







题目:Complementary Pseudo Multimodal Feature for Point Cloud Anomaly Detection
题目:用于点云异常检测的互补伪多模态特征
论文地址:Pattern Recognition 中科院一期 2024 2303
Complementary 互补的
Pseudo 伪
Multimodal 多模态
Feature 特征
for
Point Cloud Anomaly Detection 点云异常检测
Abstract 摘要
点云(PCD)异常检测正逐渐成为一个极具潜力的研究领域。本研究旨在通过结合手工制作的点云描述符与强大的预训练二维神经网络,提升点云异常检测性能。为此,本研究提出了互补伪多模态特征(CPMF),该特征在三维模态中利用手工制作的描述符纳入局部几何信息,并在生成的伪二维模态中利用预训练二维神经网络提取全局语义信息。对于全局语义提取,CPMF将原始点云投影为包含多视图图像的伪二维模态。这些图像被输入预训练二维神经网络,以提取信息丰富的二维模态特征。三维和二维模态特征经过聚合,得到用于点云异常检测的CPMF。大量实验证明了二维和三维模态特征之间的互补能力,以及CPMF的有效性。在MVTec3D基准测试中,CPMF取得了95.15%的图像级受试者工作特征曲线下面积(AU - ROC)和92.93%的像素级PRO指标成绩。代码可在https://github.com/caoyunkang/CPMF获取。
Index Terms—Point Cloud; Anomaly Detection; Pretrained representation; Multimodal Learning; Rendering.
关键词:点云;异常检测;预训练表示;多模态学习;渲染
1 INTRODUCTION 简介
1.1 点云的出现
随着三维采集传感器和设备的蓬勃发展,点云(PCD)因其能明确捕捉现实世界物体的几何信息而备受青睐。与此同时,点云异常检测,即检测三维结构中偏离正常模式的异常点,成为工业检测[1 - 3]和医学诊断[4]中一个极具潜力的研究方向。然而,由于使用点云进行异常检测的实践才刚刚兴起,其在实际应用中的性能远不尽如人意。本研究聚焦于点云异常检测,试图通过协同整合局部几何线索和全局语义线索,来满足实际性能需求。
1.2 点云特征的表示
先前针对图像[5]和图形的异常检测方法表明,独特的特征表示[6]对于成功检测至关重要。同样,近期的点云异常检测方法[1 - 3]也认识到了特征学习=的重要性。早期的点云表示是手工制作的,依赖于启发式设计[7, 8] 。随着深度学习的发展,近期的方法采用了基于学习的点云特征。基于这些丰富的点云表示,3D - ST [2] 设计了一种用于点云异常检测的自监督学习方案。尽管与基线方法[1]相比有了显著改进,但其性能仍不理想。BTF [3] 揭示了特征描述能力在点云异常检测中的重要性。与预期相反,结果表明经典的手工制作点云描述符优于基于学习的预训练特征。BTF将这种现象归因于目标物体与预训练数据集之间的域分布差距,这导致了预训练点云特征的迁移能力较低。然而,尽管经典的手工制作特征取得了令人瞩目的性能,但它们仅限于使用局部结构信息,无法获取全局语义信息。由于全局语义信息在检测语义异常方面至关重要[5, 9] ,将其与手工制作特征的几何建模能力相结合,有望带来性能提升。
1.3 图像异常检测
与点云异常检测相比,图像异常检测[10, 11]更为成熟,研究也更为广泛。早期的图像异常检测方法[12]专注于仅使用正常数据学习描述性特征,并逐渐发展出了虽优秀但仍不尽人意的性能。经过深入研究,近期的方法[5, 13 - 16]发现,来自预训练二维神经网络的表示足以用于异常检测,他们将这种稳定的性能归因于预训练表示中隐藏的几何和语义信息。具体而言,预训练图像表示利用了来自大规模图像数据集(如ImageNet [17] )的先验知识,因此它们擅长捕捉有意义的全局语义线索,且具有出色的迁移能力。
1.4 点云+图像启发:统一的点云表示方法
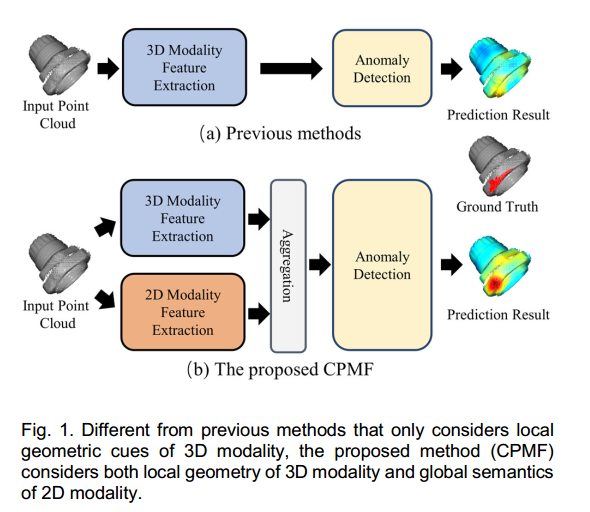
受现有点云与图像异常检测方法所取得的显著成果启发,本研究提出一种统一的点云表示方法,即互补伪多模态特征(CPMF),以充分利用点云中的局部几何结构和全局语义信息。基于手工制作的点云描述符,CPMF在生成的伪二维模态中进一步利用具有描述能力的预训练二维神经网络,来丰富点云描述符的语义内容。现有方法[1 - 3]仅在三维模态上进行特征提取,而本方法利用生成的伪多模态数据捕捉互补的结构和语义线索,提升了点云异常检测性能,如图1所示。
1.5 CPMF
1.5.1 特征提取
从技术层面来看,在三维模态特征提取方面,CPMF利用经典的手工制作描述符捕捉点云中精确的局部几何信息。CPMF还纳入了一个二维模态特征提取模块,该模块利用预训练二维神经网络强大的描述能力,挖掘并补充点云中隐藏的语义信息。
1.5.2 特征映射
特别地,此模块通过三维到二维的投影和渲染,将原始三维点云转换为包含多视图二维图像的伪二维模态。然后,该模块利用预训练二维神经网络提取这些多视图图像的强语义特征图。随后,在二维到三维的对齐和聚合过程中,特征图根据各个视图中的二维 - 三维投影对应关系,映射为逐点特征。
1.5.3 特征聚合
这些单视图逐点特征进一步聚合,以获取最终的二维模态逐点特征,这些特征融合了不同视图的信息。
所提取的三维和二维模态特征具有高度互补性,原因如下:
1)三维手工制作特征擅长描述局部结构,但无法利用全局语义信息[3, 7] 。
2)二维预训练网络包含来自大规模图像数据集的丰富知识,能够捕捉语义属性,但无法精确表示局部结构[5, 15] 。
因此,CPMF开发了一个聚合模块,融合三维和二维模态特征,得到同时包含全局语义和局部几何信息的特征。图1表明,CPMF的性能在定性上优于先前的方法[3] 。
1.6 本研究的贡献和结构
本研究的贡献总结如下:
- 本研究探讨了点云(PCD)异常检测问题,开发了互补伪多模态特征(CPMF)方法,通过在伪多模态中提取点云特征,协同整合点云中的局部几何线索和全局语义线索。
- 本研究提出了一种新颖的方法,通过在通过投影和渲染生成的伪二维模态中使用预训练二维网络,获取逐点语义点云特征。所提取的二维模态特征展现出卓越的点云描述能力。
- 本研究证明了三维和二维模态特征之间的互补能力,并表明CPMF在点云异常检测中取得了优异的性能,大幅超越了现有的点云异常检测方法。
本文的结构安排如下。第二节全面回顾相关工作。第三节阐述所提出的CPMF。第四节展示并分析实验。最后,第五节对本文进行总结,并讨论未来的研究方向。
2 RELATED WORK
相关工作从三个主题进行综述:二维图像异常检测、三维点云(PCD)异常检测以及点云特征学习。
2.1 2D Image Anomaly Detection 二维图像异常检测
2.1.1 特征提取与特征建模
二维图像异常检测是一个研究广泛的任务,尤其是在工业检测数据集MVTec AD [10] 建立之后。典型的二维图像异常检测方法由两个模块组成,即特征提取模块和特征建模模块。
①特征提取模块致力于获取具有更强描述能力的特征;理想情况下,正常特征和异常特征应能被清晰区分。
②特征建模模块经过训练对正常特征的分布进行建模,并且期望在输入异常特征时出现偏差。
2.1.2 从零开始学习描述性特征
早期的工作[12, 18 - 21]从零开始学习描述性特征。AESSIM [19] 使用自动编码器和结构相似性(SSIM)损失函数,通过重建任务来学习特征。RIAD [12] 进一步开发了修复任务,以学习更好的特征表示。随后,DRAEM [18] 开发了去噪重建策略,并直接预测异常分割图。不同的是,Cutpaste [20] 通过异常合成构建了一种自监督特征学习方案。
2.1.3 利用预训练网络的表示
尽管早期方法取得了不错的性能,但预训练网络的表示对于异常检测来说是有效且具有吸引力的[5, 13 - 16, 22, 23] 。ST [15]、IKD [5] 和AST [16] 都利用知识蒸馏对正常特征分布进行建模。
ST [15] 通过一个预训练的教师网络和一个随机初始化的学生网络,对齐正常特征。对齐误差用于对异常进行评分。
IKD [5] 通过一个上下文相似性损失函数和动态难样本挖掘策略,实现了更好的描述能力。
AST [16] 通过使用非对称教师 - 学生网络架构缓解了异常检测中的过泛化问题。
同样,CDO [22] 生成合成异常,并开发了一种新的协同差异优化损失函数来解决过泛化问题。
其他方法则探索了更多可能性,如归一化流建模[22] 和记忆库[22] ,用于正常特征分布建模。
2.2 3D PCD Anomaly Detection 三维点云异常检测
尽管二维图像异常检测已有深入研究,但三维点云(PCD)异常检测尚未得到充分探索。首个真实世界三维异常检测数据集MVTec 3D [1] 发布后,三维点云异常检测受到更多关注。
用于点云异常检测的特征建模模块在很大程度上受图像异常检测方法影响。然而,由于图像和点云特性差异极大,点云异常检测中的特征提取模块需要重新设计。因此,近期点云异常检测方法强调特征学习的重要性。
基线方法[1] 对先前的竞争方法进行了全面基准测试,如变体模型[24]和自动编码器[25] 。
3D - ST [2] 为点云表示学习设计了一种自监督学习方案,并采用知识蒸馏进行异常检测。
此外,BTF [3] 通过全面实验强调了经典手工制作点云描述符的有效性,但也观察到学习到的特征表现不佳。BTF将这种违反直觉的情况归因于现有预训练特征在小规模点云数据集上的迁移能力不足。
尽管手工制作的特征在异常检测中取得了相当的性能,但它们很难捕捉点云中的语义信息,因为其设计多基于启发式。
由于语义信息对异常检测至关重要,本研究旨在弥补点云表示中语义信息的缺失并生成更好的点云表示。
2.3 PCD Feature Learning 点云特征学习
大量文献针对三维抓取检测[26]和三维配准[8]等热门三维应用研究了点云表示。
现有方法大多直接在三维模态中提取点云特征。
2.3.1 启发式对几何信息建模
经典方法[7, 8]依赖启发式设计对几何信息进行建模。
例如,快速点特征直方图(FPFH)[7] 是一种著名的鲁棒且高效的三维描述符,它结合了点坐标和表面法向量来表示点云特性。
[8] 中提出了一种更先进的基于静电场理论的点描述符,并用于表面零件质量检测。
2.3.2 神经网络架构进行点云表示学习
后来,许多研究为点云表示学习开发了神经网络架构[27 - 29] 。
PointNet [27] 及其扩展(如PointNet++ [28] )对输入点云数据进行处理,并以端到端的方式学习点级表示。
基于这些点云骨干网络,社区设计了更好的特征学习方法,如自监督学习。
FCGF [30] 通过全卷积设计和点级度量学习来学习局部特征描述符。
PointContrast[31] 进一步改进了FCGF并将其应用于语义理解,开发出更好的语义表示。
2.3.3 将原始点云渲染为包含多视图图像的二维模态
相比之下,一些研究通过将原始点云渲染为包含多视图图像的二维模态,利用了成熟的二维表示。
多视图卷积神经网络[32]率先研究了点云的多视图表示。它将点云转换为多视图图像,然后输入多视图卷积神经网络以提取实例级特征。
局部形状描述符[33] 通过局部点对之间的对应关系学习逐点特征。具体来说,它将局部点对补丁输入多视图图像,然后将度量学习应用于这些图像,以进行补丁级描述性点特征学习。
后续方法[34, 35] 强调了视图选择和聚合的重要性。
2.3.4 本研究
本研究针对点云异常检测任务,特别是描述性点云特征学习。本研究提出一种方法,统一三维模态和生成的伪二维模态来全面表示点云数据。由于二维和三维模态特征之间具有互补性,最终的点云表示融入了局部结构和全局语义知识,提升了点云异常检测的性能。
3 PROPOSED METHOD
在本节中,将详细解释互补伪多模态特征(CPMF)方法。首先,定义点云数据(PCD)异常检测问题。然后,介绍CPMF的流程。随后,展示所提出的CPMF的关键组成部分,包括三维模态特征提取、二维模态特征提取、聚合操作,以及相应的异常检测过程。
3.1 Problem definition 问题定义
给定一个包含 N N N个点的三维点云数据 P 3 D = { p 1 , p 2 , … , p N ∈ R 3 } P_{3D}=\{p_1, p_2, \ldots, p_N \in \mathbb{R}^3\} P3D={p1,p2,…,pN∈R3}作为输入,点云异常检测的目标是为所有点输出实值异常分数 S = { s 1 , s 2 , … , s N } S = \{s_1, s_2, \ldots, s_N\} S={s1,s2,…,sN},其中异常点被赋予较高的分数。然后,可以根据异常分数定位 P 3 D P_{3D} P3D中的异常区域 。通常,在训练阶段可以获取仅包含正常点云的点云集合 P t r a i n = { P 3 D } \mathbb{P}_{train}=\{P_{3D}\} Ptrain={P3D} 。在测试阶段,需要输出未知点云集合 P t e s t = { P 3 D t e s t } \mathbb{P}_{test}=\{P_{3D}^{test}\} Ptest={P3Dtest}中的异常分数 S = { s } S = \{s\} S={s} 。
3.2 Pipeline Overview 流程概述
现有的点云数据(PCD)异常检测方法[2, 3, 16]专注于提取高区分度的点云特征。然而,它们所提取的特征不够理想,几乎不足以进行令人印象深刻的异常检测。为充分挖掘点云数据的潜在信息和特性,本研究提出一种名为互补伪多模态特征(CPMF)的全新特征,该特征分别通过精心设计手工制作的三维点云描述子和预训练的二维神经网络来利用局部几何信息和全局语义表征。
3.2.1 分别提取二维和三维特征
如图2所示,CPMF主要由三维模态特征提取模块和二维模态特征提取模块组成。这两个模块均可为点云数据提取逐点描述性特征。CPMF首先将输入点云
P
3
D
P_{3D}
P3D输入到这两个模块中,分别提取三维模态特征
F
3
D
F_{3D}
F3D和二维模态特征
F
2
D
F_{2D}
F2D。
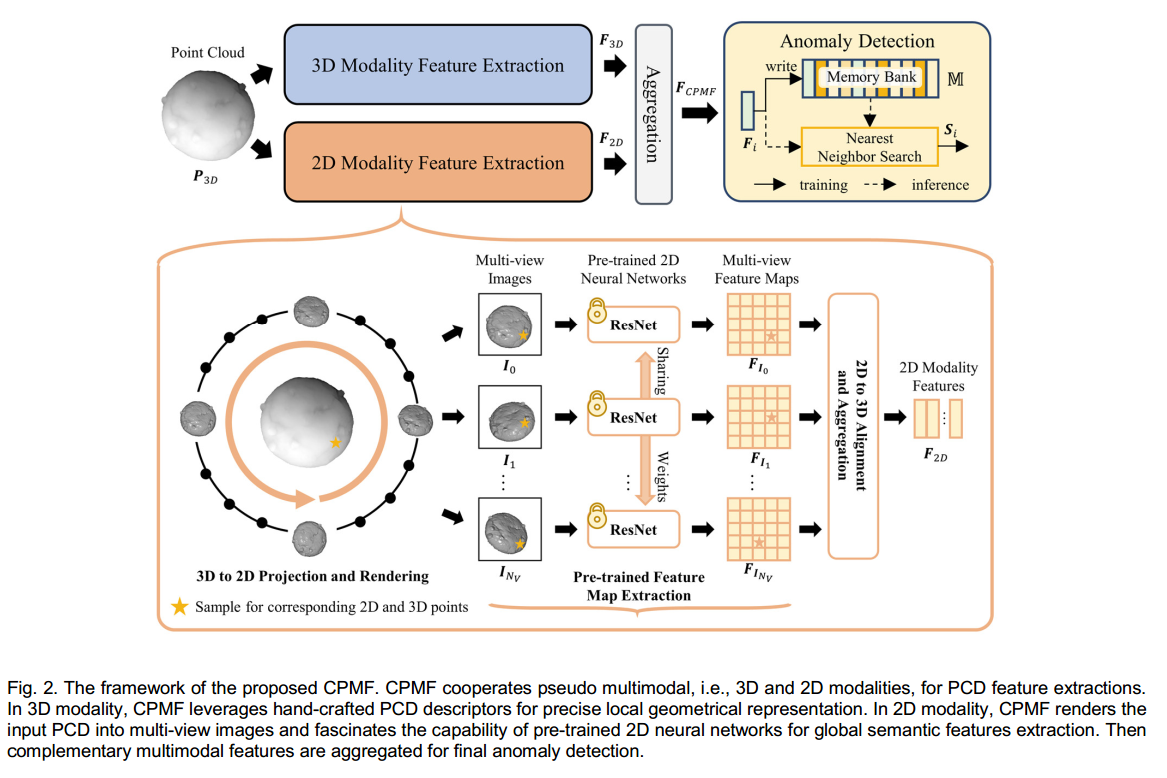
对于三维模态特征提取,直接使用手工设计的点云描述子来表示
P
3
D
P_{3D}
P3D的局部结构。
二维模态特征提取模块首先将原始三维点云
P
3
D
P_{3D}
P3D投影到包含多视图图像的二维模态中,然后将其进一步输入到预训练的二维神经网络中,以提取有区分度的语义特征图。接着,将这些特征图映射到三维空间,生成逐点二维模态特征
F
2
D
F_{2D}
F2D 。
3.2.2 互补伪多模态特征
F
3
D
F_{3D}
F3D和
F
2
D
F_{2D}
F2D包含互补知识,因为它们以不同方式利用
P
3
D
P_{3D}
P3D的信息。具体而言,
F
3
D
F_{3D}
F3D考虑相邻点之间的局部信息,而
F
2
D
F_{2D}
F2D包含从具有大感受野和丰富语义知识的预训练二维神经网络继承而来的强语义信息[15]。
CPMF将它们聚合在一起,生成互补伪多模态特征
F
C
P
M
F
F_{CPMF}
FCPMF 。
最后,
F
C
P
M
F
F_{CPMF}
FCPMF与PatchCore[23](一种使用最近邻搜索的优秀异常检测方法)协同工作,用于点云异常检测。
在接下来的小节中,本文将依次描述三维模态特征提取模块、二维模态特征提取模块、聚合操作以及异常检测过程。
3.3 3D Modality Feature Extractor 3D模态特征提取器:直接利用的BTF
长期以来,人们一直在研究点云数据(PCD)特征提取,从早期的手工设计特征[7, 8, 36]到近期基于学习的深度特征[2, 30] 。尽管基于学习的特征在某些任务上表现出色,但事实证明,对于点云异常检测而言,它们不如手工设计的方法[2, 3, 7]有效。因此,本研究沿用现有方法[3],利用手工设计的描述子直接提取三维模态下点云数据的局部几何信息。将三维特征提取函数记为
F
3
D
\mathcal{F}_{3D}
F3D,则通过下方式获得三维特征
F
3
D
F_{3D}
F3D:
F
3
D
=
F
3
D
(
P
3
D
)
(1)
F_{3D} = \mathcal{F}_{3D}(P_{3D}) \tag{1}
F3D=F3D(P3D)(1)
其中
F
3
D
∈
R
N
×
D
3
D
F_{3D} \in \mathbb{R}^{N \times D_{3D}}
F3D∈RN×D3D,
D
3
D
D_{3D}
D3D是三维模态特征的维度。
3.4 2D Modality Feature Extractor 2D模态特征提取器:伪二维模态逐点特征
在手工设计的点云描述子基础上,为进一步提升异常检测性能,本研究提议通过预训练的二维神经网络[5, 37, 38]以及二维 - 三维投影对应关系,生成伪二维模态逐点特征。具体而言,对于输入点云,采用三维到二维的投影和渲染操作来生成渲染多视图图像
{
I
1
,
I
2
,
⋯
,
I
N
V
}
\{I_1, I_2, \cdots, I_{N_V}\}
{I1,I2,⋯,INV},其中
I
∈
R
H
×
W
×
3
I \in \mathbb{R}^{H \times W \times 3}
I∈RH×W×3 ,
H
×
W
H \times W
H×W是渲染图像的空间分辨率,
N
V
N_V
NV是渲染视图数量。
然后,对于预训练特征图提取,使用预训练的二维神经网络为多视图图像提取特征图。为便于后续二维到三维的映射,将特征图上采样到与原始图像相同的分辨率,上采样后的特征图记为
{
F
I
}
\{ \boldsymbol{F}_I \}
{FI},其中
F
I
∈
R
H
×
W
×
D
2
D
\boldsymbol{F}_I \in \mathbb{R}^{H \times W \times D_{2D}}
FI∈RH×W×D2D ,
D
2
D
D_{2D}
D2D是提取特征的维度。最终,将图像特征图
{
F
I
}
\{ \boldsymbol{F}_I \}
{FI}映射到原始三维空间,得到逐点二维模态特征
F
2
D
∈
R
N
×
D
2
D
\boldsymbol{F}_{2D} \in \mathbb{R}^{N \times D_{2D}}
F2D∈RN×D2D。
3.4.1 3D to 2D Projection and Rendering 3D到2D的投影和渲染
为利用成熟的预训练二维神经网络的表征能力,本研究通过图像渲染操作生成多视图图像,并将这些图像输入二维神经网络以提取多视图图像特征图。
3.4.1.1 渲染函数 R \mathcal{R} R
给定一个相机模型参数集
C
C
C,渲染函数
R
\mathcal{R}
R将点云
P
3
D
P_{3D}
P3D渲染为图像
I
I
I,可表示为:
I
=
R
(
P
3
D
,
C
)
(2)
I = \mathcal{R}(P_{3D}, C) \tag{2}
I=R(P3D,C)(2)
3.4.1.2 空间中三维点与其在二维像素坐标中的对应关系
为便于后续二维到三维的对齐与聚合,有必要获取空间中三维点与其在二维像素坐标中的对应关系,即二维 - 三维投影对应关系。设
P
3
D
,
i
P_{3D,i}
P3D,i为第
i
i
i个三维点的位置,
P
2
D
,
i
P_{2D,i}
P2D,i为其在像素坐标中的对应位置,
P
2
D
∈
R
n
×
2
P_{2D} \in \mathbb{R}^{n \times 2}
P2D∈Rn×2 ,二维 - 三维投影对应关系可表示为:
[
P
2
D
,
i
,
1
]
T
=
1
Z
c
K
T
[
P
3
D
,
i
,
1
]
T
(3)
\begin{bmatrix} P_{2D,i}, 1 \end{bmatrix}^{\mathrm{T}} = \frac{1}{Z_c} \boldsymbol{K} \boldsymbol{T} \begin{bmatrix} P_{3D,i}, 1 \end{bmatrix}^{\mathrm{T}} \tag{3}
[P2D,i,1]T=Zc1KT[P3D,i,1]T(3)
其中
K
\boldsymbol{K}
K和
T
\boldsymbol{T}
T分别是渲染相机的内参矩阵和外参矩阵;
1
/
Z
c
1/Z_c
1/Zc是归一化坐标系数。
3.4.1.3 三维到二维渲染导致点云信息缺失:不同的旋转矩阵对点云进行旋转后再渲染
随着渲染操作投影到较低的维度,由于从三维到二维的渲染操作会导致点云
P
3
D
P_{3D}
P3D的部分信息丢失[32]。为保留
P
3
D
P_{3D}
P3D的完整信息,本研究依次用不同的旋转矩阵
{
R
1
,
R
2
,
⋯
,
R
N
V
}
\{ \boldsymbol{R}_1, \boldsymbol{R}_2, \cdots, \boldsymbol{R}_{N_V} \}
{R1,R2,⋯,RNV} ,
R
∈
R
3
×
3
\boldsymbol{R} \in \mathbb{R}^{3 \times 3}
R∈R3×3 旋转
P
3
D
P_{3D}
P3D进行渲染。具体而言,对于第
k
k
k次旋转图像中第
i
i
i个点:
P
3
D
,
k
,
i
=
R
k
P
3
D
,
i
(4)
P_{3D,k,i} = \boldsymbol{R}_k P_{3D,i} \tag{4}
P3D,k,i=RkP3D,i(4)
及其对应的渲染图像
I
k
I_k
Ik和二维位置
P
2
D
,
k
,
i
P_{2D,k,i}
P2D,k,i可通过下式得到:
I
k
=
R
(
P
3
D
,
k
,
C
)
(5)
I_k = \mathcal{R}(P_{3D,k}, C) \tag{5}
Ik=R(P3D,k,C)(5)
[
P
2
D
,
k
,
i
,
1
]
T
=
1
Z
c
K
T
[
P
3
D
,
k
,
i
,
1
]
T
(6)
\begin{bmatrix} P_{2D,k,i}, 1 \end{bmatrix}^{\mathrm{T}} = \frac{1}{Z_c} \boldsymbol{K} \boldsymbol{T} \begin{bmatrix} P_{3D,k,i}, 1 \end{bmatrix}^{\mathrm{T}} \tag{6}
[P2D,k,i,1]T=Zc1KT[P3D,k,i,1]T(6)
具体来说,旋转矩阵
R
\boldsymbol{R}
R通过在
x
x
x、
y
y
y、
z
z
z轴上选择不同角度
θ
x
\theta_x
θx、
θ
y
\theta_y
θy、
θ
z
\theta_z
θz得到,
R
\boldsymbol{R}
R表示为:
R
=
[
cos
θ
x
sin
θ
x
0
−
sin
θ
x
cos
θ
x
0
0
0
1
]
[
cos
θ
y
0
sin
θ
y
0
1
0
−
sin
θ
y
0
cos
θ
y
]
[
1
0
0
0
cos
θ
z
sin
θ
z
0
−
sin
θ
z
cos
θ
z
]
(7)
\boldsymbol{R} = \begin{bmatrix} \cos \theta_x & \sin \theta_x & 0 \\ -\sin \theta_x & \cos \theta_x & 0 \\ 0 & 0 & 1 \end{bmatrix} \begin{bmatrix} \cos \theta_y & 0 & \sin \theta_y \\ 0 & 1 & 0 \\ -\sin \theta_y & 0 & \cos \theta_y \end{bmatrix} \begin{bmatrix} 1 & 0 & 0 \\ 0 & \cos \theta_z & \sin \theta_z \\ 0 & -\sin \theta_z & \cos \theta_z \end{bmatrix} \tag{7}
R=
cosθx−sinθx0sinθxcosθx0001
cosθy0−sinθy010sinθy0cosθy
1000cosθz−sinθz0sinθzcosθz
(7)
3.4.1.4 渲染图像结果
图3展示了点云旋转和渲染的细节。通过生成旋转矩阵
{
R
1
,
R
2
,
⋯
,
R
N
V
}
\{ \boldsymbol{R}_1, \boldsymbol{R}_2, \cdots, \boldsymbol{R}_{N_V} \}
{R1,R2,⋯,RNV} ,可得到一系列渲染图像
{
I
1
,
I
2
,
⋯
,
I
N
V
}
\{ I_1, I_2, \cdots, I_{N_V} \}
{I1,I2,⋯,INV}及其对应的二维位置
{
P
2
D
,
1
,
P
2
D
,
2
,
⋯
,
P
2
D
,
N
V
}
\{ P_{2D,1}, P_{2D,2}, \cdots, P_{2D,N_V} \}
{P2D,1,P2D,2,⋯,P2D,NV} ,使用(4),(5),(6)获得。
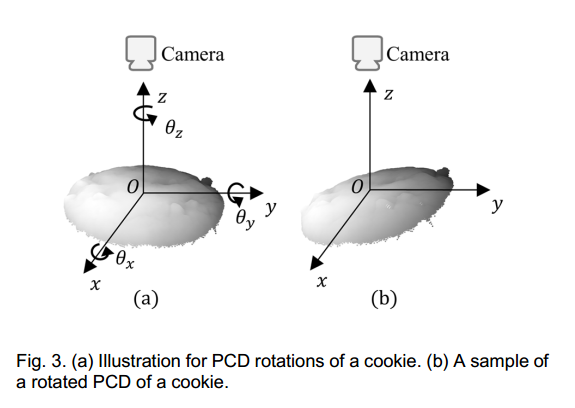
图4显示了渲染图像的一些示例.。

3.4.2 Pre-trained Feature Map Extraction 预训练特征图提取
通过多视图渲染,获取了来自多个视图的图像。然后,本研究将这些图像输入到预训练的二维神经网络中,以提取图像特征图。将图像特征提取函数记为
F
I
\mathcal{F}_{I}
FI,则第
k
k
k张图像
I
k
I_{k}
Ik的图像特征图
F
I
k
\boldsymbol{F}_{I_k}
FIk通过以下方式提取并上采样到原始分辨率:
F
I
k
=
F
I
(
I
k
)
(8)
\boldsymbol{F}_{I_k} = \mathcal{F}_{I}(I_{k}) \tag{8}
FIk=FI(Ik)(8)
其中
F
I
k
∈
R
H
×
W
×
D
2
D
\boldsymbol{F}_{I_k} \in \mathbb{R}^{H \times W \times D_{2D}}
FIk∈RH×W×D2D 。
3.4.3 2D to 3D Alignment and Aggregation 二维到三维对齐和聚合
图像特征图具有高度区分性,因为预训练的二维神经网络包含来自大规模图像数据集的丰富信息。本研究根据
P
2
D
,
k
P_{2D,k}
P2D,k ,通过二维到三维的对齐,从第
k
k
k个视图
F
2
D
,
k
∈
R
N
×
D
2
D
\boldsymbol{F}_{2D,k} \in \mathbb{R}^{N \times D_{2D}}
F2D,k∈RN×D2D 进一步获取逐点二维模态特征。
F
2
D
,
k
,
i
=
F
I
k
(
P
2
D
,
k
,
i
)
(9)
\boldsymbol{F}_{2D,k,i} = \boldsymbol{F}_{I_k}(P_{2D,k,i}) \tag{9}
F2D,k,i=FIk(P2D,k,i)(9)
其中
F
2
D
,
k
,
i
\boldsymbol{F}_{2D,k,i}
F2D,k,i是第
k
k
k个视图中第
i
i
i个点的二维模态特征 ,
F
I
k
(
P
2
D
,
k
,
i
)
\boldsymbol{F}_{I_k}(P_{2D,k,i})
FIk(P2D,k,i)是指
F
I
k
\boldsymbol{F}_{I_k}
FIk中像素位置
P
2
D
,
k
,
i
P_{2D,k,i}
P2D,k,i处的特征。
然后,以逐点的方式聚合来自不同视图的逐点特征
{
F
2
D
,
k
,
k
∈
[
1
,
N
V
]
}
\{ \boldsymbol{F}_{2D,k}, k \in [1, N_V] \}
{F2D,k,k∈[1,NV]} 。在本研究中,使用平均池化进行聚合:
F
2
D
=
1
N
V
∑
k
=
1
N
V
F
2
D
,
k
(10)
\boldsymbol{F}_{2D} = \frac{1}{N_V} \sum_{k = 1}^{N_V} \boldsymbol{F}_{2D,k} \tag{10}
F2D=NV1k=1∑NVF2D,k(10)
其中
F
2
D
\boldsymbol{F}_{2D}
F2D是聚合后的逐点二维模态特征,融合了来自多个视图的信息。整个二维模态点云特征提取过程如算法1所示。

3.5 Aggregation 聚合
对于给定的点云
P
3
D
P_{3D}
P3D,前文已阐述三维和二维模态特征的提取过程。为使二者相互补充并进一步提升特征能力,本研究对
F
2
D
\boldsymbol{F}_{2D}
F2D和
F
3
D
\boldsymbol{F}_{3D}
F3D进行归一化处理并整合,得到
F
C
P
M
F
∈
R
N
×
(
D
2
D
+
D
3
D
)
\boldsymbol{F}_{CPMF} \in \mathbb{R}^{N \times (D_{2D} + D_{3D})}
FCPMF∈RN×(D2D+D3D) 。具体来说,本研究首先将
F
2
D
\boldsymbol{F}_{2D}
F2D和
F
3
D
\boldsymbol{F}_{3D}
F3D归一化为单位向量,以确保三维和二维模态特征具有相同的量级,并在后续异常检测中发挥相似的作用,可表示为:
F
^
2
D
,
i
=
F
2
D
,
i
∥
F
2
D
,
i
∥
2
,
F
^
3
D
,
i
=
F
3
D
,
i
∥
F
3
D
,
i
∥
2
(11)
\hat{\boldsymbol{F}}_{2D,i} = \frac{\boldsymbol{F}_{2D,i}}{\| \boldsymbol{F}_{2D,i} \|_2}, \hat{\boldsymbol{F}}_{3D,i} = \frac{\boldsymbol{F}_{3D,i}}{\| \boldsymbol{F}_{3D,i} \|_2} \tag{11}
F^2D,i=∥F2D,i∥2F2D,i,F^3D,i=∥F3D,i∥2F3D,i(11)
其中
F
^
2
D
,
i
\hat{\boldsymbol{F}}_{2D,i}
F^2D,i和
F
^
3
D
,
i
\hat{\boldsymbol{F}}_{3D,i}
F^3D,i是第
i
i
i个点的归一化特征。
然后,整合
F
^
2
D
\hat{\boldsymbol{F}}_{2D}
F^2D和
F
^
3
D
\hat{\boldsymbol{F}}_{3D}
F^3D得到
F
C
P
M
F
\boldsymbol{F}_{CPMF}
FCPMF,如下所示:
F
C
P
M
F
=
C
(
F
^
2
D
,
F
^
3
D
)
(12)
\boldsymbol{F}_{CPMF} = \mathcal{C}(\hat{\boldsymbol{F}}_{2D}, \hat{\boldsymbol{F}}_{3D}) \tag{12}
FCPMF=C(F^2D,F^3D)(12)
其中
C
(
⋅
,
⋅
)
\mathcal{C}(\cdot, \cdot)
C(⋅,⋅)表示整合函数。
综上,将提取CPMF特征的函数记为
F
C
P
M
F
\mathcal{F}_{CPMF}
FCPMF,
F
C
P
M
F
\boldsymbol{F}_{CPMF}
FCPMF的提取过程可简化为:
F
C
P
M
F
=
F
C
P
M
F
(
P
3
D
)
(13)
\boldsymbol{F}_{CPMF} = \mathcal{F}_{CPMF}(P_{3D}) \tag{13}
FCPMF=FCPMF(P3D)(13)
并利用
F
C
P
M
F
\boldsymbol{F}_{CPMF}
FCPMF进行异常检测。
3.6 PCD Anomaly Detection 点云异常检测
3.6.1 训练阶段
本研究沿用PatchCore[23]进行异常检测。在训练阶段,使用所有
P
3
D
∈
P
t
r
a
i
n
P_{3D} \in \mathbb{P}_{train}
P3D∈Ptrain 构建内存库
M
\mathbb{M}
M :
M
=
⋃
P
3
D
∈
P
t
r
a
i
n
F
C
P
M
F
(
P
3
D
)
(14)
\mathbb{M} = \bigcup_{P_{3D} \in \mathbb{P}_{train}} \mathcal{F}_{CPMF}(P_{3D}) \tag{14}
M=P3D∈Ptrain⋃FCPMF(P3D)(14)
其中
M
\mathbb{M}
M包含训练点云数据集中所有点的CPMF特征。
3.6.2 测试阶段
在测试阶段,为推断测试点云
P
3
D
t
e
s
t
P_{3D}^{test}
P3Dtest的异常分数,本研究先提取
P
3
D
t
e
s
t
P_{3D}^{test}
P3Dtest的CPMF特征,然后通过最近邻搜索计算异常分数。异常分数计算过程可表示如下:
F
t
e
s
t
=
F
C
P
M
F
(
P
3
D
t
e
s
t
)
(15)
\boldsymbol{F}_{test} = \mathcal{F}_{CPMF}(P_{3D}^{test}) \tag{15}
Ftest=FCPMF(P3Dtest)(15)
S
i
=
min
f
∈
M
∥
F
t
e
s
t
,
i
−
f
∥
2
(16)
S_i = \min_{\boldsymbol{f} \in \mathbb{M}} \| \boldsymbol{F}_{test,i} - \boldsymbol{f} \|_2 \tag{16}
Si=f∈Mmin∥Ftest,i−f∥2(16)
其中
S
∈
R
N
S \in \mathbb{R}^N
S∈RN是
P
3
D
t
e
s
t
P_{3D}^{test}
P3Dtest的逐点异常分数,
S
i
S_i
Si是第
i
i
i个点的异常分数。对于给定的测试点云数据集
P
t
e
s
t
\mathbb{P}_{test}
Ptest,可通过(15)和(16)获取其对应的异常分数列表
S
S
S 。
CPMF及其相应异常检测过程的整体框架总结在算法2中。
4 EXPERIMENTS
本节展示了几组实验,这些实验用于评估互补伪多模态特征(CPMF)的性能,并展示其各个组成部分对异常检测的影响。
4.1 Experiment Settings 实验设置
4.1.1 Dataset 数据集
本研究在MVTec 3D数据集上进行实验[1],这是一个近期发布的真实世界多模态异常检测数据集,涵盖十种类别的二维RGB图像和三维点云扫描数据。该数据集包含可变形物体和刚性物体,部分物体存在自然变异(如桃子和胡萝卜)。虽然有些缺陷只能通过RGB信息检测到,但MVTec 3D数据集中的大多数缺陷是几何异常。本研究专注于研究点云异常检测,在后续实验中仅使用三维点云扫描数据。
4.1.2 Implementation Details 实施细则
4.1.2.1 数据预处理
对于MVTec3D数据集中的点云,本研究首先参照BTF [3] 方法去除无意义的背景。具体来说,本研究取图像边界周围十个像素宽的条带区域来近似平面。在去除点云数据(PCD)中所有的NaN值(即噪声)后,应用来自Open3D库 [41] 的RANSAC [39] 和DB - Scan [40] 算法进行平面近似,并用于过滤背景平面。
4.1.2.2 三维模态特征提取
默认情况下,本研究参照BTF [3] 方法,利用快速点特征直方图(FPFH)[7] 进行三维模态特征提取。为加快FPFH的计算速度,本研究在计算三维模态特征前对点云进行下采样。得到的三维模态特征维度 D 3 D D_{3D} D3D为33。
4.1.2.3 二维模态特征提取
本研究使用Open3D库[41]的相关功能,为给定的点云数据渲染多视图图像,渲染图像的空间分辨率固定为224×224 。默认情况下,在二维特征提取过程中,本研究使用在ImageNet[17]上预训练的ResNet18[42]的前三个模块,得到二维模态特征维度 D 2 D D_{2D} D2D为448 。在将所有图像输入预训练网络之前,使用ImageNet数据集的均值和方差对其进行归一化处理。对于多视图图像渲染,旋转矩阵主要由 θ x \theta_x θx、 θ y \theta_y θy、 θ z \theta_z θz确定,且 θ x \theta_x θx、 θ y \theta_y θy、 θ z \theta_z θz从预定义的小角度视图列表{ − π / 16 , 0 , π / 16 -\pi/16, 0, \pi/16 −π/16,0,π/16}中选取,以确保大多数点可见。本研究按顺序从视图列表中采样若干图像用于二维模态特征提取,默认数量为27。
4.1.3 Evaluation Metrics 评估指标
图像级异常检测性能通过利用生成的异常分数计算受试者工作特征曲线下面积(AU - ROC)来衡量。为简便起见,本研究中将图像级AU - ROC记为I - ROC。为衡量异常分割性能,本研究采用像素级PRO指标(记为P - PRO)[10] ,该指标考虑了连通异常分量的重叠情况。
与先前研究[2, 3]一致,本研究计算每类别的I - ROC和P - PRO值用于比较。
4.2 Comparisons with State-of-the-art Methods 与最先进方法的比较
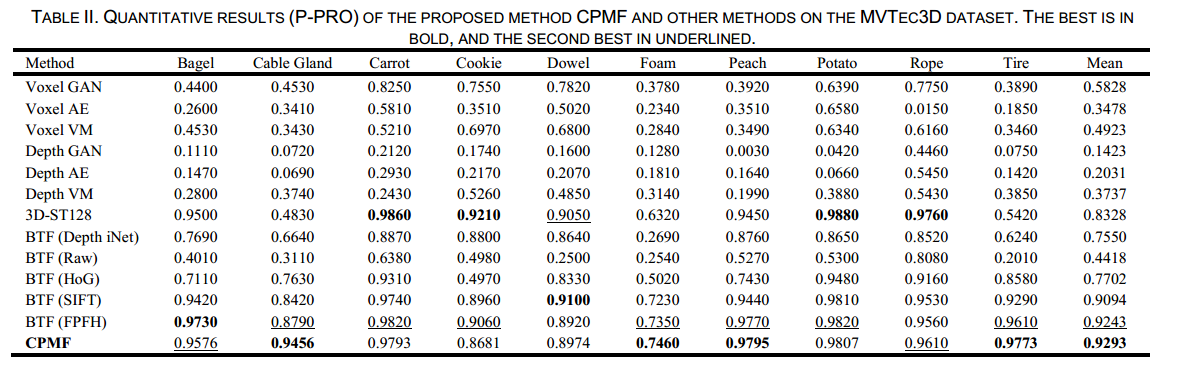
表1和表2总结了CPMF与其他先进方法的逐类别比较,这些方法包括基线方法[1]、AST [16]、3D - ST [43] ,以及BTF [3] 中报道的几种基准方法。
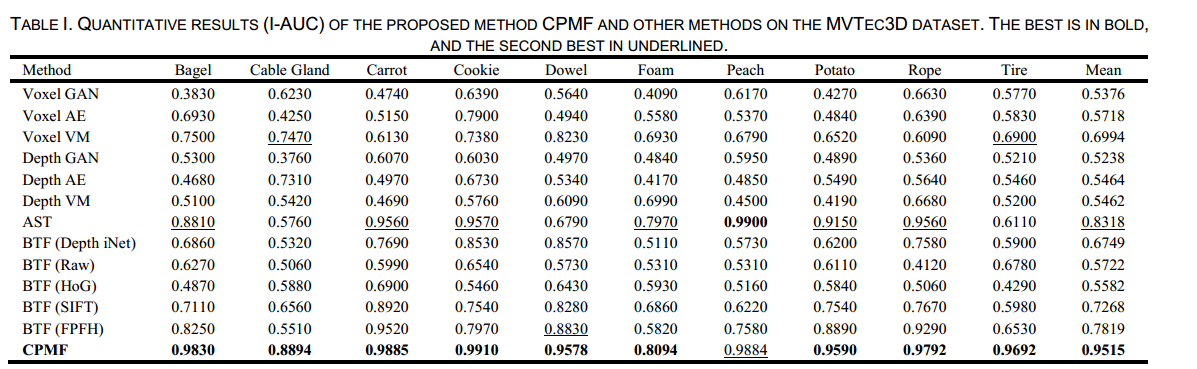
在图像级受试者工作特征曲线下面积(I - ROC)指标方面,AST [16] 在现有方法中取得了最佳平均性能,但其性能(I - ROC为83.18%)仍远不能令人满意。与现有方法相比,所提出的CPMF取得了显著更好的性能(I - ROC为95.15%) 。使用
F
C
P
M
F
F_{CPMF}
FCPMF的性能在十种类别中的八类达到了最高的I - ROC,在其余两类(即销钉和桃子)中达到第二高的I - ROC,有效地证明了CPMF的优越性。
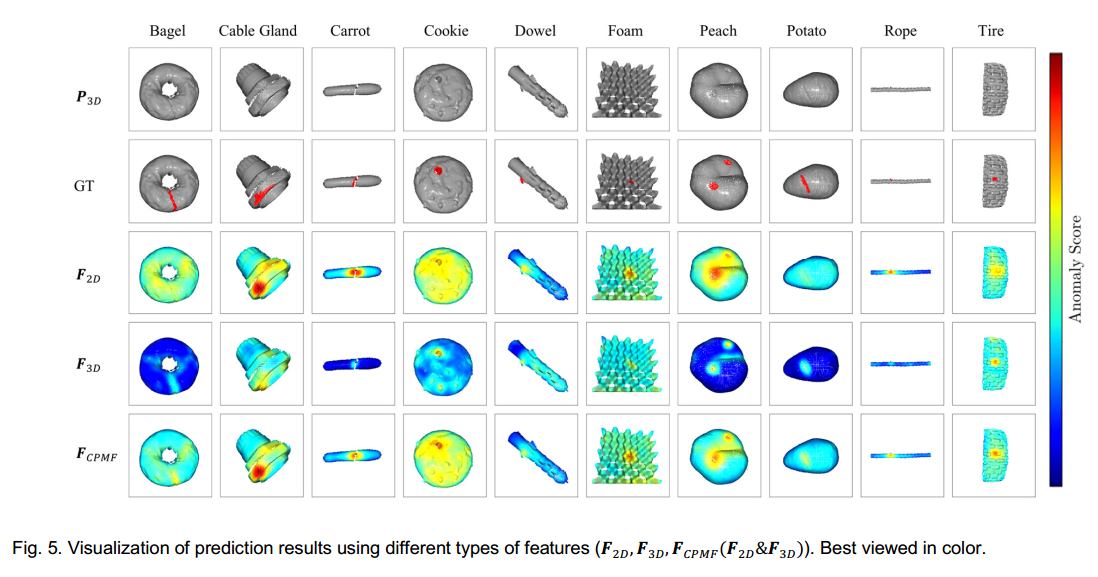
对于揭示点云异常定位性能的像素级PRO(P - PRO)指标,先前的研究BTF发现手工设计的描述子在异常定位方面表现出色,使用快速点特征直方图(FPFH)达到了92.43%的P - PRO值。CPMF取得了92.93%的P - PRO值,证明了CPMF在异常定位方面的优势。图5展示了使用CPMF进行定性异常检测的部分结果,清晰地显示了CPMF在定位几何异常方面的有效性。
4.3 Ablation Studies 消融实验
在本小节中,本文展示了互补伪多模态特征(CPMF)各个组成部分的影响,包括多视图图像渲染的视图数量的影响、二维和三维模态特征的贡献,以及骨干网络的影响。图6比较了具有不同视图数量、不同特征组合和不同骨干网络的CPMF的性能。值得注意的是,三维模态特征的性能不依赖于视图数量或骨干网络,而仅由所使用的三维手工设计描述子决定,因此在所有情况下其性能保持不变。
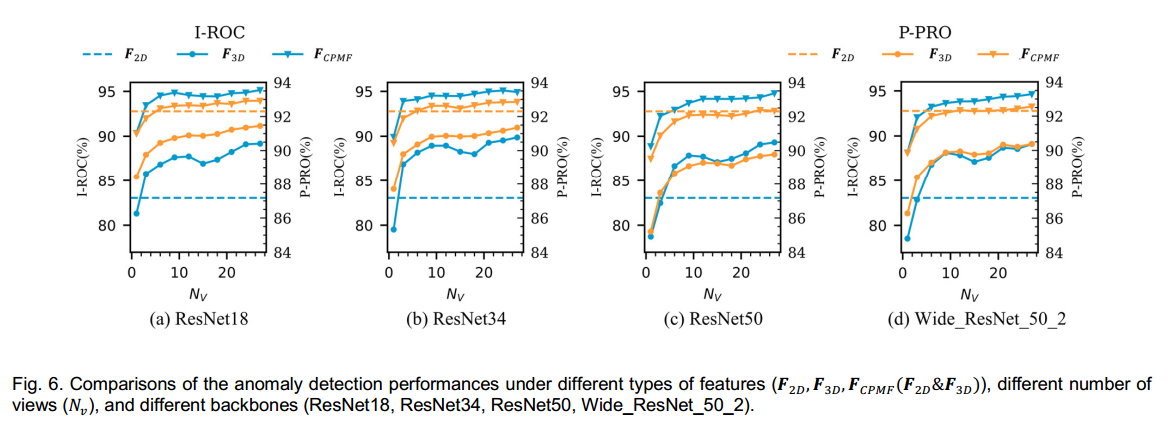
4.3.1 Influence of the number of rendering views 渲染视图数量的影响
通常,
N
V
N_V
NV(视图数量)越大意味着能更全面地捕捉信息。为研究
N
V
N_V
NV的影响,本研究使用不同的
N
V
N_V
NV值(
N
V
∈
{
1
,
3
,
6
,
⋯
,
27
}
N_V \in \{1, 3, 6, \cdots, 27\}
NV∈{1,3,6,⋯,27} )进行了多组实验。如图6所示,随着视图数量(
N
V
N_V
NV)增加,图像级受试者工作特征曲线下面积(I - ROC)和像素级PRO(P - PRO)指标适度提升,当
N
V
N_V
NV从1增加到3时提升最为显著,而当渲染视图数量在12到18左右时略有下降。
对于整体性能提升,原因很明确:更多视图的图像能更好地描述和捕捉给定点云数据(PCD)的潜在信息,从而实现更好的性能。与
N
V
=
1
N_V = 1
NV=1相比,
N
V
=
27
N_V = 27
NV=27带来了显著改进。例如,当使用ResNet34作为预训练二维神经网络的骨干网络时,仅使用二维模态特征
F
2
D
F_{2D}
F2D,I - ROC提升约10%,P - PRO提升约4%;使用
F
C
P
M
F
F_{CPMF}
FCPMF时,I - ROC提升5% ,P - PRO提升2% 。
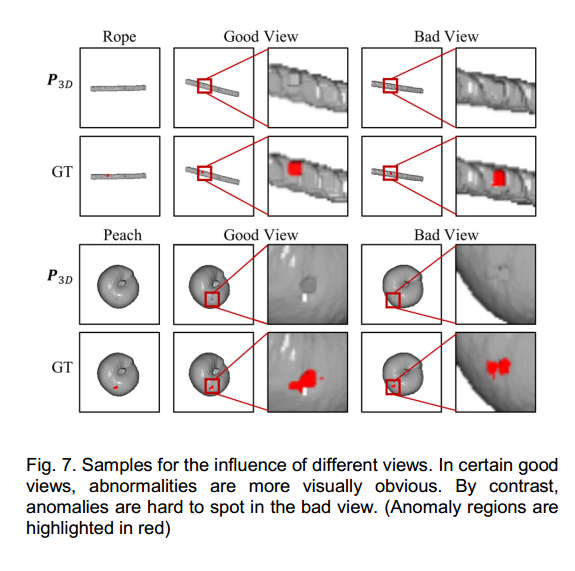
上述性能略有下降的主要原因可能是,某些特定视图的图像可能会产生低质量的特征,从而损害异常检测性能。正如许多研究[32, 34, 44]所示,自适应视图能更好地描述点云数据的结构,而固定视图可能导致性能欠佳。因此,为提高异常检测性能,可进一步研究为二维模态特征提取选择合适的视图。
图7展示了不同视图的图像示例。它有效地表明,异常区域在不同视图中的渲染视觉效果不同,并且由于某些视图中异常的明显成像,它们可能提供更好的特征描述能力。尽管更多视图能提升性能,但图7也表明,不同视图的图像对异常检测的贡献不同,可自适应选择视图以实现更有效的异常检测。
4.3.2 Influence of 2D and 3D modality features 二维和三维模态特征的影响
如前文所述,三维和二维特征提取模块以不同方式描述点云数据(PCD),
F
3
D
F_{3D}
F3D和
F
2
D
F_{2D}
F2D包含不同信息,其中
F
3
D
F_{3D}
F3D包含丰富的几何信息,
F
2
D
F_{2D}
F2D提取更多语义信息。图6比较了使用不同特征组合的异常检测性能。可以看出,在所有情况下,仅使用
F
3
D
F_{3D}
F3D能达到中等的平均图像级受试者工作特征曲线下面积(I - ROC,82.04%)和较高的平均像素级PRO(P - PRO,92.30%) ,而仅使用
F
2
D
F_{2D}
F2D时,随着视图数量
N
V
N_V
NV增加,各项指标显著提升。
具体而言,在I - ROC方面,当
N
V
=
1
N_V = 1
NV=1时,仅使用
F
2
D
F_{2D}
F2D的性能低于仅使用
F
3
D
F_{3D}
F3D ,但它们组合成的
F
C
P
M
F
F_{CPMF}
FCPMF性能明显优于单一类型的特征。随着
N
V
N_V
NV增加,仅使用
F
2
D
F_{2D}
F2D的性能逐渐提升并超过
F
3
D
F_{3D}
F3D ,这表明多视图图像能更好地描述点云数据中的几何信息。此外,
F
C
P
M
F
F_{CPMF}
FCPMF的性能始终大幅优于单一类型的特征(例如,使用ResNet18时提升约6% ),这再次证明了
F
2
D
F_{2D}
F2D和
F
3
D
F_{3D}
F3D之间的互补性。
在P - PRO指标方面,几乎在所有情况下,仅使用
F
2
D
F_{2D}
F2D的性能都比仅使用
F
3
D
F_{3D}
F3D差,即使使用所有视图,性能仍略有下降。原因可能是
F
2
D
F_{2D}
F2D的感受野比
F
3
D
F_{3D}
F3D大,导致其几何逐点特征较弱。
F
C
P
M
F
F_{CPMF}
FCPMF略优于单一类型特征,例如使用ResNet18时约高出0.6% 。总之,
F
3
D
F_{3D}
F3D在像素级表现优于
F
2
D
F_{2D}
F2D ,但在图像级表现较差,这证明提取的三维模态特征具有更强的几何信息和较弱的语义信息,而二维模态特征则相反。它们的组合兼具局部几何信息和全局语义信息,在图像级和像素级都有更好的性能。
图5清晰地表明
F
2
D
F_{2D}
F2D和
F
3
D
F_{3D}
F3D在检测点云异常方面有不同偏好。例如,在所选样本中,仅使用
F
2
D
F_{2D}
F2D能很好地定位电缆接头、胡萝卜、销钉等类别的异常,但在百吉饼和土豆等类别中表现不佳,而这些类别的异常用
F
3
D
F_{3D}
F3D能很好地定位。相比之下,
F
2
D
F_{2D}
F2D和
F
3
D
F_{3D}
F3D的组合,即完整的
F
C
P
M
F
F_{CPMF}
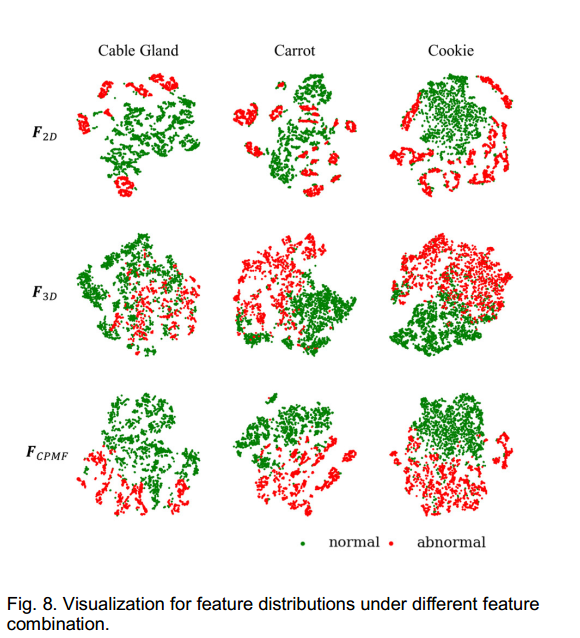
FCPMF ,显著提高了异常检测性能,在所有类别中都能出色地定位异常,如图5所示。图8可视化了
F
2
D
F_{2D}
F2D、
F
3
D
F_{3D}
F3D和
F
C
P
M
F
F_{CPMF}
FCPMF的几种特征分布,表明单一类型特征可能难以很好地区分,而
F
C
P
M
F
F_{CPMF}
FCPMF的分布更具可区分性。
4.3.3 Influence of backbones 骨干网络的影响
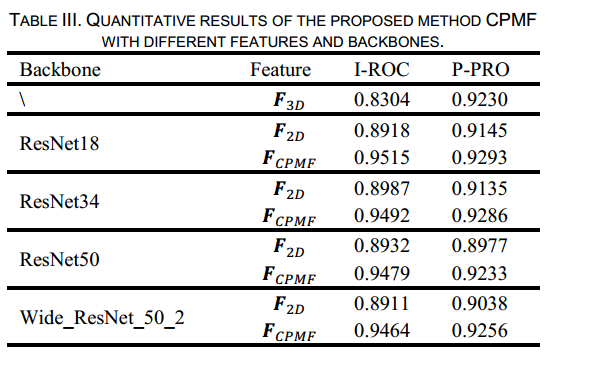
图6比较了CPMF在不同骨干网络下的性能,这些骨干网络包括ResNet18、ResNet34、ResNet50和Wide_ResNet_50_2 [45] ,表3总结了不同骨干网络下的最佳性能。对于各种类型的骨干网络,仅使用
F
2
D
F_{2D}
F2D在像素级的性能比仅使用
F
3
D
F_{3D}
F3D差,但在图像级的性能更好,而二者组合提升了图像级和像素级的性能。此外,骨干网络的类型对整体性能没有很大影响,CPMF在ResNet18下取得最佳性能(I - ROC为95.15% ,P - PRO为92.93%)。
4.3.4 Limitation analysis 局限性分析
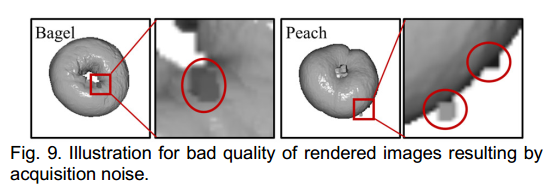
本小节分析了几个局限性。首先,如图9所示,由于点云数据采集过程中引入的噪声,渲染图像的质量可能较差。图像质量不佳可能进一步影响特征提取能力,导致误判。其次,当前的像素级指标P - PRO能反映检测各类异常的性能,但有些异常只能通过RGB信息检测到。这种现象导致CPMF虽取得了优异但未达极致的性能,因此需要一个更合理的指标来评估点云逐点异常定位性能。
5 CONCLUSION
本文探讨了一项前景广阔且颇具挑战性的任务,即点云(PCD)异常检测,并提出了一种名为互补伪多模态特征(CPMF)的新型点云表示方法,以实现更优的异常检测性能。CPMF融合了精心设计的手工制作点云描述符,以及来自近期开发的预训练二维神经网络的描述性特征,用于全面描述点云数据。具体而言,手工制作的点云描述符直接用于提取三维模态中的局部几何信息。为充分利用预训练二维神经网络的优势,CPMF开发了一个二维模态特征提取模块。该模块通过三维到二维的投影和渲染,将点云数据渲染为多视图图像,然后利用预训练的二维神经网络提取图像特征图,再对其进行对齐和聚合,以获取最终的二维模态特征,从而包含丰富的全局语义信息。CPMF特征融合了三维和二维模态特征,同时利用局部几何线索和全局语义线索,提供了更强的描述能力。全面的实验表明,所提出的CPMF性能大幅优于先前的方法,证明了二维和三维模态特征之间的互补能力。
尽管CPMF取得了领先的性能,但仍有几个值得探索的未来研究方向。例如,开发端到端的CPMF可以提高效率并减少内存消耗。此外,自适应视图选择和聚合有望进一步提升异常检测性能。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









