







题目:The MVTec 3D-AD Dataset for Unsupervised 3D Anomaly Detection and Localization
题目:用于无监督三维异常检测与定位的MVTec 3D-AD数据集
VISAPP是国际计算机视觉理论与应用会议(International Conference on Computer Vision Theory and Applications)的简称
Keywords: Anomaly Detection, Dataset, Unsupervised Learning, Visual Inspection, 3D Computer Vision
关键词:异常检测;数据集;无监督学习;视觉检测;三维计算机视觉
Abstract 摘要
我们引入了首个用于无监督异常检测和定位任务的综合性三维数据集。它的灵感来自现实世界的视觉检测场景,在这种场景中,即使模型仅在无异常数据上进行训练,也必须检测制造产品上的各种缺陷。有些缺陷表现为物体几何结构的异常,这会在数据的三维表示中导致显著偏差。我们使用高分辨率工业三维传感器获取了10种不同物体类别的深度扫描数据。我们提供了一个训练集和一个验证集,二者均仅由无异常样本的扫描数据组成。相应的测试集包含显示各种缺陷(如划痕、凹痕、孔洞、污染物或变形 )的样本。为每个异常测试样本都提供了精确的真实标注。在我们的数据集上对三维异常检测方法进行的初步基准测试表明,仍有很大的改进空间。
1 INTRODUCTION 介绍
现代3D传感器可用性和精度的提高,推动了3D计算机视觉领域的显著进步。科研界利用这些设备为众多现实世界问题创建数据集,如点云配准(Zeng等人,2017)、分类(Wu等人,2015)、3D语义分割(Chang等人,2015;Dai等人,2017)、3D目标检测(Armeni等人,2016)以及刚体姿态估计(Drost等人,2017;Hodaň等人,2020 )。新的改进算法的开发依赖于这类高质量数据集的支持。
在许多应用中,一项尤为重要的任务是识别与模型在训练期间所观察到的数据不同的异常数据。例如,在制造业中,这些方法可用于推理阶段检测缺陷,而训练时仅使用无异常样本。在自动驾驶中,智能系统能否检测到训练中未见过的结构,关乎安全关键问题。这个问题在彩色或灰度图像领域已备受关注。奇怪的是,无监督异常检测领域在3D范畴的探索相对较少。我们认为,关键原因在于缺乏合适的数据集。
为填补这一空白并激发对新方法开发的更多兴趣,我们引入了一个用于无监督3D异常检测和定位任务的真实世界数据集。给定一组某物体完全无异常的3D扫描数据,任务是检测和定位各种类型的异常。我们的数据集灵感源于工业检测场景。该应用被视为无监督异常检测任务的重要用例,因为实际中可能出现的所有缺陷的性质往往是未知的。此外,用于训练的缺陷样本可能难以获取,且对缺陷进行精确标注是一项艰巨任务。图1展示了我们新数据集的两个典型样本。我们的主要贡献如下:
- 我们引入了首个用于无监督三维数据异常检测和定位的综合性数据集。它由来自10个现实世界物体类别的4147个高分辨率3D点云扫描组成。训练集和验证集仅包含无异常数据,而测试集中的样本包含各种类型的异常。我们为每个异常提供了精确的真实标注。
- 我们评估了当前专门为无监督3D异常定位设计的方法。初步基准测试表明,现有方法在我们的数据集上表现不佳,未来仍有很大的改进空间。

2 RELATED WORK 相关工作
2.1 Anomaly Detection in 2D 二维异常检测
对于二维图像数据,存在大量合成和真实世界的基准数据集。它们涵盖了多个领域,如自动驾驶(Blum等人,2019)、视频异常检测(Li等人,2013;Lu等人,2013;Sultani等人,2018)或工业检测场景。
2.1.1 二维异常领域的现有数据集
由于我们提出了一个新的工业检测数据集,我们在此重点总结该领域现有的数据集。任务是在仅有一组无异常训练图像的情况下,检测和定位制造产品上的缺陷
①Huang等人(2018)展示了一个包含1344张瓷砖图像的表面检测数据集。测试图像包含各种类型的异常,如裂缝或不平整区域。
②类似的数据集还有专注于检测单一重复二维纹理的(Carrera等人,2017;Song和Yan,2013;Wieler和Hahn,2007 )。
③Bergmann等人(2019a,2021)引入了一个更全面的数据集,总共包含5354张图像,展示了五种纹理和十三个物体类别。测试集包含73种不同类型的异常,如制造产品上的污染物或划痕。
2.1.2 二维异常领域的现有方法
上述数据集推动了许多用于二维彩色图像的方法的发展。
2.1.2.1 预训练提取特征描述符
一种常见的方法(Bergmann等人,2020;Cohen和Hoshen,2021;Salehi等人,2021;Wang等人,2021 )是对从大规模数据集(如ImageNet (Krizhevsky等人,2012 ))预训练的神经网络中提取的描述符的分布进行建模。这些网络期望输入RGB图像。因此,所得方法不太适合处理3D数据的二维表示(如深度图像 ),也难以直接迁移到3D异常检测中。
2.1.2.2 使用生成模型或者自动编码器进行重建
另一类工作使用生成模型,如卷积自动编码器(AE)(Masci等人,2011 )或生成对抗网络(GAN)(Goodfellow等人,2014 ),通过评估像素级重建误差来检测异常。
Schlegl等人(2019 )引入了f - AnoGAN,即在无异常训练数据上训练GAN。第二步,训练一个编码器网络,输出潜在样本,这些样本输入GAN的生成器时可重建相应的输入图像。
类似地,基于自动编码器的方法(Bergmann等人,2019b;Park等人,2020 )首先对输入图像进行编码,得到低维潜在样本,然后对该样本进行解码,以最小化像素级重建误差。
对于这两种方法,异常分数都是通过将输入图像与其重建图像进行像素级比较来计算的。由于这些方法不需要特定领域的预训练,因此可以适应其他二维表示形式,如深度图像。
2.2 Anomaly Detection in 3D 三维异常检测
2.2.1 两个医学基准三维异常检测MR数据集
到目前为止,还没有专门为无监督异常检测和定位设计的综合性3D数据集。针对这个问题的现有方法是在两个医学基准数据集上进行评估的,而这两个数据集最初是为在脑磁共振(MR)扫描中进行疾病的监督检测而引入的。
Menze等人(2015)、Bakas等人(2017)和Baid等人(2021)提出了多模态脑肿瘤图像分割基准(BRATS)。它由65个来自神经胶质瘤患者的多对比度MR扫描组成。每个样本以密集体素网格的形式提供,放射科医生在扫描的每个图像切片中对肿瘤进行了标注。
同样,Liew等人(2018)提供了中风后病变解剖追踪(ATLAS)数据集。它由304个MR扫描以及相应的脑病变真实标注组成。
这两个数据集都通过堆叠多个灰度图像来提供3D信息,以形成密集体素网格。因此,这些数据的性质与我们数据集中描述物体几何表面的数据有着根本的不同。
2.2.2 体素数据
由于缺乏更多样化的用于无监督异常检测的3D数据集,专门为该任务设计的方法非常少。直到最近,Simarro Viana等人(2021)将f - AnoGAN 扩展到了体素数据 。与二维情况类似,训练一个生成对抗网络(GAN)来生成模拟训练分布的体素网格,使用3D卷积。随后,训练一个编码器网络,将输入样本映射到生成器对应的潜在样本。在推理阶段,通过将输入体素与重建体素进行比较,为每个体素单元得出异常分数。
Bengs等人(2021)提出了一种同样基于体素网格的自动编码器方法。训练一个变分自动编码器,通过低维潜在变量来重建体素网格。异常分数通过将输入与重建结果按体素逐个比较得出。
3 DESCRIPTION OF THE DATASET 数据集的描述
MVTec 3D - AD数据集由高分辨率工业3D传感器采集的4147次扫描数据组成。对于10个物体类别中的每一类,都提供了一组无异常扫描数据用于模型训练和验证。测试集既包含无异常扫描数据,也包含存在各种异常类型(如划痕、凹痕或污染)的物体样本。这些缺陷是按照实际检测场景中可能出现的情况设计和制造的。
①数据集中的5个物体类别在样本间存在明显的自然差异,分别是百吉饼、胡萝卜、饼干、桃子和土豆。
②另外三个物体,泡沫、绳子和轮胎,外观标准化,但容易变形。
③剩下的两个物体,电缆接头和定位销,是刚性的。
原则上,检查后两者可以通过将物体的几何形状与CAD模型进行比较来实现。然而,无监督方法应该能够检测所有类型物体的异常,并且在实际应用中创建CAD模型并不总是理想或可行的。图2展示了数据集中每个类别对应的一个点云示例。该图还展示了一些异常情况以及相应的真实标注。
①百吉饼和饼干的图像显示物体上有裂缝。
②电缆接头和定位销的表面呈现出几何变形。
③胡萝卜上有一个洞,桃子和绳子表面有一些污染物,泡沫、土豆和轮胎的部分被截断。
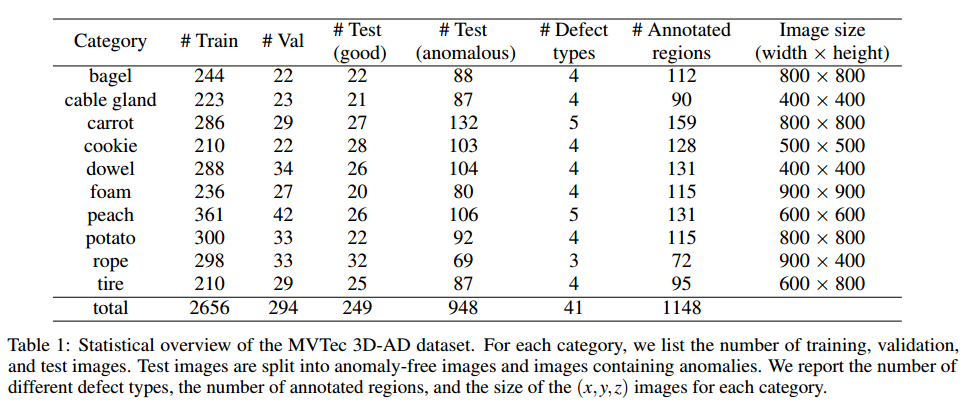
这些是我们数据集中41种异常类型的典型例子。数据集的更多统计信息列于表1中。

3.1 Data Acquisition and Preprocessing 数据采集和预处理
3.1.1 数据集采集
3.1.1.1 Zivid One⁺ Medium²工业传感器
所有数据集扫描均由Zivid One⁺ Medium²工业传感器采集,这是一种利用结构光记录高分辨率3D扫描数据的传感器。
3.1.1.2 分辨率1920×1200像素的三通道xyz图像
该传感器提供的数据为分辨率1920×1200像素的三通道图像,通道分别代表相对于本地相机坐标系的x、y和z坐标。图像的(x, y, z)值与相应的点云一一对应。此外,该传感器为每个(x, y, z)像素采集互补的RGB值。
3.1.1.3 传感器被固定安装:从同一角度观察每个物体类别的所有物体
传感器被固定安装,以便从同一角度观察每个物体类别的所有物体。我们对内部相机参数进行了校准,使3D点能够投影到相应的像素坐标(Steger等人,2018 )。场景由间接漫射光源照明。
3.1.2 数据集预处理
3.1.2.1 指定一个固定的矩形区域,对RGB和原始的(x, y, z)进行裁剪,减少背景像素
对于数据集中的每个类别,我们指定了一个固定的矩形区域,并对原始的(x, y, z)和RGB图像进行裁剪,以减少样本中的背景像素数量。
3.1.2.2 启用并简化了数据增强
采集设置和预处理与实际应用非常相似,在实际应用中,物体通常位于确定的位置,并且选择最适合任务的照明。此外,我们的设置启用并简化了数据增强。所有物体均在深色背景下记录,预处理在物体周围留出足够的边缘,以便应用各种数据增强技术,如裁剪、平移或旋转。这使得我们能够使用对数据需求大的深度学习方法,正如我们在第4节实验中所展示的那样。
3.1.3 示例
图3展示了图2中桃子异常测试样本所提供的数据。该图像大小为600×600像素,从原始传感器扫描图像裁剪而来。前三张图像分别可视化了数据集中样本的x、y和z坐标。白色像素标记了由于遮挡、反射或传感器不准确等原因,传感器未返回任何3D信息的区域。相应的RGB图像和真实标注图像也一并展示。

3.2 Ground-Truth Annotations 真实标注
我们为测试集中的每个异常样本提供了精确的真实标注。异常标注是在三维点云中进行的。由于三维点与其在(x, y, z)图像中各自的像素位置存在一一对应关系,我们将标注以二维区域的形式呈现。
3.2.1 异常标注情况
这种方式使我们能够额外标记无效的传感器像素,从而标注那些因点的缺失而显现的异常。
3.2.1.1 裂缝、孔洞等:缺陷处的点云数据缺失
例如,某种异常可能导致三维重建失败,进而在三维图像中产生无效像素。
当出现异常情况时,可能会导致三维重建失败。例如物体表面有特殊的缺陷(如裂缝、孔洞等),这些缺陷处的点云数据缺失,在进行三维重建时,对应的位置就会产生无效像素。通过标记无效像素的方式,实际上也能标注出这些因为点的缺失而显现的异常。也就是说,这些无效像素的出现,暗示了物体存在异常情况。
3.2.1.2 物体表面的污渍等:在 RGB图像中能看到某些异常
此外,如果某个异常在RGB图像中可见,且其对应的彩色像素尚未包含在真实标注中,我们会将这些像素添加到标注中。
RGB 图像记录了物体的颜色等信息。如果在 RGB图像中能看到某些异常(比如物体表面的污渍等),但在之前的真实标注中没有包含这些异常对应的彩色像素,就会将这些像素添加到标注中。这是为了更全面地标记物体的异常情况,结合RGB 图像和三维点云数据,使得标注更加准确和完整。
3.2.2 示例
图3展示了一个真实标注掩模的示例,其中桃子上存在污染物。
在图2中,当投影到场景的有效三维点时,更多的标注得以可视化。
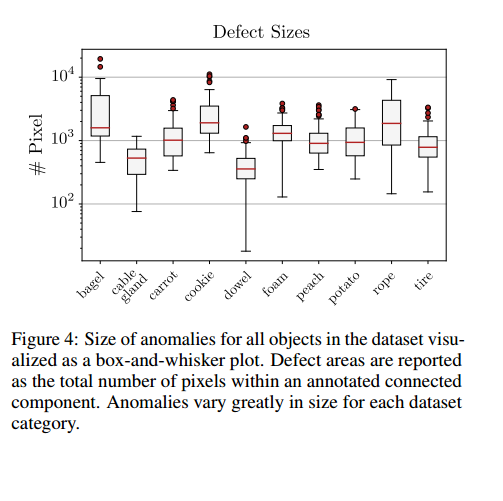
测试集中存在的异常的各个连通分量的大小差异很大,从几百像素到几千像素不等。图4以对数刻度的箱线图(带离群值)展示了它们的分布情况(Tukey,1977 )。
3.3 Performance Evaluation 表现评估
为了评估一种方法在我们数据集上的异常定位性能,我们要求该方法为测试集中的每个(x, y, z)像素输出一个实值异常分数。
为什么为全部像素点输出实值异常分数还不是为某些有效像素点
与仅为测试样本的所有有效3D点分配异常分数不同,这种方式能够检测到通过无效传感器像素或缺失3D结构表现出来的异常。
3.3.1 计算每区域重叠PRO度量
这些异常分数通过一个阈值转换为二值预测。然后我们计算区域重叠率(PRO)指标(Bergmann等人,2021 ),其定义为二值预测P与 真实标注中每个连通分量
C
k
C_{k}
Ck 的平均相对重叠率。
PRO值的计算公式如下:
P
R
O
=
1
K
∑
k
=
1
K
∣
P
∩
C
k
∣
∣
C
k
∣
(
1
)
PRO = \frac{1}{K}\sum_{k = 1}^{K}\frac{|P \cap C_{k}|}{|C_{k}|} \quad (1)
PRO=K1k=1∑K∣Ck∣∣P∩Ck∣(1)
以下是对这个公式各部分含义及计算方式的详细解释:
符号含义
- P R O PRO PRO:区域重叠率(Per - Region Overlap )指标,用来衡量模型预测结果与真实标注之间的重叠程度,值越高说明预测结果越接近真实情况。
- K K K:真实标注中连通分量的总数。连通分量可以理解为真实标注里,那些相互连接在一起的异常区域块。比如在一张图像里,真实的异常部分可能分散成几个独立的小块,每一个小块就是一个连通分量, K K K就是这些小块的数量总和。
- P P P:模型输出的二值预测结果。在异常检测里,二值意味着只有两种状态,比如预测为异常(用1表示 )或者正常(用0表示 ),它是一个表示预测结果的集合 。
- C k C_{k} Ck:真实标注中的第 k k k个连通分量 ,也就是真实异常区域里的某一个相互连接的部分。
- ∣ P ∩ C k ∣ \vert P \cap C_{k}\vert ∣P∩Ck∣:表示二值预测结果 P P P与第 k k k个真实标注连通分量 C k C_{k} Ck的交集的元素个数。交集就是 P P P和 C k C_{k} Ck中都有的部分,这部分元素个数体现了预测结果和真实异常区域在第 k k k个连通分量上重合的程度 。
- ∣ C k ∣ \vert C_{k}\vert ∣Ck∣:第 k k k个真实标注连通分量 C k C_{k} Ck本身的元素个数 ,也就是这个真实异常区域块包含的像素数量等(取决于数据表示 )。
计算步骤示例
假设现在有一张图像用于异常检测:
- 首先确定真实标注中的连通分量数量 K K K。比如经过分析,发现真实异常区域有3个相互独立的小块,那么 K = 3 K = 3 K=3 。
- 对于第一个连通分量 C 1 C_{1} C1 ,计算它和二值预测结果(P)的交集元素个数 ∣ P ∩ C 1 ∣ \vert P \cap C_{1}\vert ∣P∩C1∣,以及 C 1 C_{1} C1自身的元素个数 ∣ C 1 ∣ \vert C_{1}\vert ∣C1∣ ,然后得到它们的比值 ∣ P ∩ C 1 ∣ ∣ C 1 ∣ \frac{\vert P \cap C_{1}\vert}{\vert C_{1}\vert} ∣C1∣∣P∩C1∣。
- 按照同样的方法,依次计算 C 2 C_{2} C2、 C 3 C_{3} C3与 P P P相关的比值 ∣ P ∩ C 2 ∣ ∣ C 2 ∣ \frac{\vert P \cap C_{2}\vert}{\vert C_{2}\vert} ∣C2∣∣P∩C2∣、 ∣ P ∩ C 3 ∣ ∣ C 3 ∣ \frac{\vert P \cap C_{3}\vert}{\vert C_{3}\vert} ∣C3∣∣P∩C3∣ 。
- 最后把这三个比值相加再除以 K K K(这里 K = 3 K = 3 K=3 ),即 P R O = 1 3 ( ∣ P ∩ C 1 ∣ ∣ C 1 ∣ + ∣ P ∩ C 2 ∣ ∣ C 2 ∣ + ∣ P ∩ C 3 ∣ ∣ C 3 ∣ ) PRO=\frac{1}{3}(\frac{\vert P \cap C_{1}\vert}{\vert C_{1}\vert}+\frac{\vert P \cap C_{2}\vert}{\vert C_{2}\vert}+\frac{\vert P \cap C_{3}\vert}{\vert C_{3}\vert}) PRO=31(∣C1∣∣P∩C1∣+∣C2∣∣P∩C2∣+∣C3∣∣P∩C3∣) ,得到这张图像的区域重叠率 P R O PRO PRO值 。这个值越大,说明模型预测的异常区域和真实异常区域在整体上重叠得越好,模型在异常定位方面的表现也就相对更优。
3.3.2 无监督异常定位任务的标准指标:最终性能度量
其中 K K K是真实标注分量的总数。对多个阈值重复此过程,并通过绘制所得PRO值与相应误报率的关系来构建一条曲线。最终性能度量是通过在有限误报率范围内对该曲线进行积分,并将所得面积归一化到区间[0, 1]来计算的。这是无监督异常定位任务的标准指标,在异常大小差异显著时特别有用。
3.3.3 误报率的建议范围
我们想要强调的是,在使用我们的数据集时,我们强烈不建议计算PRO曲线在高误报率下的面积。我们建议选择误报率限制不超过0.3的积分区间。
这是因为与图像大小相比,异常区域非常小。在高误报率下,错误分割的像素数量将显著大于实际异常像素的数量。这将导致分割结果在实际中不再有意义。
3.3.4 AUC - ROC
我们的数据集还可用于评估对每个样本是否包含异常做出二分类决策的算法性能。在这种情况下,我们将接收者操作特征曲线下面积(AUC - ROC)作为标准分类指标进行报告。
4 INITIAL BENCHMARK 初始基准
为了检验现有的3D异常定位方法在我们的新数据集上的表现,我们进行了初步基准测试。该测试旨在为未来的方法提供一个基线。
目前专门针对此任务提出的方法很少,且所有方法都在体素数据上运行。这主要是因为这些方法最初是为处理由多层强度图像组成的磁共振(MR)或计算机断层扫描(CT)扫描数据而设计的。作为这类方法的代表,我们在基准测试中纳入了体素f - AnoGAN(Simarro Viana等人,2021 )以及我们自己实现的卷积体素自动编码器(Voxel AE,Bengs等人,2021 )。
这些方法的前身是为2D图像数据开发的。2D方法和3D方法的主要区别在于,前者在图像上使用2D卷积,而后者在体素数据上使用3D卷积。因此,这些方法可以很容易地适应处理深度图像,我们也将它们纳入了基准测试。除了这些深度学习方法,我们还评估了变异模型(Steger等人,2018 )在体素数据和深度图像上的性能。它们通过计算像素或体素相对于训练数据分布的马氏距离来检测异常。
所有评估的方法要么可以仅在3D数据上运行,要么可以额外处理附加到每个3D点的颜色信息。因此,我们还比较了在模型中添加颜色信息时性能的差异。训练参数和模型架构的详细信息可在附录中找到。
4.1 Training and Evaluation Setup 训练和评估的设置
4.1.1 Data Representation 数据表示
4.1.1.1 体素网格表示
为了将数据集样本表示为体素网格,我们首先针对数据集中的每个类别,在整个训练集上计算一个全局三维包围盒。然后,将一个 n × n × n n×n×n n×n×n的体素网格放置在包围盒的中心位置。网格的边长选取为与包围盒的最长边相等。如果仅处理三维数据,被占据的体素和空体素分别被赋值为1和 - 1 。如果添加了RGB信息,空体素被赋值为向量 ( − 1 , − 1 , − 1 ) (-1, -1, -1) (−1,−1,−1),被占据的体素则被赋予落入同一网格单元内所有点的平均RGB值。
4.1.1.2 深度图像表示
对于处理深度图像的方法,我们计算原始 ( x , y , z ) (x, y, z) (x,y,z)图像中每个有效像素到相机中心的欧几里得距离。无效像素被赋予距离值0。如果包含颜色信息,RGB通道会被添加到单通道深度图像中。对于体素网格和深度图像,RGB值都被缩放到区间 [ 0 , 1 ] [0, 1] [0,1] 。
这里主要在讲数据集样本的两种数据表示方式,即转换为体素网格和深度图像,具体解释如下:
体素网格表示
- 包围盒确定:先给每个数据集类别里的所有训练样本找一个能把它们都框住的三维大盒子(全局三维包围盒 ),这是为了确定数据范围。
- 体素网格放置:在包围盒中心放一个(n×n×n)的体素网格,网格边长和包围盒最长边一样长 。比如包围盒最长边是10个单位长度,那网格边长就是10 。
- 体素赋值:
- 仅三维数据:如果体素里有点(被占据 ),就赋值为1 ;没有点(空体素 ),就赋值为 - 1 。
- 有RGB信息:空体素赋值为((-1, -1, -1)) ;被占据的体素,把落在它里面所有点的RGB值平均一下,作为这个体素的RGB值 。
深度图像表示
- 距离计算:对原始((x, y, z))图像里有效的像素点,算它到相机中心的直线距离(欧几里得距离 )。无效像素点距离设为0 。
- 颜色信息添加:要是有颜色信息,就把RGB通道加到只有距离信息的单通道深度图像上 。
- 数值缩放:不管是体素网格里的RGB值,还是深度图像里的RGB值,都调整到0 - 1这个范围 。 这样处理后的数据形式,方便后续不同方法去处理和分析。
4.1.2 Methods on Voxel Grids 体素网格的方法
4.1.2.1 基于压缩方法的潜在维度
对于所有基于体素的方法,我们采用Simarro Viana等人(2021)建议的 (64×64×64)体素大小的网格。为了选择基于压缩方法的潜在维度,我们进行了消融研究,相关内容见附录。异常分数是通过将输入与重建结果按体素逐个比较来计算的。
在基于压缩的方法(比如文中的体素自动编码器等 )中,“潜在维度” 指的是模型将输入数据进行压缩后得到的特征向量的维度 。
4.1.2.2 体素网格稀疏的解决办法:损失权重 w w w
我们数据集中样本的体素网格分布稀疏,大部分体素为空。我们发现,在训练体素自动编码器(Voxel AE)时,如果在重建损失中对每个体素赋予相同权重,会出现问题。在这种情况下,模型倾向于简单输出一个空的体素网格,以最小化重建误差。为解决这种不平衡问题,我们引入一个损失权重 w ∈ ( 0 , 1 ) w\in(0,1) w∈(0,1),其计算方式为训练集中空体素的比例。在训练过程中,如果体素被占据,则该体素的损失乘以((1 - w)),否则乘以(w) 。
4.1.2.3 体素变异模型
对于体素变异模型(Voxel Variation Model),我们首先计算训练数据在每个体素处的均值和标准差。在推理阶段,通过计算每个测试样本与训练分布在体素层面的马氏距离来得出异常分数。
4.1.3 Methods on Depth Images 深度图像处理的方法
4.1.3.1 Depth f - AnoGAN && Depth AE
我们对深度f - AnoGAN(Depth f - AnoGAN) 和 深度自动编码器(Depth AE) 的实现均处理分辨率为(256×256)像素的图像。对于深度图像,使用最近邻插值法对输入图像进行缩放;对于彩色图像,则使用双线性插值法。异常分数通过将输入图像与其重建图像按像素进行比较得出。
4.1.3.2 深度变异模型
深度变异模型(Depth Variation Model)处理原始分辨率的图像,并计算整个训练集在每个图像像素上的均值和标准差。同样,通过计算每个像素相对于训练分布的马氏距离来得出异常分数。
最近邻插值法
- 原理:取目标像素在原图像中最近邻像素的值作为自身像素值。
- 优势:计算简单、速度快。
- 不足:易产生锯齿、块状瑕疵,图像质量欠佳。
双线性插值法
- 原理:基于目标像素在原图像相邻(2×2)像素,先在(x)方向线性插值得中间值,再在(y)方向对中间值插值计算像素值。
- 优势:图像缩放更平滑,视觉效果好。
- 不足:计算量相对较大 。
4.1.4 Dataset Augmentation 数据集增强
由于除变异模型外,所评估的方法都需要大量训练数据,我们使用数据集增强来扩大训练集规模。
①对于每个物体类别,我们首先估算背景平面的法向量,该法向量在各样本间保持一致。
②然后,我们将每个数据集样本绕此法向量旋转一定角度。
③并利用内部相机参数将所得点及相应颜色值投影回原始二维图像网格。
我们通过从区间
[
−
5
∘
,
5
∘
]
[-5^{\circ}, 5^{\circ}]
[−5∘,5∘]中随机采样角度,对每个训练样本进行20次增强。
4.1.5 Computation of Anomaly Maps 异常图的计算
所有基于体素的方法都会为每个体素单元计算一个异常分数。然而,要在我们的数据集上比较它们的性能,需要将异常分数分配到原始((x, y, z))图像的每个像素上。因此,我们使用三维传感器的内部相机参数,将异常分数投影到像素坐标上。
4.1.5.1 将体素单元的异常分数映射到图像像素上
对于每个体素单元,我们投影其8个角点,并计算投影后所得点的凸包。该区域内的所有图像像素都被赋予相应体素单元的异常分数。如果一个像素被赋予了多个异常分数,我们选取其中的最大值。
4.1.5.2 深度图像已经为每个像素分配了分数
基于深度图像的方法已经为每个像素分配了分数。深度f - AnoGAN和深度自动编码器(Depth AE)的异常图通过双线性插值缩放至原始图像大小。
4.2 Results 结果
4.2.1 仅3D
4.2.1.2 定量结果
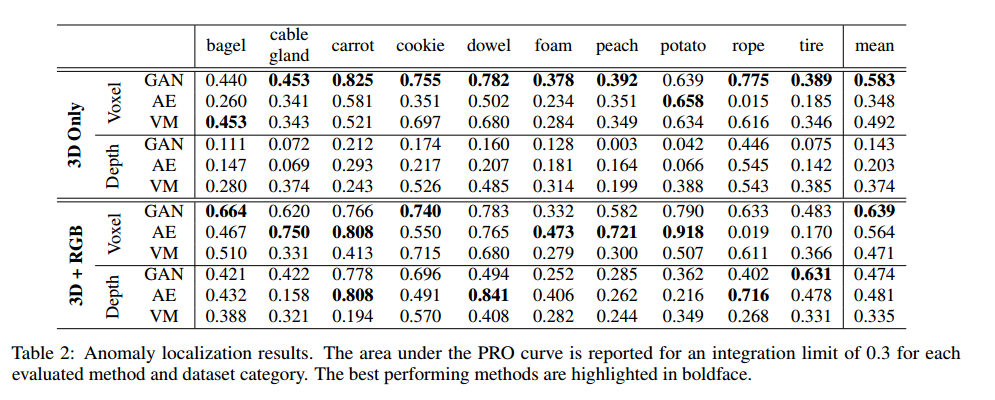
表2列出了每种异常定位评估方法的定量结果。对于每个数据集类别,我们报告PRO曲线下归一化面积,积分上限设为0.3。我们还进一步报告所有类别上的平均性能。在此,我们重点关注所评估方法的定位性能。样本级异常分类的结果可在附录中找到。
表2的前六行展示了每种方法仅在不提供任何颜色信息的3D传感器数据上训练时的性能。在这种情况下,体素f - AnoGAN在平均性能以及大多数数据集类别上表现最佳。其次是体素变异模型(Voxel VM),它在其中一个物体上表现出最佳性能。体素自动编码器(Voxel AE)的表现比另外两种基于体素的方法差。这是因为它往往会产生模糊且不准确的重建结果。为了让大家了解评估方法的重建质量,我们在附录中展示了一些定性示例。
平均而言,每种基于体素的方法表现都优于其基于深度图像的对应方法。在所有基于深度图像的方法中,深度变异模型(Depth Variation Model)表现最佳。我们发现,深度自动编码器(Depth AE)和深度f - AnoGAN 在输入数据中无效像素周围的异常图中产生了许多误报。
4.2.1.2 定性结果
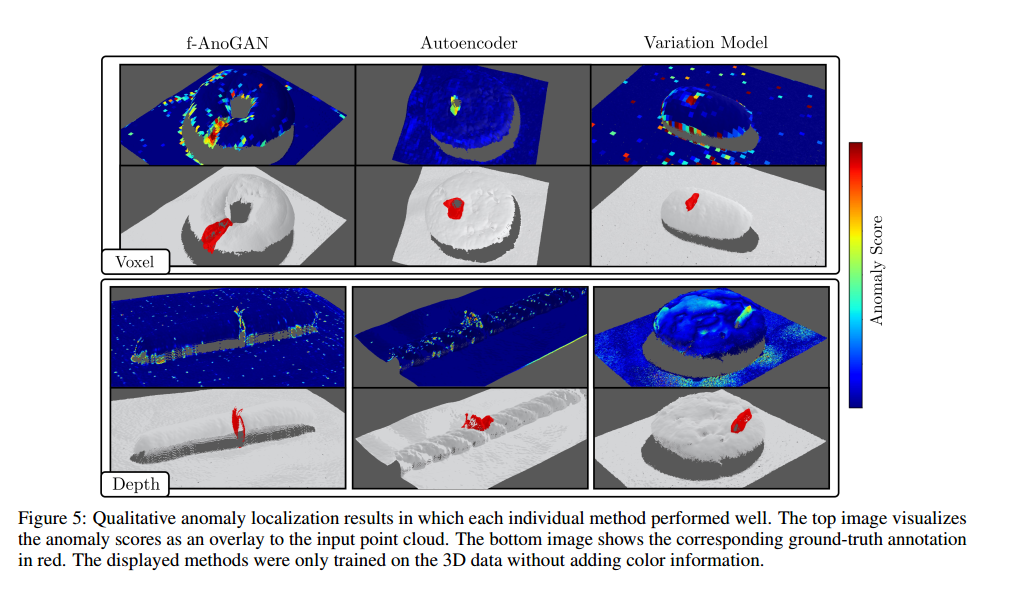
图5展示了相应的定性异常定位结果。为了便于可视化,预测的异常分数被投影到输入点云上。对于每个数据集样本,对应的真实标注以红色显示。虽然大多数方法能够定位我们数据集中的一些缺陷,但它们也产生了大量误报预测,无论是在物体表面、物体边缘还是在背景中。由于Voxel AE体素自动编码器重建不准确,它只能检测到我们数据集中较大且更明显的异常,如图5中所示的那种。
4.2.2 3D+RGB
4.2.2.1 定量结果
除了仅在3D数据上评估每种方法外,我们还报告了在每个3D点都使用RGB特征进行训练时这些方法的性能。结果列在表2的后六行。添加RGB信息提高了除变异模型外所有方法的性能。由于RGB图像不包含无效像素,深度自动编码器和深度f - AnoGAN从颜色信息中受益最大。尽管如此,基于体素的方法仍然优于其基于深度图像的对应方法。同样,体素f - AnoGAN总体表现最佳。不过,对于某些物体类别,在包含颜色信息时,体素自动编码器的表现优于体素f - AnoGAN。
4.2.2.2 选择合适的积分上限来计算PRO曲线下面积
如3.3节所讨论的,选择合适的积分上限来计算PRO曲线下的面积非常重要。为了说明这一点,图6展示了每种评估方法的性能对积分上限的依赖性。
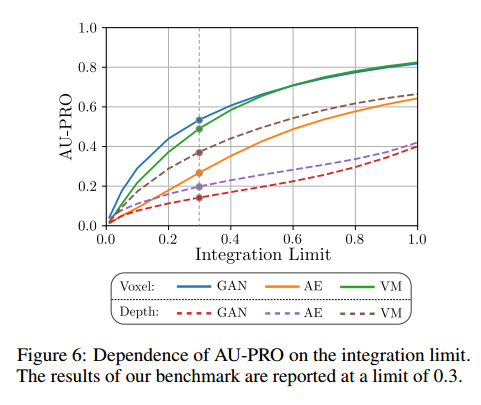
所有方法的PRO曲线下面积(AU - PRO)都呈单调增加。当积分到误报率为1时,体素f - AnoGAN和体素变异模型的AU - PRO超过0.8,这表明这些方法几乎能解决该任务。然而,在大积分上限下进行评估时,二元分割掩码中误报预测的数量极高。由于我们数据集中存在的缺陷面积与无异常像素的面积相比非常小,这样的分割结果不再有意义。我们发现所评估方法的性能对于实际应用来说是不够的。
因此,我们选择0.3作为积分上限,以便比较它们的相对性能。在未来,我们希望我们的数据集能激发在更低积分上限下实现高AU - PRO分数的方法的开发。在实际工业检测场景中,0.3的误报率几乎是不可接受的。
5 CONCLUSION 结论
我们提出了一个用于无监督异常检测和定位任务的综合性3D数据集。该数据集的概念设计和采集灵感来源于现实世界中的视觉检测任务。它由4000多个点云组成,描绘了十种不同物体类别的实例。这些数据是使用高分辨率结构光3D传感器采集的。数据集中约1000个样本包含各种类型的异常,并且我们为所有样本提供了精确的真实标注。
我们对现有的少数方法进行了初步基准测试,结果表明这些方法仍有很大的改进空间。特别是,所评估方法的准确性不足以应用于现实世界的工业场景。我们坚信合适的数据集是新技术发展的关键因素,并期望我们的数据集能够在未来激发更好方法的设计。
6 APPENDIX 附录
6.1 Details on Training Parameters 训练参数的细节
在本节中,我们将详细介绍基于深度学习方法的训练参数以及模型架构。
6.1.1 Voxel f-AnoGAN
对于体素f - AnoGAN的实现,我们采用Simarro Viana等人(2021)提出的相同网络架构。生成对抗网络(GAN)和编码器网络都在增强版的数据集上训练50个轮次(epochs),使用Adam优化器(Kingma和Ba,2015) ,初始学习率为0.0002 ,批量大小为2 。GAN的梯度惩罚损失权重设为10 ,每进行5次判别器训练迭代,进行1次生成器训练迭代。在编码器的训练过程中,“izi”和“ziz”损失通过选择损失权重为1来赋予相等的权重。
6.1.2 Voxel Autoencoder
体素自动编码器由一个编码器网络和一个解码器网络组成。它们的架构分别与体素f - AnoGAN中的编码器和生成器架构相同。我们在增强版的数据集上训练50个轮次,批量大小为2,使用Adam优化器,初始学习率为0.0001。
6.1.3 Depth f-AnoGAN
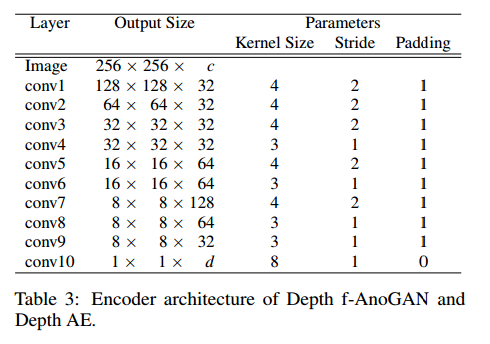
深度f - AnoGAN由三个子网络组成,即编码器、判别器和生成器。
编码器的架构见表3。它由10个卷积块堆叠而成,可将尺寸为
256
×
256
256×256
256×256像素、
c
c
c通道的输入图像压缩为
d
d
d维潜在向量。除最后一个卷积块外,每个卷积块后面都接一个实例归一化层(Ulyanov等人,2017 )和斜率为0.05的LeakyReLU激活函数。
判别器的架构与编码器相同,只是
d
=
1
d = 1
d=1 。
生成器从
d
d
d维潜在变量生成尺寸为
256
×
256
256×256
256×256像素、
c
c
c通道的图像。其架构与表3中的架构对称,只是卷积层被转置卷积层取代。
生成对抗网络(GAN)和编码器网络都使用Adam优化器,以4为批量大小、0.0002为初始学习率,训练50个轮次。在编码器的训练过程中,通过选择损失权重为1,使“izi”和“ziz”损失具有相等的权重。
6.1.4 Depth Autoencoder
对于深度自动编码器(Depth AE)的编码器和解码器,我们分别采用与深度f - AnoGAN的编码器和生成器相同的架构。使用Adam优化器进行训练,训练轮次为50,批量大小为32,初始学习率为0.0001。
6.2 Depth Autoencoder 基于压缩方法的潜在维度
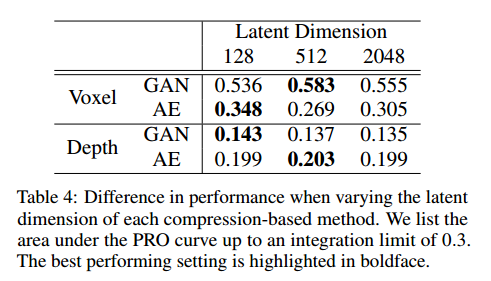
为了给所评估的基于压缩的方法选择合适的潜在维度,我们进行了消融研究。表4给出了这些方法在所有物体类别上的平均性能。对于第4节中的实验,我们使用在消融研究中产生最佳平均性能的相应潜在维度。
6.3 Results for Anomaly Classification 异常分类结果
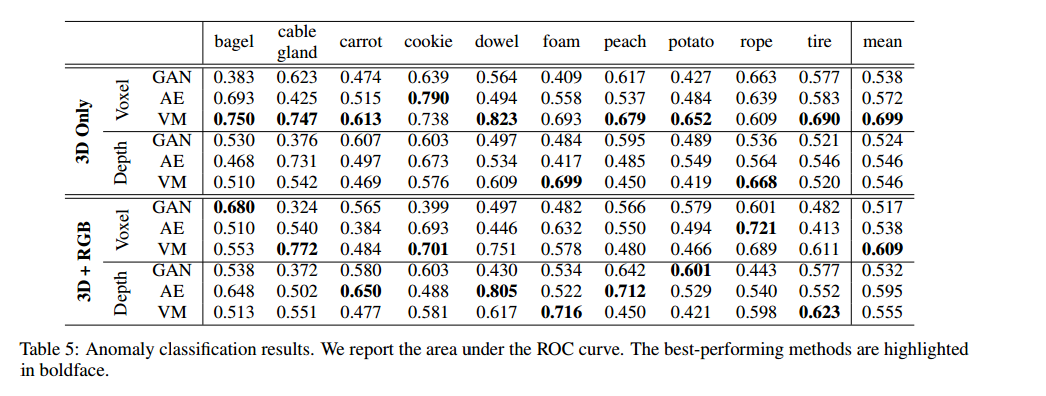
除了表2中的异常定位结果外,我们还给出了将数据集样本分类为异常或无异常的结果。由于这要求一种方法为每个数据集样本输出单个异常分数,我们计算每个异常图中的最大异常分数。作为性能度量,我们计算受试者工作特征曲线(ROC)下的面积。表5列出了结果。
6.4 Quality of Reconstructions 重建的质量
对于基于自动编码器(AE)或生成对抗网络(GAN)的方法,异常检测性能在很大程度上取决于它们的重建质量。为了解重建质量的情况,图7展示了每种评估方法的两个示例。
6.4.1 基于体素的方法
为了可视化基于体素的方法,通过对每个体素单元应用阈值,将体素网格转换为点云。如果一个体素单元的值为0.9或更高,则被分类为已占用。
体素自动编码器(Voxel AE)往往会在物体表面周围产生模糊的重建结果。体素f - AnoGAN则没有这个问题。然而,它有时无法重建输入的某些部分。
6.4.2 基于深度图像的方法
对于基于深度图像的方法,输入和重建结果都可视化为深度图像。 较深的蓝色阴影表示离相机中心较远的点。白色点表示无效像素。
深度f - AnoGAN和深度自动编码器(Depth AE)在重建存在许多无效像素的嘈杂区域时都表现出问题。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









