






算力资源作为智能化发展的核心动力,正呈现爆发式增长,推动了企业AI应用落地从数月缩短至几周。
英伟达GPU芯片凭借卓越的算力效能和CUDA生态垄断,成为企业私有化部署炙手可热的选择。
对于市面上这些热门的GPU芯片你都了解多少?是否真的适配于企业的适用场景?本篇文章将针对英伟达热门的九款GPU芯片做分析对比,帮助企业快速认知与合理选择。

技术特性解析
1、H800 vs H20:训练与推理的权衡
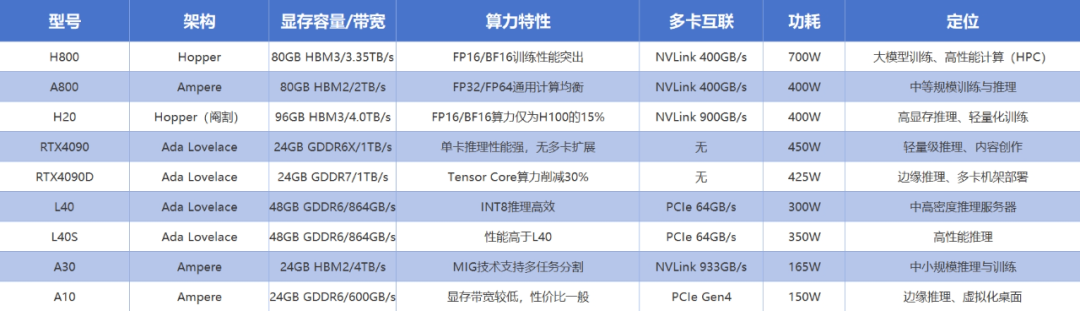
H800:Hopper架构的完整版,适合千亿参数大模型训练,尤其在FP16/BF16混合精度场景下性能显著。其显存带宽(3.35TB/s)和互联能力(400GB/s)高。
H20:显存带宽提升至4.0TB/s,NVLink带宽高达900GB/s,但算力仅为H100的15%。适合多卡集群推理场景(如推荐系统、图像识别),但单卡算力低,需通过数量弥补性能缺陷。
2、A800 vs A30:性价比与通用性
A800:Ampere架构的合规版,FP32/FP64性能均衡,适合中等规模模型训练(如金融风控模型)和HPC仿真。40GB显存可处理中等数据集,但NVLink带宽限制为400GB/s,扩展性弱于H800。
A30:显存容量与A800相当,但功耗更低(165W),支持MIG技术(将单卡分割为7个实例),适合多租户推理服务(如云游戏、视频处理)。
3、4090 vs 4090D:消费级显卡
RTX4090:Ada架构的消费级旗舰,24GB显存适合轻量级AI推理(如文本生成、图像分类)和4K内容渲染。但无多卡互联能力,长期高负载稳定性较差。
RTX4090D:中国特供版,相比于4090核心数减少,Tensor Core下降,算力略低于4090。
4、推理专用卡:L40/L40S与A10
L40:48GB GDDR6显存与高带宽(864GB/s),INT8算力达239TOPS,适合高密度推理(如自然语言处理)。支持PCIe Gen4,兼容主流服务器架构。
A10:显存带宽较低(600GB/s),适合虚拟化桌面和轻量推理,但性能已被国产推理卡超越。
适用场景分析
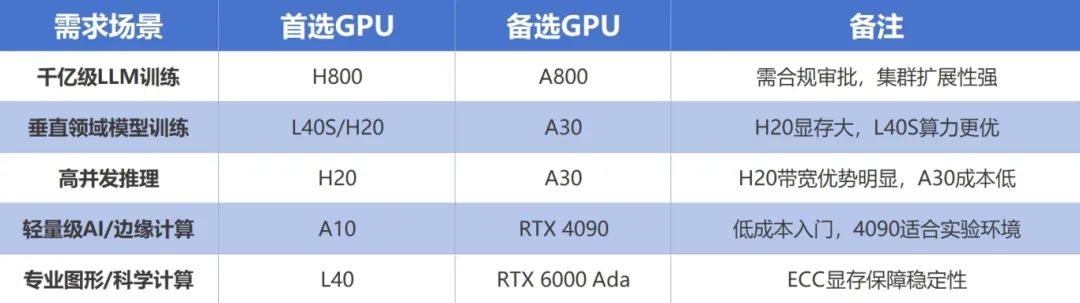
1、大规模AI训练(千亿参数级LLM)
首选:H800高算力(312 TFLOPS FP16)+ 高带宽(3TB/s),适合分布式训练,NVLink支持多卡高效协同。
次选:A800性能接近H800,但带宽较低(2TB/s),仍可满足大模型训练需求,是A100的合规替代品。
H20算力仅为H100的15%,虽带宽高(4TB/s),但单卡性能不足,需超大规模集群弥补,费效比低。
2、中小规模训练/垂直领域模型
L40/L40S
48GB显存+Ada架构优化,适合中等参数模型(如10B~30B)训练,支持NVLink,适合企业级工作站部署。
H20
高显存(96GB)+高带宽,适合行业大模型(如医疗、金融)训练,但算力限制使其无法胜任千亿级LLM。
3、AI推理(高并发/低延迟)
H20
高显存带宽(4TB/s)和NVLink 900G/s,适合高吞吐推理(如DeepSeek部署),近期因需求激增价格暴涨。
A30/A10
低功耗+24GB显存,适合轻量推理(如推荐系统、NLP服务),A10更侧重虚拟化场景。
RTX 4090/4090D
消费级高性价比选择,适合中小型企业部署轻量模型(如7B参数以下),但无NVLink,多卡扩展性差。
4、图形渲染/科学计算
L40/L40S
专业级显卡,支持ECC显存,适合影视渲染、CAD设计等,兼顾AI计算。
RTX 4090
消费级最强单卡,适合实时渲染、云游戏等,但企业级支持有限。
高端训练集群:H800/A800仍是黄金标准,但受政策限制,H20可作为合规替代,但需接受算力折损。
性价比推理:H20因带宽优势成为大厂首选,但A30/A10更适合中小规模部署。
消费级替代:RTX 4090/4090D适合预算有限的企业,但缺乏企业级支持与扩展性。
不同的GPU显卡有不同的适应场景,企业应根据实际业务规模、预算及合规要求综合考虑合理选择。
万云智算
万云智算通过API直连东数西算节点、京津冀、长三角等10大核心区域,超50个机房,将分散的CPU、GPU、存储等资源整合为“算力资源池”,并通过智能调度引擎实现毫秒级匹配。
通过“算力资源+AI平台+场景化工具”的一体化方案,将算力基础与AI开发服务一体化,并根据特定业务场景和需求进行大模型训练和优化,精准解决企业实际问题,推动业务模式创新,实现“资源即服务”。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









