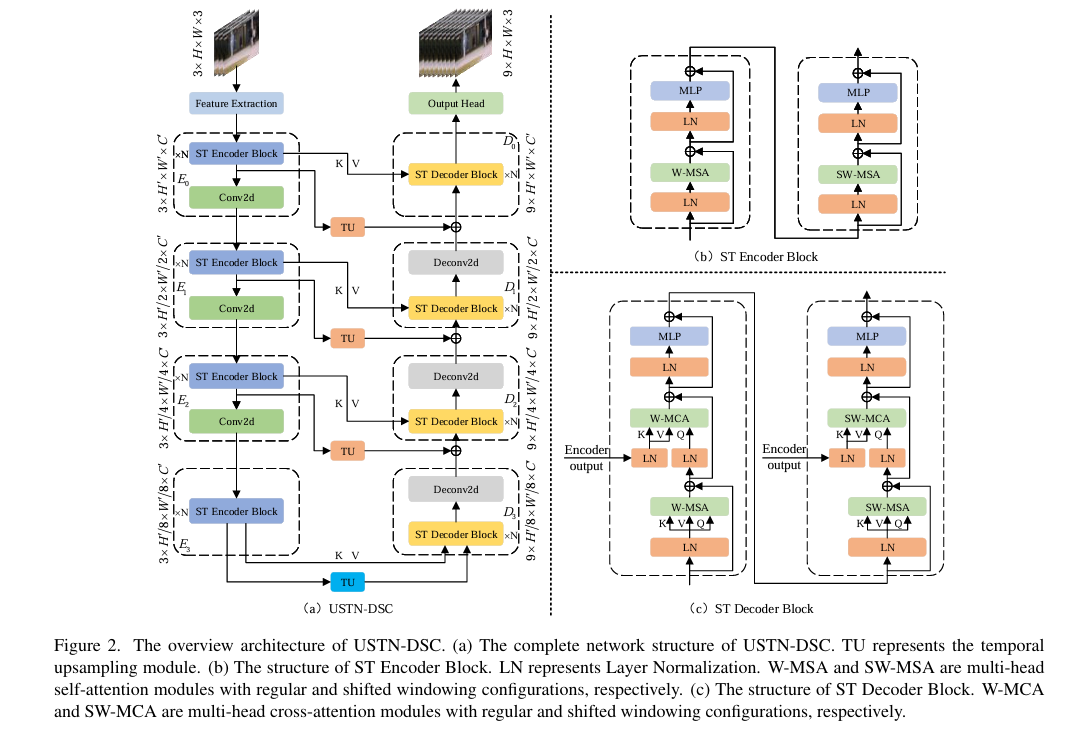
摘要: 视频异常检测(VAD)是一个重要的计算机视觉问题。现有的基于深度神经网络(DNN)的 VAD 方法大多遵循帧重建或帧预测的思路。然而,对视频中更高级视觉特征以及时间上下文关系挖掘和学习的缺失,限制了这两种方法的进一步性能提升。受视频编解码理论启发,我们引入了一种新的双分支框架来突破这些限制:首先,我们提出了一个基于关键帧的视频事件修复新任务。促使 DNN 基于视频关键帧推断缺失的多帧,以修复视频事件,这能更有效地激励 DNN 挖掘和学习视频中潜在的更高级视觉特征以及全面的时间上下文关系。为此,我们提出了一种用于视频事件修复的具有双跳跃连接的 U 形 Swin Transformer 网络(USTN - DSC),其中引入了交叉注意力和时间上采样残差跳跃连接,以进一步辅助修复复杂的静态和动态运动目标特征。此外,我们提出了一种简单而有效的相邻帧差异损失,来约束视频序列的运动一致性。在基准数据集上的大量实验表明,USTN - DSC 优于大多数现有方法,验证了我们方法的有效性。
二、图像异常检测
2.1 Revisiting Reverse Distillation for Anomaly Detection
重新审视用于异常检测的反向蒸馏
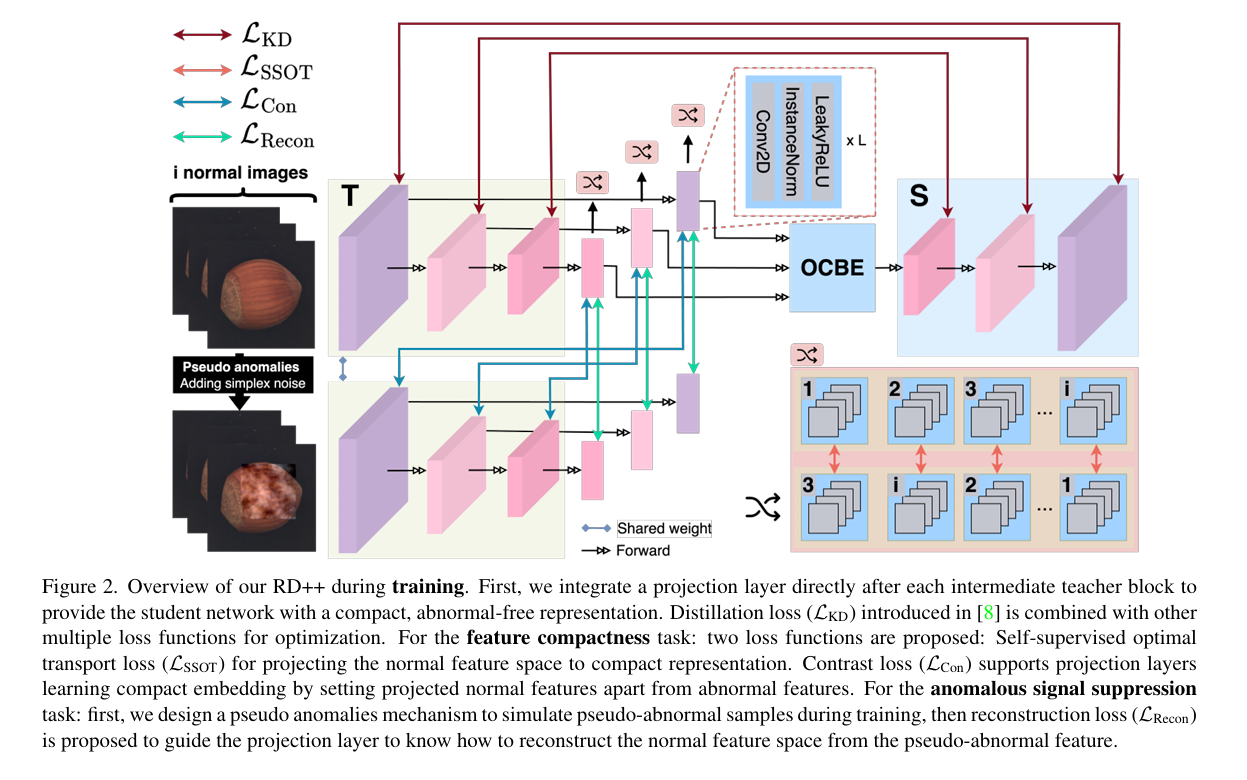
摘要: 异常检测是大规模工业制造中的一项重要应用。针对此任务的近期方法展现出了卓越的准确率,但存在延迟问题。诸如基于记忆库的方法(如 PatchCore )或基于耦合超向量特征自适应(CFA )的方法,需要外部记忆库,这显著延长了执行时间。另一种采用反向蒸馏(RD )的方法在保持低延迟的同时也能有良好表现。在本文中,我们重温这一思路以提升其性能,进而确立了一种新的最先进基准,用于具有挑战性的 MVTec 数据集上的异常检测与定位。所提出的方法称为 RD++,其运行速度比 PatchCore 快六倍,比 CFA 快两倍,而与 RD 相比仅引入了可忽略不计的延迟。我们还在 BTAD 和 Retinal OCT 数据集上进行了实验,以证明我们方法的通用性,并进行消融实验以深入了解其配置。源代码将在https://github.com/tientrandinh/revisiting - ReverseDistillation 上提供。
2.2 DeSTSeg: Segmentation Guided Denoising Student-Teacher for Anomaly Detection
DeSTSeg:用于异常检测的分割引导去噪师生模型
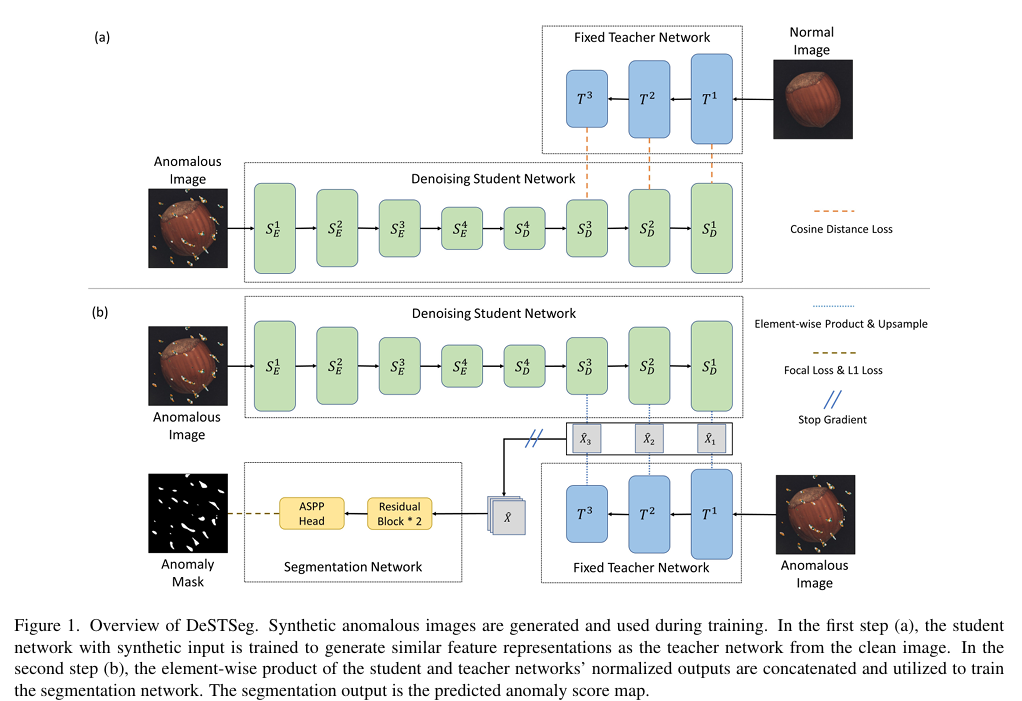
摘要: 视觉异常检测是计算机视觉中的一个重要问题,通常被表述为单类分类和分割任务。师生(S - T)框架已被证明在解决这一挑战方面是有效的。然而,先前基于 S - T 的工作只是凭经验对正常数据施加约束,并融合了多层次信息。在本研究中,我们提出一种改进的模型 DeSTSeg,它将预训练的教师网络、去噪学生编解码器和分割网络整合到一个框架中。首先,为了加强对异常数据的约束,我们引入了一种去噪过程,使学生网络能够从合成的损坏正常图像中学习到更稳健的表示。我们训练学生网络,使其与未损坏的相同图像的教师网络特征相匹配。其次,为了自适应地融合多层次的 S - T 特征,我们利用来自合成异常掩模的丰富监督来训练分割网络,从而显著提高了性能。在工业检测基准数据集上的实验表明,我们的方法在图像级 AUC 上达到了最先进的性能,为 98.6%,在像素级平均精度上为 75.8% ,在实例级平均精度上为 76.4% 。
2.3 SimpleNet: A Simple Network for Image Anomaly Detection and Localization
SimpleNet:一种用于图像异常检测和定位的简单网络
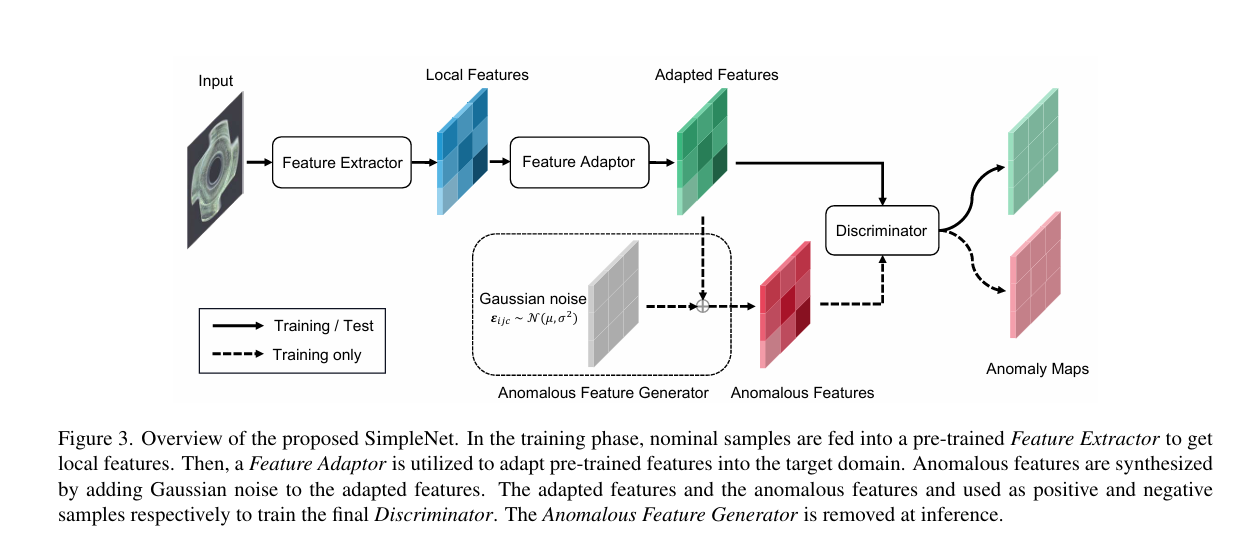
摘要: 我们提出了一种简单且便于应用的网络(名为 SimpleNet),用于异常检测与定位。SimpleNet 由四个组件构成:(1)一个预训练的特征提取器,用于生成局部特征;(2)一个浅层特征适配器,将局部特征转换为目标域特征;(3)一个简单的异常特征生成器,通过向正常特征添加高斯噪声来伪造异常特征;(4)一个二元异常判别器,用于区分异常特征与正常特征。在推理过程中,异常特征生成器将被弃用。我们的方法基于三个理念。首先,将预训练特征转换为面向目标的特征有助于避免域偏差。其次,在特征空间中生成合成异常更为有效,因为缺陷在图像空间中可能没有太多共性。第三,简单的判别器效率高且实用。尽管 SimpleNet 结构简单,但在定量和定性方面均优于先前的方法。在 MVTec AD 基准测试中,SimpleNet 的异常检测 AUC - ROC 得分达到 99.6%,与次优模型相比,误差降低了 55.5%。此外,SimpleNet 的速度比现有方法更快,在 3080ti GPU 上帧率高达 77 FPS。另外,SimpleNet 在单类新异常检测任务中也展现出显著的性能提升。代码地址:https://github.com/DonaldRR/SimpleNet 。
2.4 SQUID: Deep Feature In-Painting for Unsupervised Anomaly Detection
SQUID:用于无监督异常检测的深度特征修复
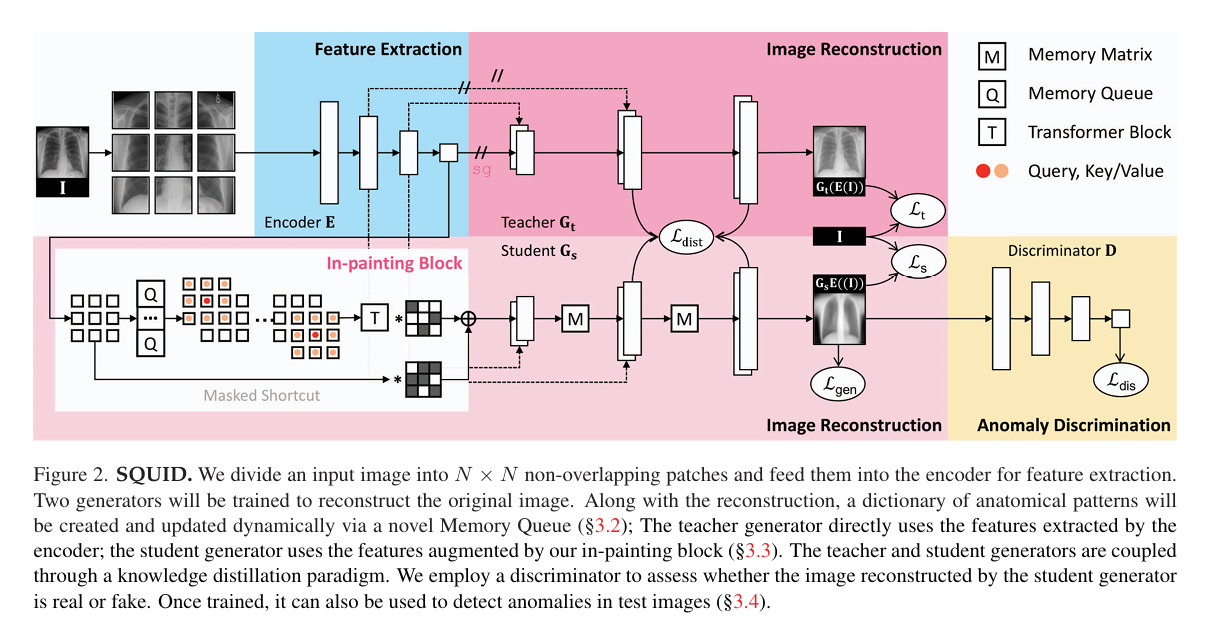
摘要: 放射成像协议聚焦于特定身体部位,因此生成的图像具有高度相似性,且不同患者间会呈现重复的解剖结构。为利用这种结构化信息,我们提出使用空间感知记忆队列来修复和检测放射图像中的异常(简称 SQUID )。我们证明 SQUID 能够将内在的解剖结构分类为重复模式;在推理过程中,它能够识别图像中的异常(未见过 / 修改过的模式 )。在两个胸部 X 光基准数据集上,通过曲线下面积(AUC)衡量,SQUID 在无监督异常检测方面比 13 种当前最优方法至少高出 5 个百分点。此外,我们创建了一个新的数据集(DigitAnatomy),该数据集综合了胸部解剖结构中的空间相关性和一致形状。我们希望 DigitAnatomy 能够推动异常检测方法的开发、评估和可解释性研究。
2.5 Explicit Boundary Guided Semi-Push-Pull Contrastive Learning for Supervised Anomaly Detection
用于有监督异常检测的显式边界引导半推拉对比学习
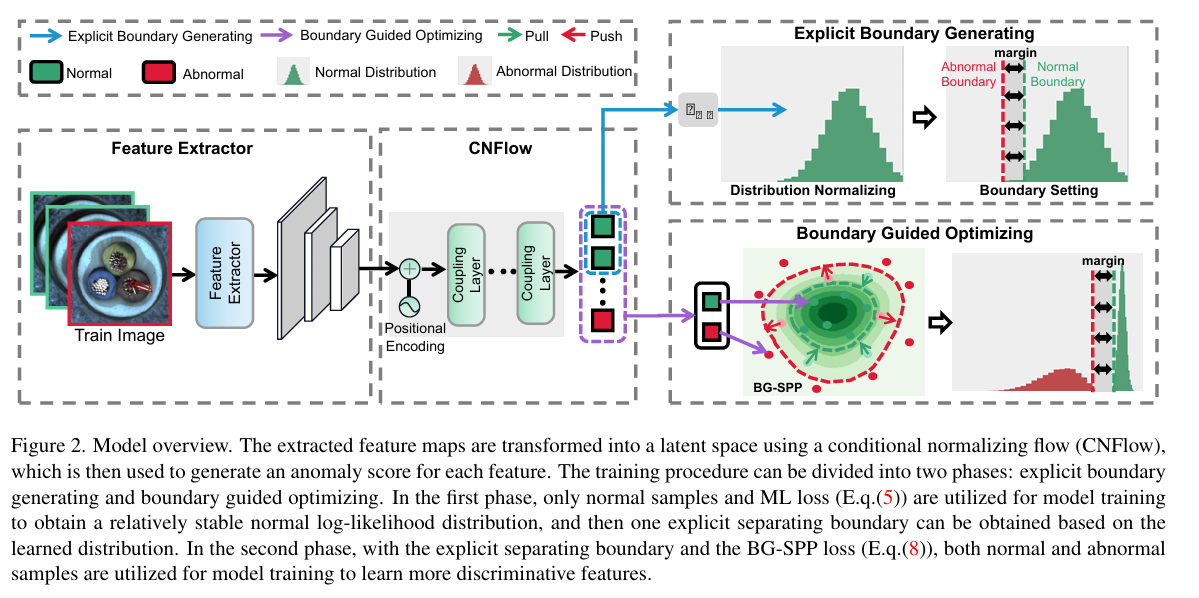
摘要: 大多数异常检测(AD)模型仅使用正常样本以无监督方式进行学习,这可能导致决策边界模糊和判别能力不足。实际上,在现实世界应用中,往往能获取少量异常样本,这些关于已知异常的宝贵知识也应得到有效利用。然而,在训练中使用少量已知异常样本可能会引发另一个问题,即模型可能会受到这些已知异常的影响而产生偏差,无法对未见过的异常进行泛化。在本文中,我们研究有监督异常检测,即使用少量可用的异常样本训练 AD 模型,目标是检测已知和未知的异常。我们提出一种新颖的显式边界引导半推拉对比学习机制,该机制在减轻偏差问题的同时,能够增强模型的判别能力。我们的方法基于两个核心设计:首先,我们找到一个明确且紧凑的分离边界,以此为进一步的特征学习提供指导。由于该边界依赖于正常特征分布,由已知异常样本导致的偏差问题能够得到缓解。其次,我们设计了一种边界引导半推拉损失函数,仅将正常特征聚合在一起,同时将异常特征推离分离边界一定裕度范围之外。通过这种方式,我们的模型能够形成一个更明确且具有判别性的决策边界,从而更有效地将已知和未知异常与正常样本区分开来。代码可在https://github.com/xcyyao00/BGAD获取。
2.6 Prototypical Residual Networks for Anomaly Detection and Localization
用于异常检测和定位的原型残差网络
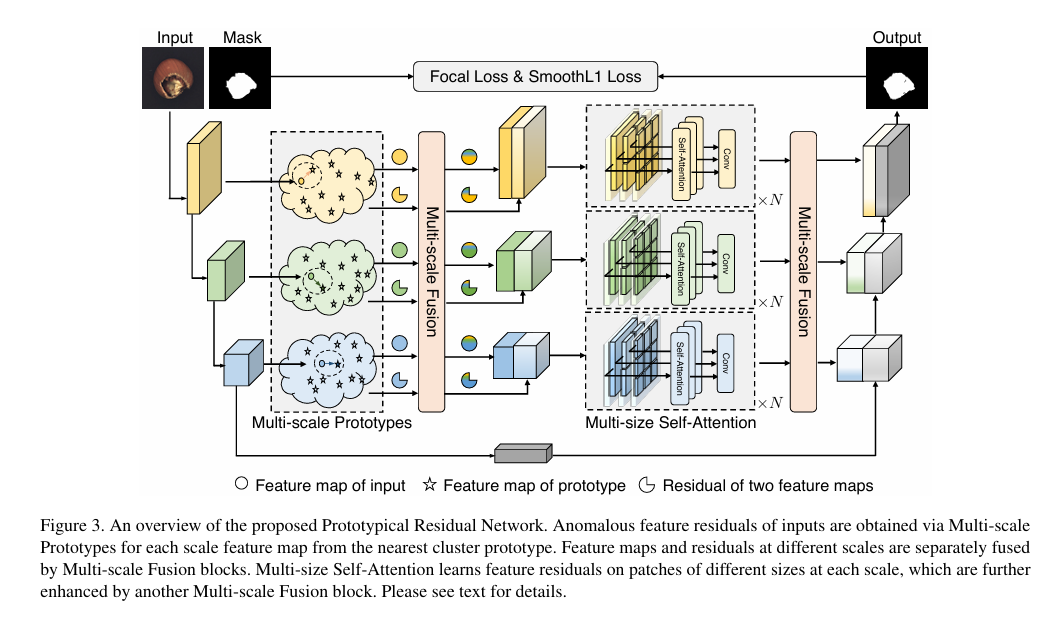 摘要: 异常检测与定位因其高效性和有效性,在工业制造中得到广泛应用。异常情况罕见且难以收集,有监督模型使用少量异常样本训练时,容易对这些已见过的异常产生过拟合,从而导致性能不理想。另一方面,异常情况通常很细微,难以察觉,且表现形式多样,这使得检测异常颇具难度,更不用说定位异常区域了。为解决这些问题,我们提出了一种名为原型残差网络(PRN)的框架,该框架学习异常与正常模式之间不同尺度和大小的特征残差,以准确重建异常区域的分割图。PRN 主要由两部分组成:多尺度原型,明确表示异常相对于正常模式的残差特征;多尺寸自注意力机制,支持可变大小的异常特征学习。此外,我们提出了多种异常生成策略,以考虑已见过和未见过的异常外观变化,从而扩大异常范围。在具有挑战性且广泛使用的 MVTec AD 基准数据集上进行的大量实验表明,PRN 的性能优于当前最先进的无监督和有监督方法。我们还在另外三个数据集上报告了领先的结果,以证明 PRN 的有效性和泛化能力。
摘要: 异常检测与定位因其高效性和有效性,在工业制造中得到广泛应用。异常情况罕见且难以收集,有监督模型使用少量异常样本训练时,容易对这些已见过的异常产生过拟合,从而导致性能不理想。另一方面,异常情况通常很细微,难以察觉,且表现形式多样,这使得检测异常颇具难度,更不用说定位异常区域了。为解决这些问题,我们提出了一种名为原型残差网络(PRN)的框架,该框架学习异常与正常模式之间不同尺度和大小的特征残差,以准确重建异常区域的分割图。PRN 主要由两部分组成:多尺度原型,明确表示异常相对于正常模式的残差特征;多尺寸自注意力机制,支持可变大小的异常特征学习。此外,我们提出了多种异常生成策略,以考虑已见过和未见过的异常外观变化,从而扩大异常范围。在具有挑战性且广泛使用的 MVTec AD 基准数据集上进行的大量实验表明,PRN 的性能优于当前最先进的无监督和有监督方法。我们还在另外三个数据集上报告了领先的结果,以证明 PRN 的有效性和泛化能力。
2.7 Diversity-Measurable Anomaly Detection
可度量多样性的异常检测
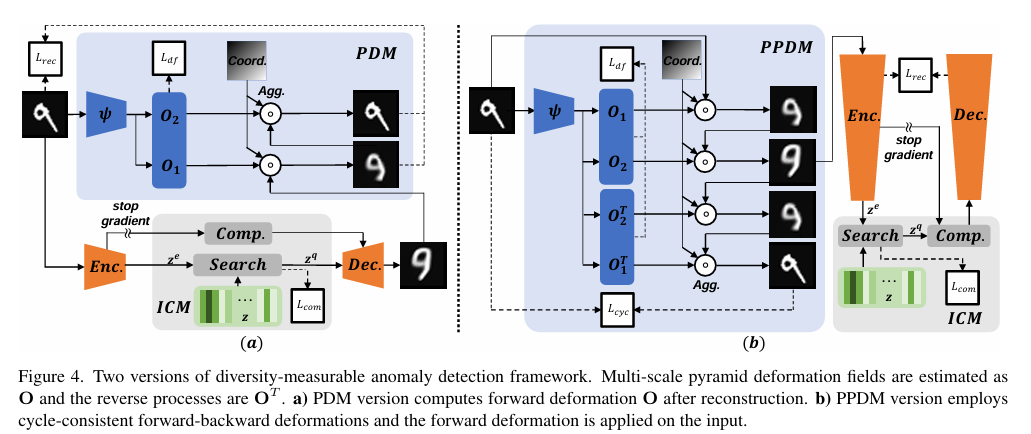
摘要: 基于重建的异常检测模型通过抑制对异常的泛化能力来实现其目的。然而,多样的正常模式因此也无法得到很好的重建。尽管已经有人尝试通过对样本多样性进行建模来缓解这个问题,但由于不期望的异常信息传输,这些方法存在捷径学习的问题。在本文中,为了更好地处理这个副作用问题,我们提出了多样性可度量异常检测(DMAD)框架,以增强重建多样性,同时避免对异常的不必要泛化。为此,我们设计了金字塔变形模块(PDM),该模块对多样的正常模式进行建模,并通过估计从重建参考到原始输入的多尺度变形场来衡量异常的严重程度。PDM 与变形压缩模块相结合,从本质上解开了典型嵌入与变形之间的耦合,使最终的异常分数更加可靠。在监控视频和工业图像上的实验结果证明了我们方法的有效性。此外,DMAD 在面对污染数据和类似异常的正常样本时同样有效。
三、多模态异常检测
3.1 Multimodal Industrial Anomaly Detection via Hybrid Fusion
通过混合融合实现多模态工业异常检测
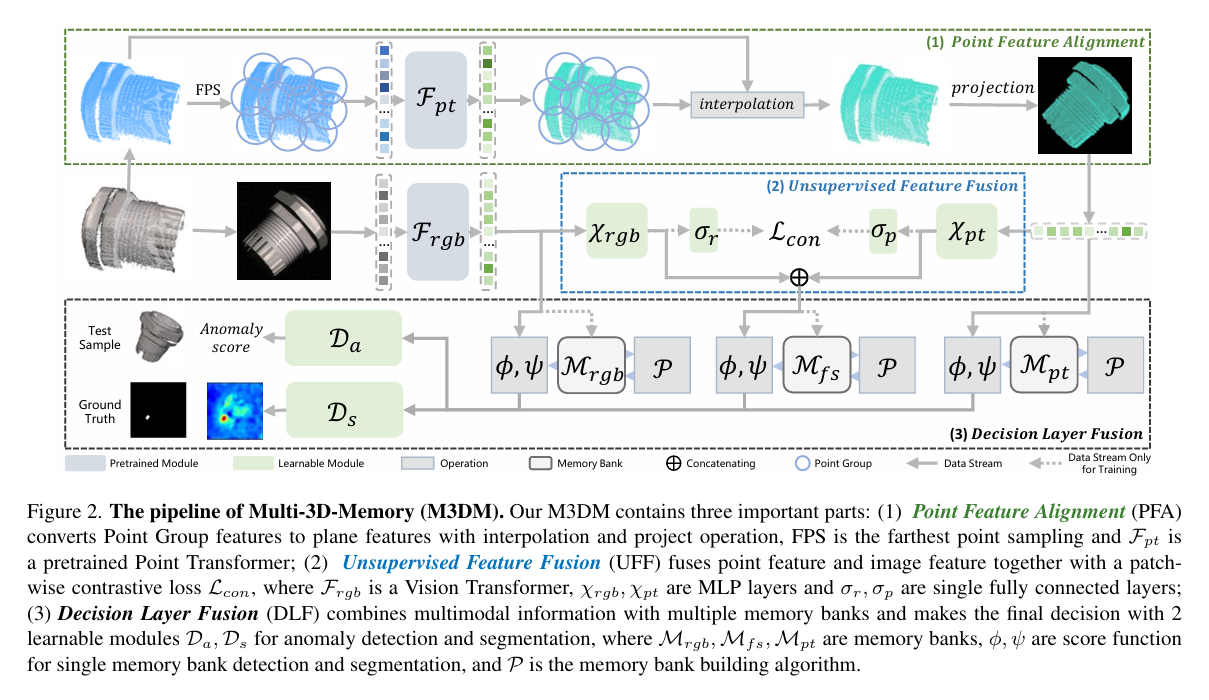
摘要: 基于二维图像的工业异常检测已得到广泛探讨,然而,基于三维点云和 RGB 图像的多模态工业异常检测仍存在诸多尚未涉足的领域。现有的多模态工业异常检测方法直接连接多模态特征,这会导致特征间产生强烈干扰,进而损害检测性能。在本文中,我们提出了 Multi-3D-Memory(M3DM),这是一种全新的多模态异常检测方法,采用混合融合策略:首先,我们设计了一种无监督特征融合方法,并结合逐块对比学习,以促进不同模态特征间的交互;其次,我们使用决策层融合,并搭配多个记忆库,以避免信息丢失,并借助额外的新类别分类器做出最终决策。我们还进一步提出了点特征对齐操作,以更好地对齐点云和 RGB 特征。大量实验表明,我们的多模态工业异常检测模型在 MVTec - 3D AD 数据集上的检测和分割精度方面均优于当前最先进(SOTA)的方法。代码位于https://github.com/nomewang/M3DM 。

















 1561
1561

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









