







一、视频异常检测
1.1 Multi-Scale Video Anomaly Detection by Multi-Grained Spatio-Temporal Representation Learning
基于多粒度时空表征学习的多尺度视频异常检测
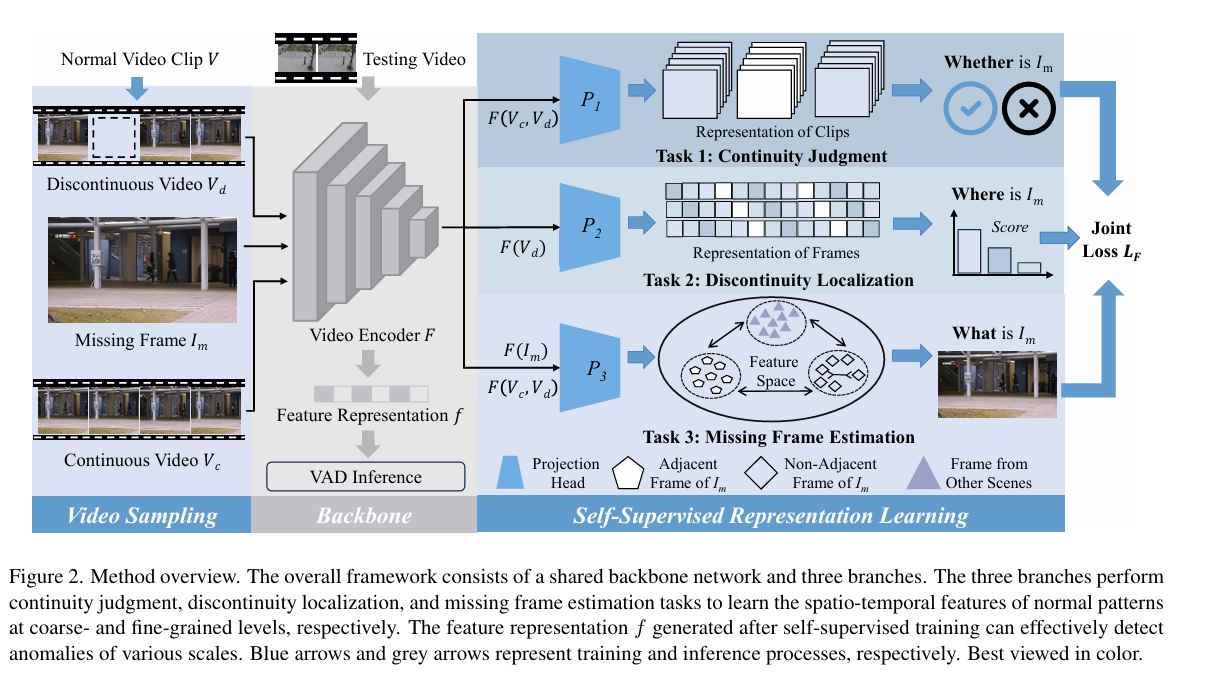
摘要:视频异常检测领域的最新进展表明,外观和运动特征在区分异常模式与正常模式方面起着关键作用。然而,我们注意到异常的空间尺度效应被忽视了。许多异常事件发生在有限的局部区域,且严重的背景噪声干扰了对异常变化的学习。同时,大多数现有方法受限于粗粒度的建模方式,不足以学习到具有高度区分性的特征,难以辨别小尺度异常与正常模式之间的细微差异。 为此,本文通过多粒度时空表征学习来解决多尺度视频异常检测问题。我们利用视频的连续性设计了三个代理任务,以在粗粒度和细粒度层面进行特征学习,即连续性判断、不连续性定位和缺失帧估计。特别地,我们将缺失帧估计表述为特征空间中的对比学习任务,而非RGB空间中的重建任务,以此来学习具有高度区分性的特征。实验表明,我们提出的方法在四个数据集上优于现有先进方法,尤其是在存在小尺度异常的场景中。
1.2 Text Prompt with Normality Guidance for Weakly Supervised Video Anomaly Detection
正常性引导文本提示的弱监督视频异常检测
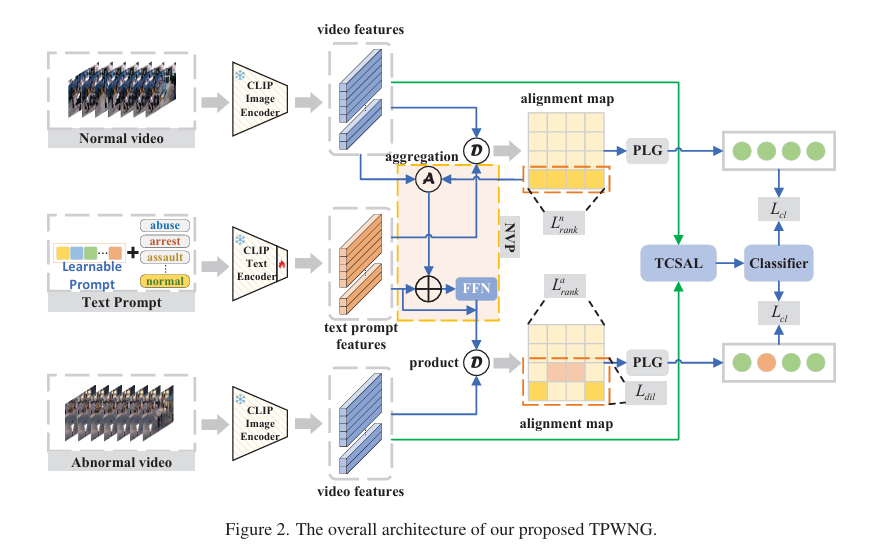
摘要:弱监督视频异常检测(WSVAD)是一项具有挑战性的任务。基于弱标签生成细粒度伪标签,然后对分类器进行自训练,是目前颇具前景的解决方案。然而,现有方法仅使用RGB视觉模态,且忽略了类别文本信息的利用,这限制了更准确伪标签的生成,进而影响了自训练的性能。受基于事件描述的人工标注过程启发,本文提出一种用于弱监督视频异常检测的全新伪标签生成与自训练框架,即基于正常性引导文本提示(TPWNG)的方法。我们的思路是迁移对比语言 - 图像预训练(CLIP)模型丰富的语言 - 视觉知识,使视频事件描述文本与相应视频帧对齐,以生成伪标签。具体而言,我们首先对CLIP模型进行微调以适应领域需求,设计了两种排序损失和一种分布不一致损失 。此外,我们提出一种可学习文本提示机制,并借助正常性视觉提示,进一步提高视频事件描述文本与视频帧的匹配准确率。然后,我们设计了一个基于正常性引导的伪标签生成模块,以推断可靠的帧级伪标签。最后,我们引入时间上下文自适应学习模块,以更灵活、准确地学习不同视频事件的时间相关性。大量实验表明,我们的方法在UCF - Crime和XD - Violence这两个基准数据集上取得了领先的性能,证明了所提方法的有效性。
1.3 Self-Distilled Masked Auto-Encoders are Efficient Video Anomaly Detectors
自蒸馏掩码自动编码器用于高效视频异常检测
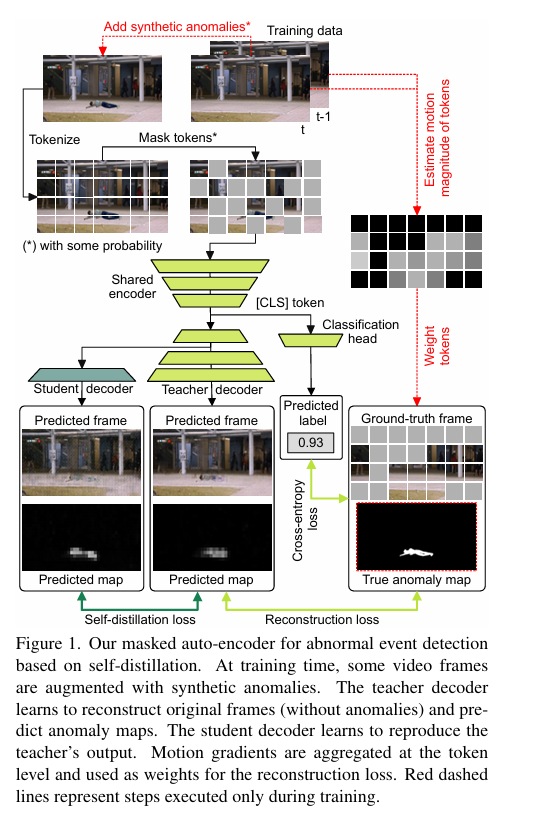
摘要:我们提出一种基于轻量级掩码自动编码器(AE)的高效异常事件检测模型,该模型应用于视频帧层面。所提模型的新颖之处体现在三个方面。首先,我们引入一种基于运动梯度对标记进行加权的方法,从而将关注点从静态背景场景转移到前景对象上。其次,我们在架构中集成了教师解码器和学生解码器,利用这两个解码器输出之间的差异来改进异常检测。第三,我们生成合成异常事件以扩充训练视频,并让掩码自动编码器模型联合重建原始帧(无异常)以及对应的像素级异常图。我们的设计造就了高效且有效的模型,在Avenue、ShanghaiTech、UBNormal和UCSD Ped2这四个基准数据集上进行的大量实验证明了这一点。实证结果表明,我们的模型在速度和准确性之间实现了出色的平衡,在处理速度达到1655 FPS的同时,获得了具有竞争力的AUC分数。因此,我们的模型比同类方法快8到70倍。我们还进行了消融研究以验证设计的合理性。代码可在https://github.com/ristea/aed-mae免费获取。
1.4 Open-Vocabulary Video Anomaly Detection
开放词汇视频异常检测
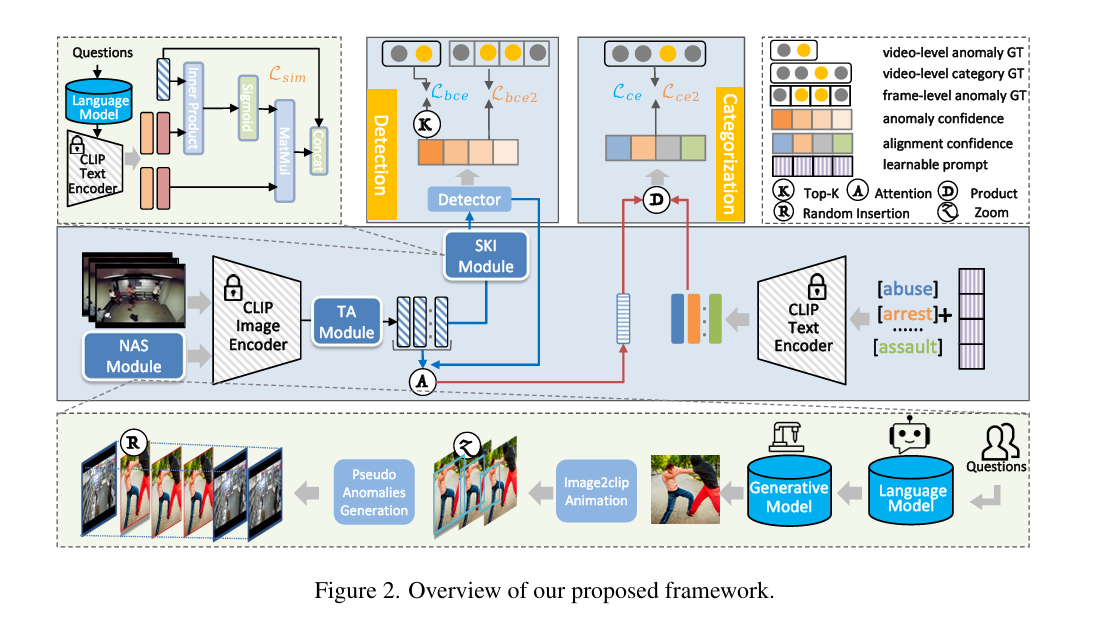
摘要:当前的弱监督视频异常检测(VAD)方法本质上局限于封闭集设置,在测试数据中可能存在训练时未见过的异常类别时,表现会大打折扣。少数近期的视频异常检测研究尝试解决更现实的开放集VAD问题,即在给定已见异常和正常视频的情况下,检测未见异常。然而,此类方法侧重于预测异常分数,却无法识别异常的具体类别,尽管这一能力对于构建更完备的视频监控系统至关重要。 本文更进一步,探索开放词汇视频异常检测(OWVAD),旨在借助预训练大模型来检测和分类已见及未见异常。为此,我们提出了一个模型——OVAD,将其分解为两个互补的任务:类别不可知异常检测和类别特定分类,并对这两个任务进行联合优化。特别地,我们设计了语义知识注入模块,用于引入来自大型语言模型的语义知识以辅助检测任务,还设计了一种新颖的异常合成模块,借助大型视觉生成模型生成伪未见异常,用于分类任务。这些语义知识和异常合成显著拓展了我们模型检测和分类各种已见及未见异常的能力。在三个广泛使用的基准数据集上进行的大量实验表明,OVAD模型取得了领先的性能。
1.5 Collaborative Learning of Anomalies with Privacy (CLAP) for Unsupervised Video Anomaly Detection: A New Baseline
无监督视频异常检测的隐私协作异常学习(CLAP):一种新基线
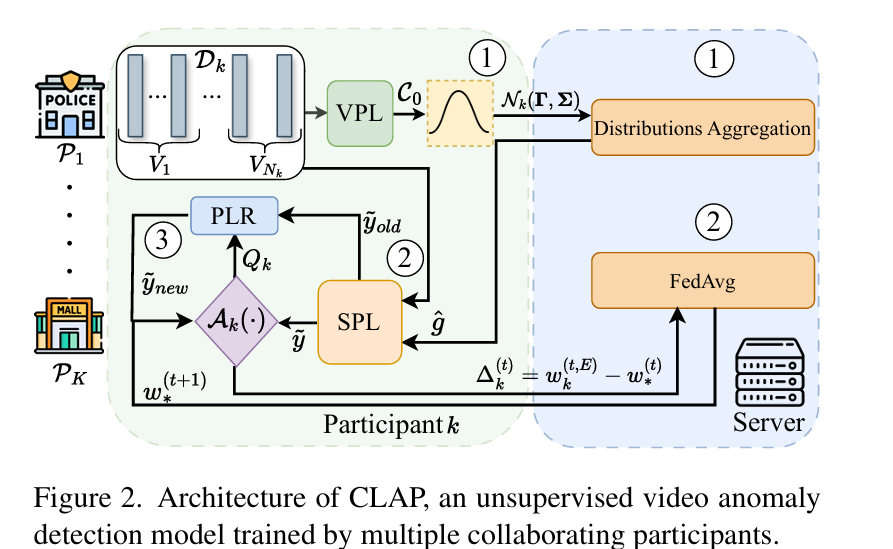
摘要:无监督(US)视频异常检测(VAD)在监控应用中因其实用的现实场景应用,近来愈发受到欢迎。由于监控视频涉及隐私敏感信息,且大规模视频数据的可获取性有助于构建更优的无监督视频异常检测系统,在这种情况下,协作学习可能会带来显著收益。然而,无监督视频异常检测任务极具挑战性,因其在无任何标注的情况下进行学习,目前尚未有关于无监督视频异常检测系统的隐私保护协作学习研究。 本文提出一种新的异常检测基线方法,该方法能够在完全无监督且无任何标签的情况下,在基于隐私保护参与者的分布式训练配置中,对复杂监控视频中的异常事件进行定位。此外,我们提出三种新的评估协议,用于在各种协作和数据可用场景下对异常检测方法进行基准测试。基于这些协议,我们对现有视频异常检测数据集进行修改,以在包括UCF - Crime和XD - Violence在内的两个大规模数据集上广泛评估我们的方法以及现有的无监督最优方法。所有提出的评估协议、数据集分割和代码均可在https://github.com/AnasEmad11/CLAP获取。
1.6 Harnessing Large Language Models for Training-free Video Anomaly Detection
利用大型语言模型实现免训练视频异常检测
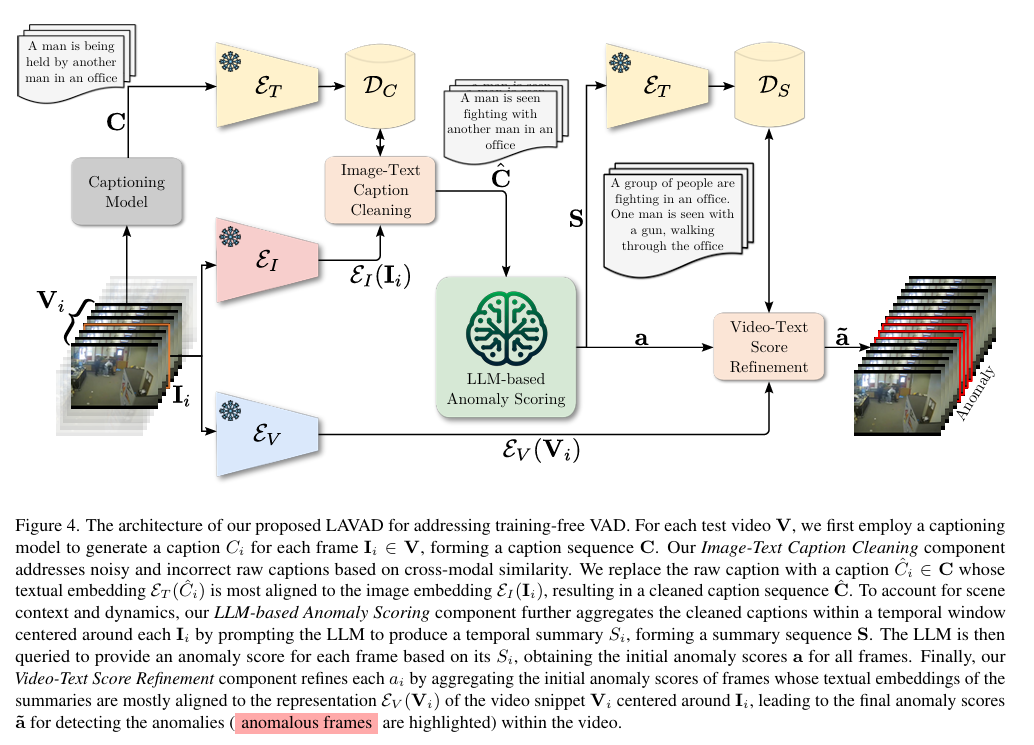
摘要:视频异常检测(VAD)旨在从时间维度定位视频中的异常事件。现有研究大多依赖深度模型来学习正常状态的分布,方式为使用逐帧级别的监督、单类监督或在无监督设置下进行。基于训练的方法容易出现领域特异性问题,这意味着将其实际部署到新领域时,因涉及数据收集和模型训练,成本会很高。 本文中,我们从根本上突破了以往的方法,提出一种名为基于语言的视频异常检测(LAVAD)的方法,以全新的无训练范式来解决VAD问题。LAVAD利用预训练大语言模型(LLMs)以及基于语言的视觉 - 语言模型(VLMs)的能力。我们利用LLMs和VLMs为任何测试视频的每一帧生成文本描述。有了技术场景描述后,我们使用提示机制解锁LLMs在时间聚合和异常分数估计方面的能力,从而将LLMs转化为有效的视频异常检测器。我们进一步利用模态对齐的VLMs来提出有效的文本提示,这些提示基于跨模态相似性,用于清除嘈杂的描述并优化基于大语言模型的异常分数。 我们在两个具有真实世界监控场景的大规模数据集(UCF - Crime和XD - Violence)上对LAVAD进行评估,结果表明,它优于所有无监督和单类监督方法,且无需进行任何训练或数据收集。
1.7 Prompt-Enhanced Multiple Instance Learning for Weakly Supervised Video Anomaly Detection
提示增强多实例学习的弱监督视频异常检测
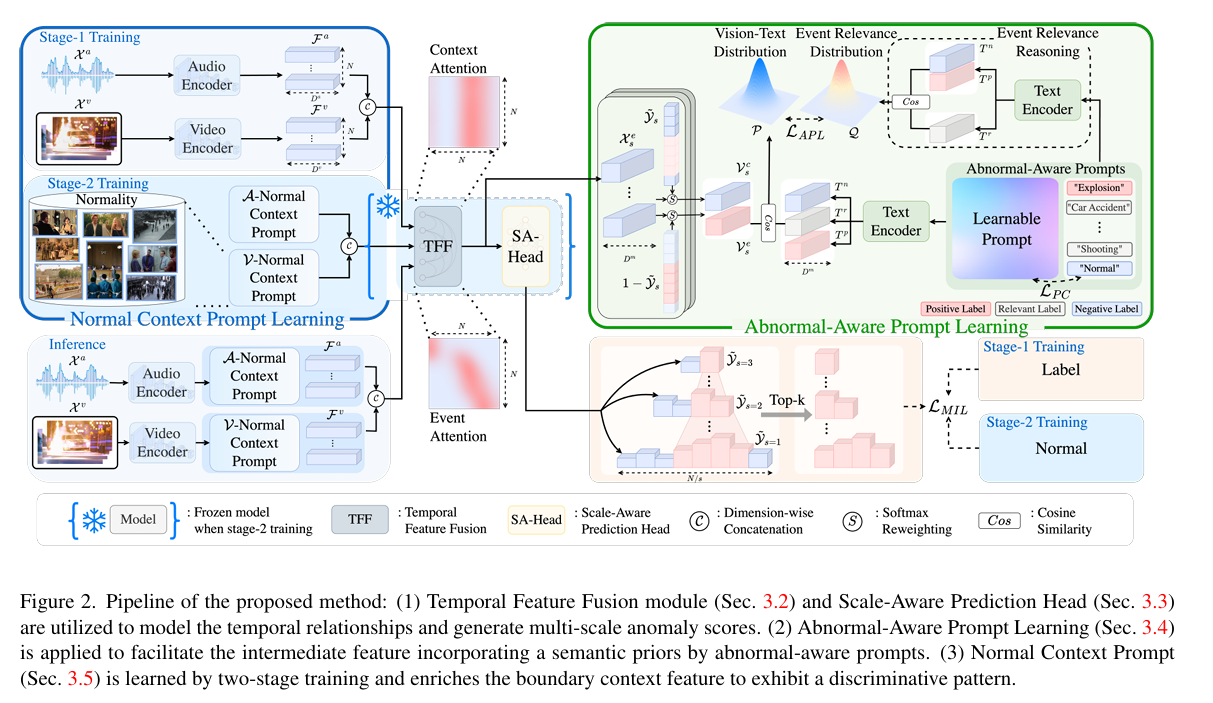
摘要:弱监督视频异常检测(wVAD)旨在仅使用视频级标签来检测帧级异常。由于wVAD中存在粗粒度标签的限制,多示例学习(MIL)在其中广泛应用。然而,MIL在将二元监督映射到各种异常模式方面存在不足。此外,异常与其上下文之间的耦合阻碍了对清晰异常事件边界的学习。 本文提出提示增强的多示例学习,用于检测各种异常事件,同时消除事件边界的模糊性。具体而言,我们通过组合类别注释来设计异常感知提示,并引入可学习提示,它可以将语义先验动态融入视频特征中。检测器能够利用语义丰富的特征来捕捉不同的异常模式。此外,引入正常上下文提示以放大异常与其上下文之间的区别,促进清晰边界的生成。通过异常提示和正常上下文提示的相互增强,模型可以在不表示事件边界的情况下构建不同异常的判别表示。大量实验表明,我们的方法在三个公共基准上取得了领先的性能。代码可在https://github.com/Junxi-Chen/PE-MIL获取。
1.8 Uncovering What Why and How: A Comprehensive Benchmark for Causation Understanding of Video Anomaly
揭示异常的“什么、为什么和如何”:视频异常因果理解的综合基准
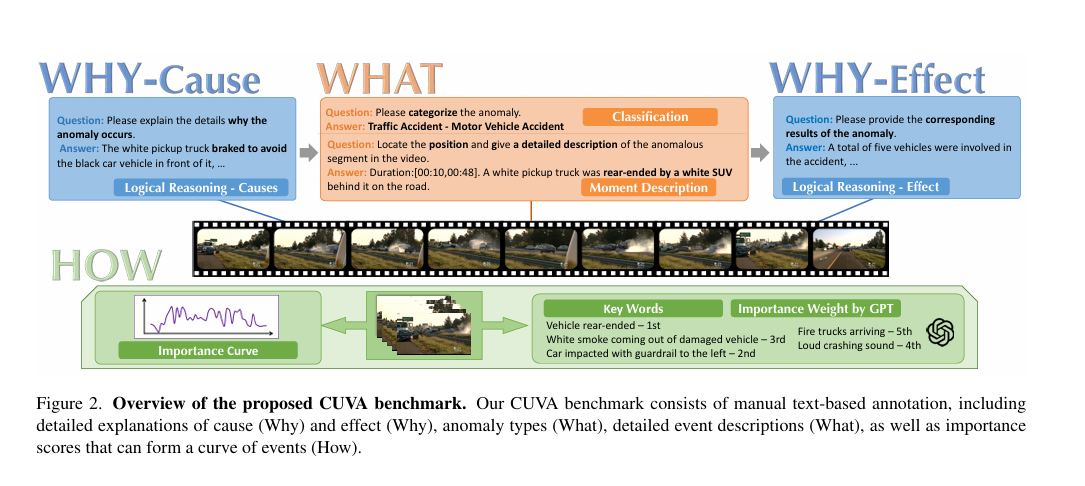
摘要:视频异常理解(VAU)旨在自动理解视频中的异常事件,从而支持交通监控和工业制造等多种应用。现有VAU基准主要聚焦于异常检测与定位,而我们更关注实际应用,由此引出关键问题:“发生了什么异常?” “为什么会发生?” “异常事件的严重程度如何?” 为探寻这些问题的答案,我们提出了视频异常因果理解综合基准(CUVA)。具体而言,该基准的每个实例包含三组人工标注,用以表明异常的“什么”“为什么”和“如何” ,包括1)异常类型、起止时间和事件描述;2)对异常成因的自然语言解释;3)反映异常影响的自由文本。 此外,我们还引入了MMEval,这是一种专为CUVA设计的全新评估指标,能更好地契合人类偏好,便于衡量现有大语言模型对视频异常成因及相应影响的理解程度。最后,我们提出一种基于提示的新方法,可作为应对CUVA挑战的基准方法。我们开展了大量实验,以证明评估指标和基于提示的方法的优越性。我们的代码和数据集可在https://github.com/fesvhtr/CUVA获取。
1.9 MULDE: Multiscale Log-Density Estimation via Denoising Score Matching for Video Anomaly Detection
通过去噪分数匹配实现多尺度对数密度估计的视频异常检测
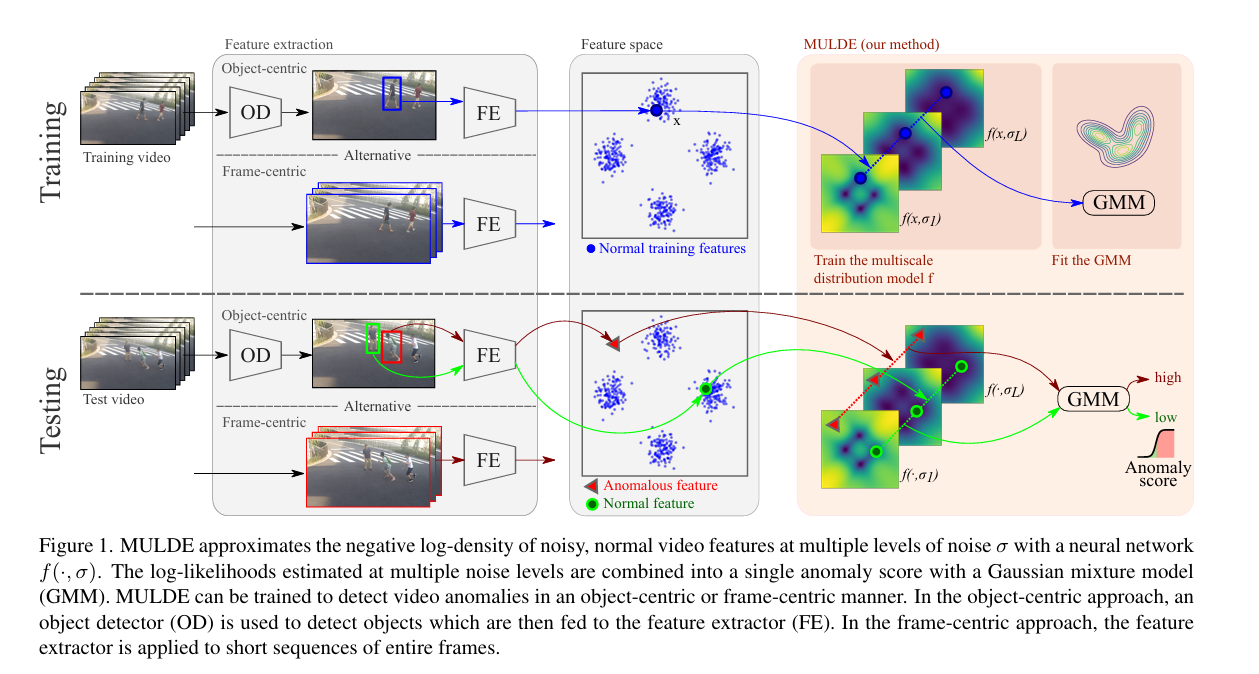
摘要:我们提出一种全新的视频异常检测方法:将从视频中提取的特征向量视为具有固定分布的随机变量的实现,并使用神经网络对该分布进行建模。这使我们能够估计测试视频的似然性,并通过对似然估计进行阈值处理来检测视频异常。我们通过修改噪声评分匹配(一种将训练数据与噪声相匹配的方法)来训练视频异常检测器。为消除超参数选择问题,我们对不同噪声水平下的噪声视频特征分布进行建模,并引入一个正则化器,用于对齐不同噪声水平下的模型。在测试时,我们将多个噪声尺度下的异常指示与高斯混合模型相结合。运行我们的视频异常检测器仅会产生极小的延迟,因为推理过程仅需提取浅层特征并传播到一个小型神经网络和高斯混合模型。我们在五个流行的视频异常检测基准上进行的实验表明,我们的方法在以物体为中心和以帧为中心的设置中均达到了领先的性能。
二、图像异常检测
2.1 Hyperbolic Anomaly Detection
双曲异常检测
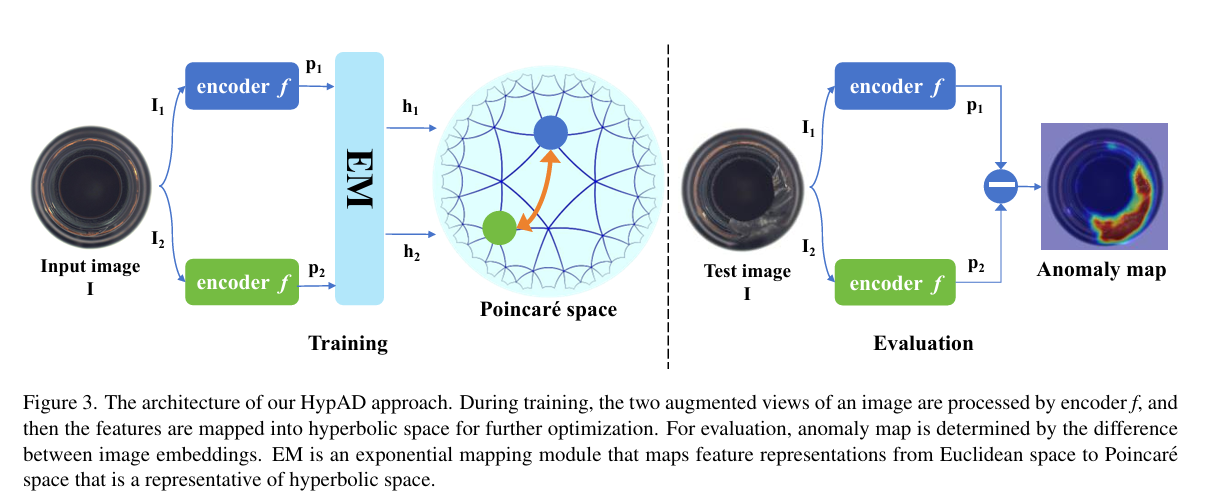
摘要:异常检测是工业场景中一项具有挑战性的计算机视觉任务。深度学习的不断进步持续革新着基于视觉的异常检测方法,在有监督和自监督异常检测方面均取得了显著进展。常用的流程是使用基于距离的损失函数约束特征嵌入来优化模型。然而,这些方法在欧几里得空间中起作用,无法很好地利用非欧几里得空间中的数据。在本文中,我们首次探索在作为非欧几里得空间代表的双曲空间中进行异常检测任务,并提出双曲异常检测(HypAD)方法。具体而言,我们首先提取图像特征,然后将其从欧几里得空间映射到双曲空间,在双曲空间中使用双曲距离度量来优化所提出的HypAD方法。在包括MVTec AD和VisA等基准数据集上进行的大量实验表明,我们的HypAD方法取得了领先的性能,证明了HypAD的有效性以及在双曲空间中研究异常检测的潜力。
2.2 Adapting Visual-Language Models for Generalizable Anomaly Detection in Medical Images
适配视觉-语言模型用于医学图像通用异常检测
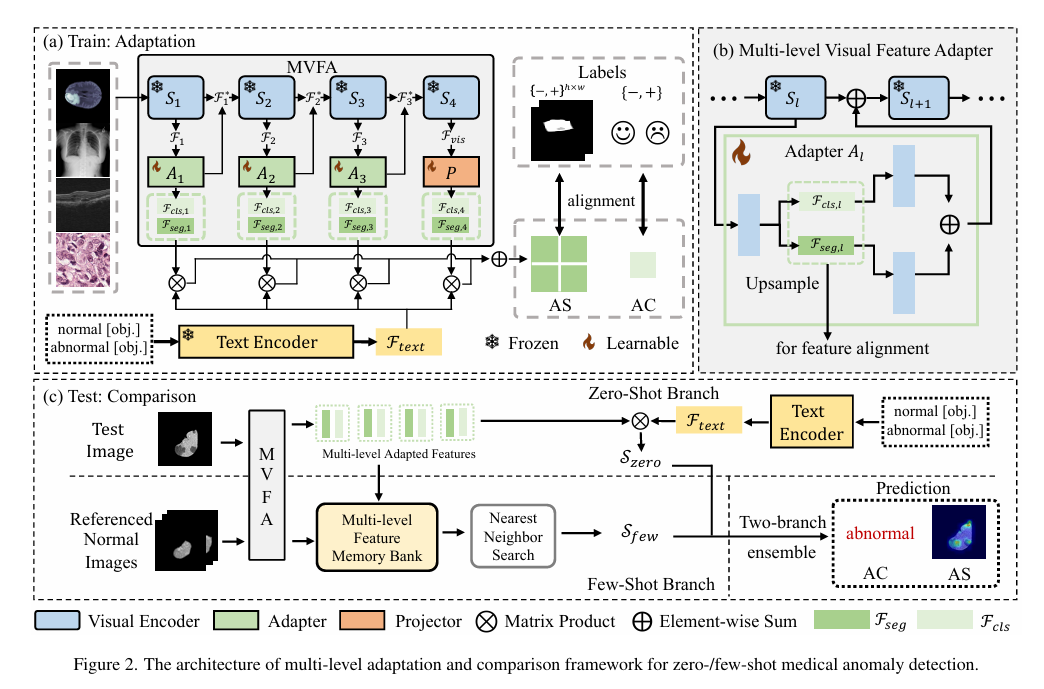
摘要:大规模视觉 - 语言预训练模型的最新进展,使得在自然图像领域的零样本/少样本异常检测取得了显著进步。然而,自然图像与医学图像之间存在的显著领域差异,限制了这些方法在医学异常检测中的有效性。本文引入一种全新的轻量级多层次适配与比较框架,旨在将CLIP模型应用于医学异常检测。我们的方法在预训练的视觉编码器中集成了多个残差适配器,能够在不同层次逐步增强视觉特征。这种多层次适配由多层次像素级视觉 - 语言特征对齐损失函数引导,将模型的关注点从自然图像中的物体语义,重新校准到医学图像中的异常识别上。经过适配的特征在不同医学数据类型间展现出更好的泛化性,即便在模型训练中未见过的医学模态和解剖区域的零样本场景下也表现良好。我们在医学异常检测基准上的实验表明,我们的方法显著优于当前的先进模型,在零样本和少样本设置下,异常分类的平均AUC分别提高了6.24%和7.33%,分割的平均AUC分别提高了2.03%和2.37% 。源代码可在https://github.com/MediaBrain-SJTU/MVFA-AD获取。
2.3 Supervised Anomaly Detection for Complex Industrial Images
复杂工业图像的有监督异常检测
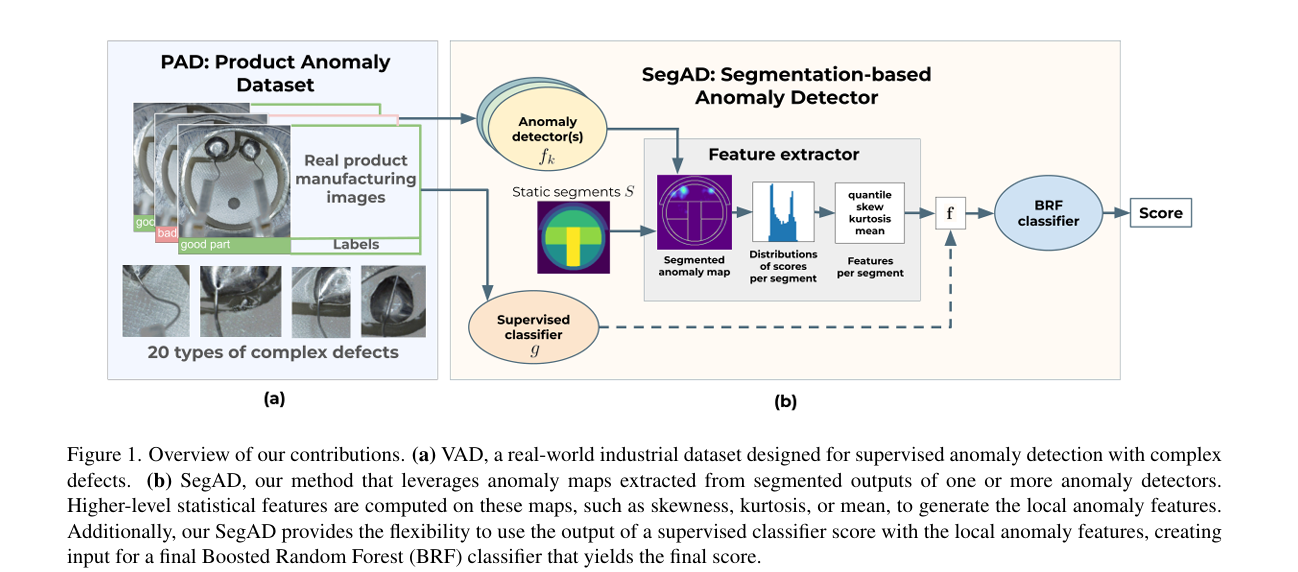
摘要:在工业生产线上实现视觉检测自动化,对于提升各行业产品质量至关重要。异常检测(AD)方法是实现这一目标的可靠工具。然而,现有的公开数据集主要由无异常的图像组成,这限制了异常检测方法在生产环境中的实际应用。为应对这一挑战,我们提出:(1)法雷奥异常数据集(VAD),这是一个全新的真实工业数据集,包含5000张图像,其中2000个实例为涵盖20多个子类的具有挑战性的真实缺陷。考虑到传统异常检测方法在该数据集上表现欠佳,我们引入(2)基于分割的异常检测器(SegAD)。首先,SegAD利用异常图和分割图来计算局部统计量。接着,SegAD将这些统计量以及可选的有监督分类器分数作为输入特征,输入到增强随机森林(BRF)分类器中,从而得出最终的异常分数。我们的SegAD在VAD数据集(AUROC提升2.1% )和VisA数据集(AUROC提升0.4% )上均取得了领先的性能。代码和模型已公开提供 。
2.4 Real-IAD: A Real-World Multi-View Dataset for Benchmarking Versatile Industrial Anomaly Detection
Real-IAD:用于通用工业异常检测基准的真实多视角数据集
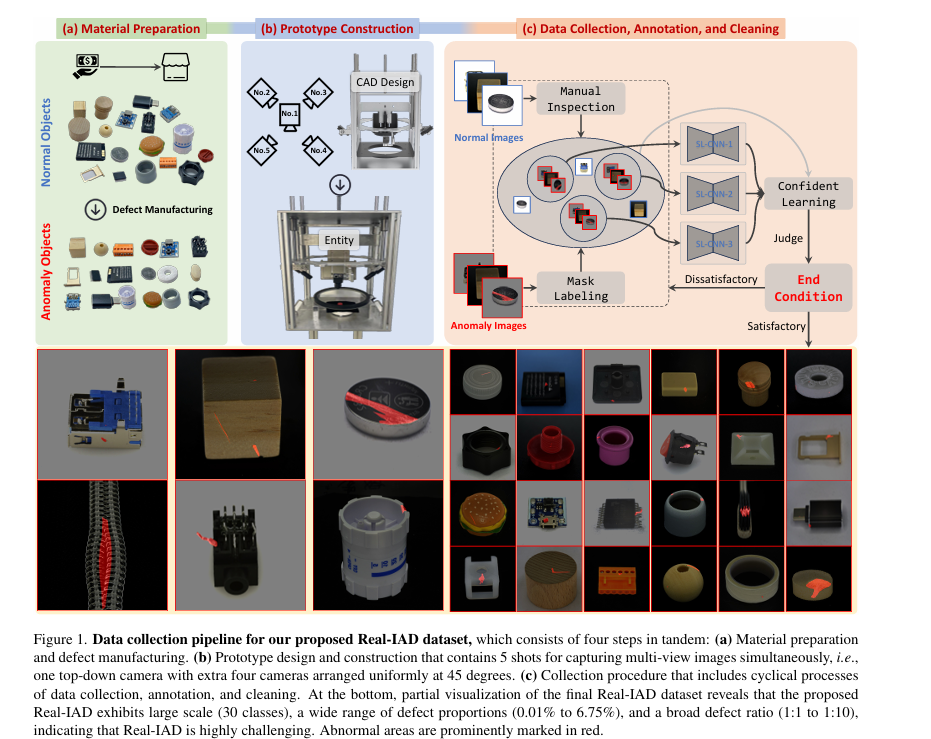
摘要:工业异常检测(IAD)已受到广泛关注并取得了快速发展。然而,由于数据集的限制,近期工业异常检测方法的发展遇到了一定困难。一方面,主流数据集中(如MVTec),大多数现有方法(超99% )的AUC已接近饱和,方法间差异难以区分,导致公开数据集与实际应用场景存在较大差距。另一方面,由于数据集规模限制,各种新型实际异常检测场景的研究受限,在评估中存在过拟合风险。 因此,我们发布了一个大规模、真实世界、多视角的工业异常检测数据集,名为Real - IAD,它包含30种不同物体的15万张高分辨率图像。其规模比现有数据集大得多,具有更大的缺陷面积和比例,比以往数据集更具挑战性。为使数据集更贴近实际应用场景,我们采用了多视角拍摄方法并提出样本级评估指标。此外,除了一般的无监督异常检测设置外,我们还提出了一种全新的全无监督工业异常检测(FUAD)设置,基于工业生产良品率通常超60%的实际情况,该设置具有更高的实际应用价值。 最后,我们报告了流行的工业异常检测方法在Real - IAD数据集上的结果,提出了该领域的重大挑战,以推动工业异常检测领域的发展。
2.5 PromptAD: Learning Prompts with only Normal Samples for Few-Shot Anomaly Detection
PromptAD:仅使用正常样本学习提示的小样本异常检测
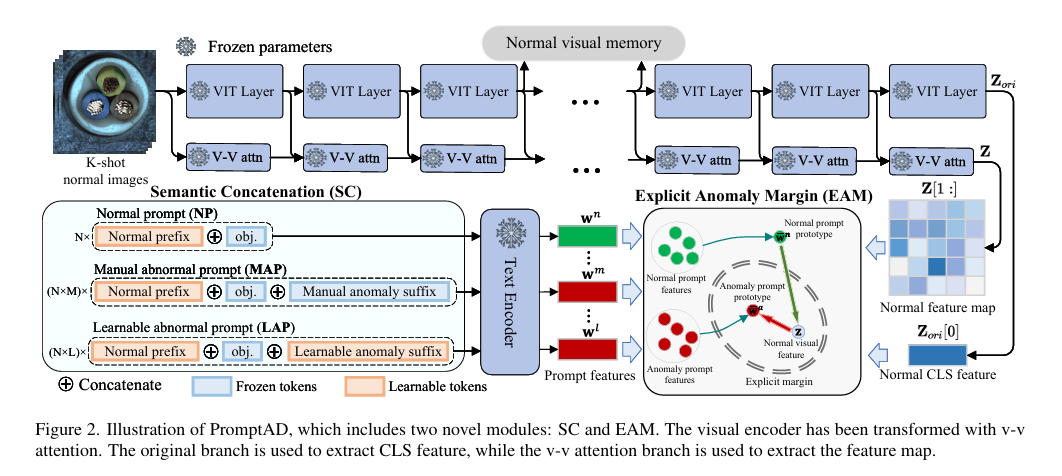
摘要:视觉 - 语言模型为小样本工业异常检测带来了显著提升,通常这需要通过提示工程设计数百个提示。对于自动化场景,我们首先采用基于多类别范式的传统提示学习作为基线来自动学习提示,但发现它在单类异常检测中效果不佳。 为解决上述问题,本文提出一种用于小样本异常检测的提示学习方法——PromptAD。首先,我们提出语义拼接方法,通过将正常提示与异常后缀拼接,把正常提示转换为异常提示,从而构建大量负样本,用于在单类设置中指导提示学习。此外,为缓解因缺乏异常图像导致的训练难题,我们引入显式异常裕度的概念,通过一个超参数来明确控制正常提示特征与异常提示特征之间的裕度。在图像级/像素级异常检测方面,PromptAD在MVTec和VisA数据集的11/12种小样本设置中均排名第一。代码可在https://github.com/FuNz-0/PromptAD获取。
2.6 Anomaly Heterogeneity Learning for Open-set Supervised Anomaly Detection
开放集有监督异常检测的异常异质性学习
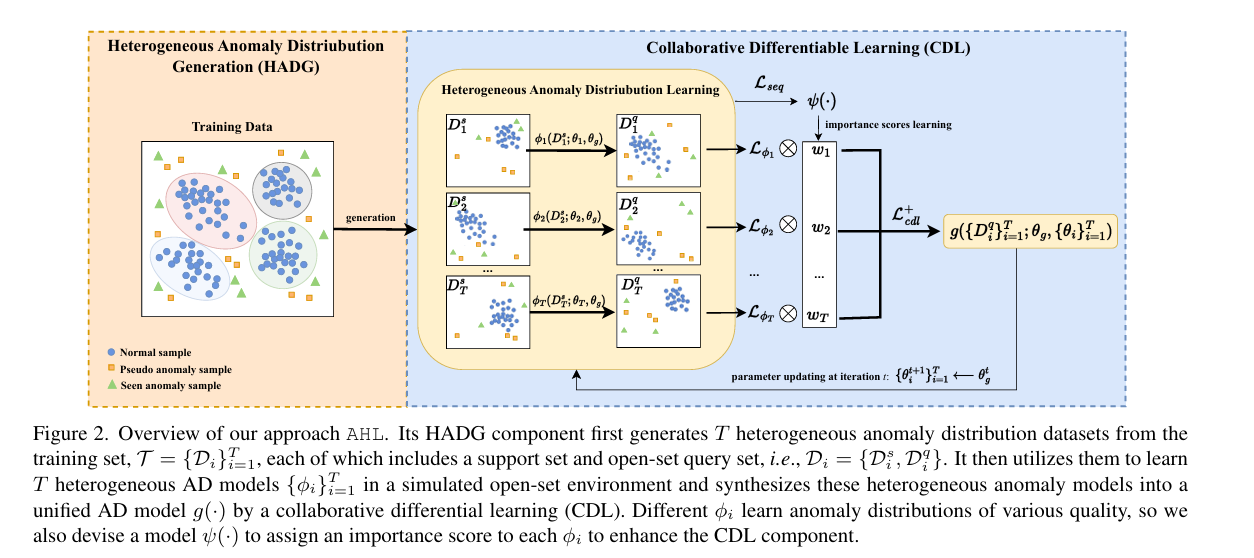
摘要:开放集监督异常检测(OSAD)是一种新兴的异常检测领域——旨在利用少数异常类别样本进行训练,检测未见异常(即来自开放集异常类别的样本),同时有效识别异常样本。受益于已见异常所提供的先验知识,当前的OSAD方法大多能显著减少误报。然而,这些方法通常在封闭集设置下进行训练,将异常样本视为同质分布,这使得它们在泛化到来自任何分布的未见异常时效果不佳。 本文提出一种利用有限异常样本学习异质异常分布的方法,以解决该问题。为此,我们引入了一种新方法——异常异质性学习(AHL),它模拟了多样的异质异常分布,然后利用这些分布来学习统一的异质异常模型,用于各种开放集环境。此外,AHL是一个通用框架,现有的OSAD模型可以嵌入其中,以增强异常建模能力。在九个真实世界异常检测数据集上进行的大量实验表明,AHL能够:1)显著增强不同的先进OSAD模型在检测已见和未见异常方面的能力;2)有效地泛化到新的异常类别。代码可在https://github.com/mala-lab/AHL获取。
2.7 Toward Generalist Anomaly Detection via In-context Residual Learning with Few-shot Sample Prompts
基于小样本提示的上下文残差学习实现通用异常检测
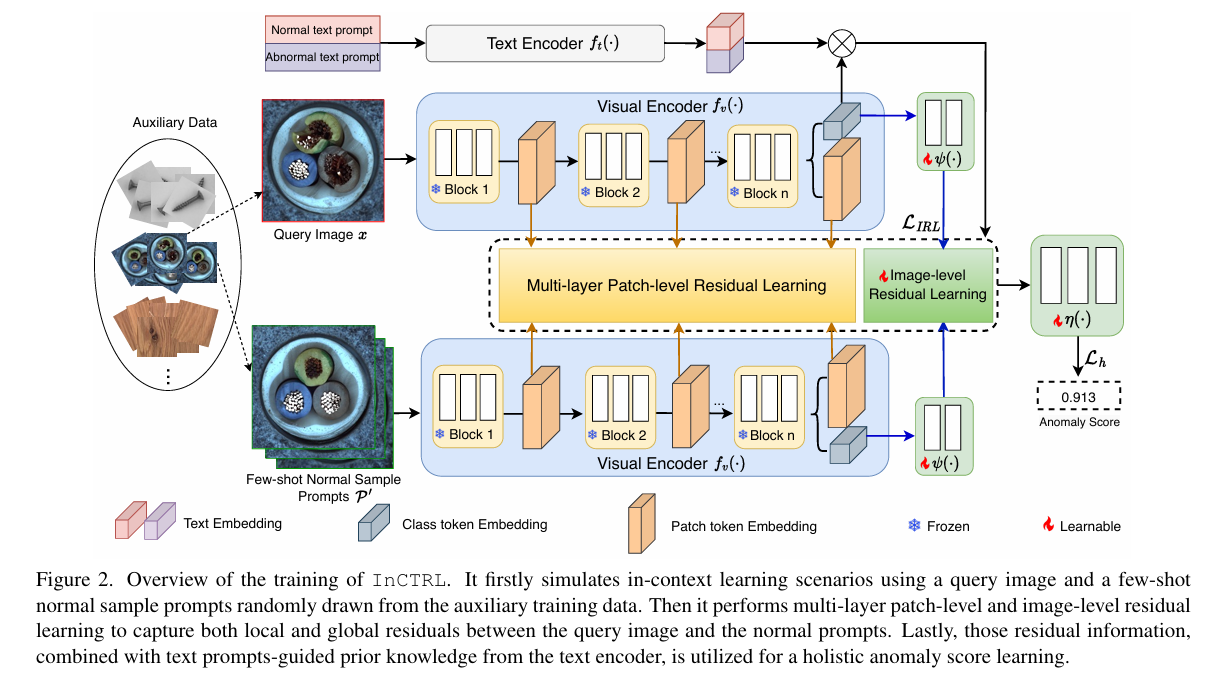
摘要:本文探讨通用异常检测(GAD)问题,旨在训练一个单一检测模型,使其能够泛化检测来自不同应用领域的各种数据集里的异常,且无需从目标数据进一步训练。近期研究表明,像CLIP这样的大规模预训练视觉 - 语言模型(VLMs)在检测来自不同数据集的工业缺陷方面具有泛化能力,但它们的方法严重依赖于手动编写的关于缺陷的文本提示,这使得它们难以泛化到其他应用中的异常,比如医学图像异常或自然图像中的语义异常。 在这项工作中,我们提出使用少样本正常图像作为AD样本提示来训练一个GAD模型。为此,我们引入一种新的上下文残差学习模型InCTRL,它在辅助数据集上进行训练,以区分基于少样本正常样本提示与查询图像之间残差的真实异常。预计数据集的残差越大,异常程度越高。因此,InCTRL能够跨不同领域进行泛化,而无需进一步训练。我们在九个AD数据集上进行了全面实验,以建立一个能够涵盖工业缺陷异常、医学异常和语义异常检测的GAD基准。在单类和多类设置中,InCTRL在这两个任务中均是最佳性能模型,自信地超越了当前最先进的比较方法。代码可在https://github.com/mula-lab/InCTRL获取。
2.8 RealNet: A Feature Selection Network with Realistic Synthetic Anomaly for Anomaly Detection
RealNet:结合真实合成异常的特征选择网络用于异常检测
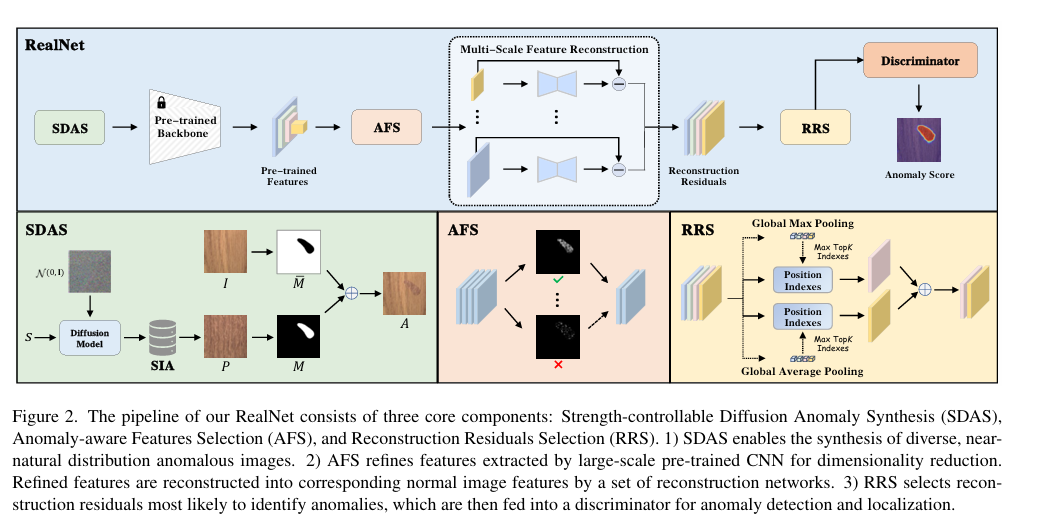
摘要:自监督特征重建方法在工业图像异常检测与定位方面已取得显著进展。尽管如此,这些方法在合成真实且多样的异常样本时仍面临挑战,同时还需解决特征冗余问题以及预训练重建网络的偏差问题。在本文中,我们引入RealNet,这是一种具有真实合成与自适应特征的预训练重建网络。它有三项创新:首先,我们提出强度可控扩散异常合成(SDAS),这是一种基于扩散过程的合成策略,可生成具有不同异常强度的样本,以模拟真实异常样本的分布。其次,我们开发了异常感知特征选择(AFS)方法,用于选择敏感且有区分度的预训练特征子集,在控制计算成本的同时提高异常检测性能。第三,我们引入重建残差选择(RRS)策略,该策略从多个泛化层次中自适应选择有区分度的残差,以全面识别异常区域。我们在四个基准数据集上对RealNet进行评估,结果表明,与当前先进方法相比,它在全局AUROC和像素级AUROC方面均有显著提升。代码、数据和模型可在https://github.com/cnulab/RealNet获取。
2.9 Long-Tailed Anomaly Detection with Learnable Class Names
可学习类别名称的长尾异常检测
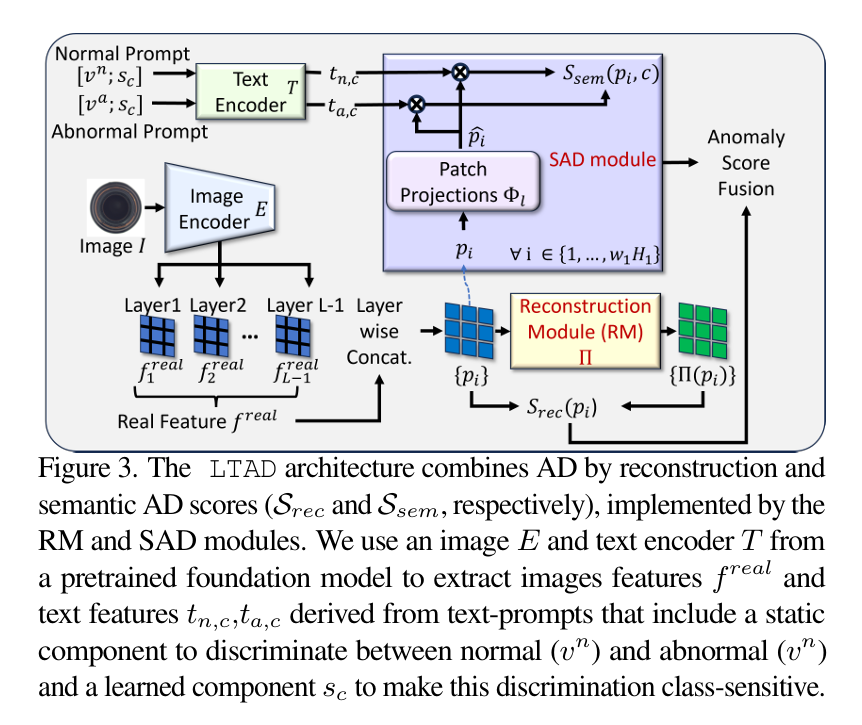
摘要:异常检测(AD)旨在识别有缺陷的图像,并在存在缺陷时对其进行定位。理想情况下,异常检测模型应能够在不依赖硬编码缺陷类别名称(这些名称在不同数据集中可能不统一或不一致)的情况下,识别多种图像类别中的缺陷;能够在无异常监督的情况下进行学习;并且能够在面对现实应用中的长尾分布时保持稳健。 为解决这些挑战,我们通过引入具有不同长度的多个AD模块和多种性能评估指标,对长尾异常检测问题进行了形式化定义。然后,我们提出一种全新的方法——长尾异常检测(LTAD),用于检测多种图像类别和长尾分布中的缺陷,且不依赖数据集特定名称。LTAD将基于重建的异常检测与基于变换器的重建模块以及语义AD相结合。语义AD通过二元分类器来实现,该分类器依赖于学习到的伪类别名称和预训练模型。这些模块分两个阶段进行学习。第一阶段(VAE)进行特征合成,以对抗长尾问题。第二阶段则学习LTAD重建和分类模块的参数。在提出的长尾数据集上进行的大量实验表明,LTAD显著优于当前最先进的方法,并且其完整数据集可在https://zenodo.org/records/10854201获取。
2.10 Text-Guided Variational Image Generation for Industrial Anomaly Detection and Segmentation
文本引导变分图像生成用于工业异常检测与分割
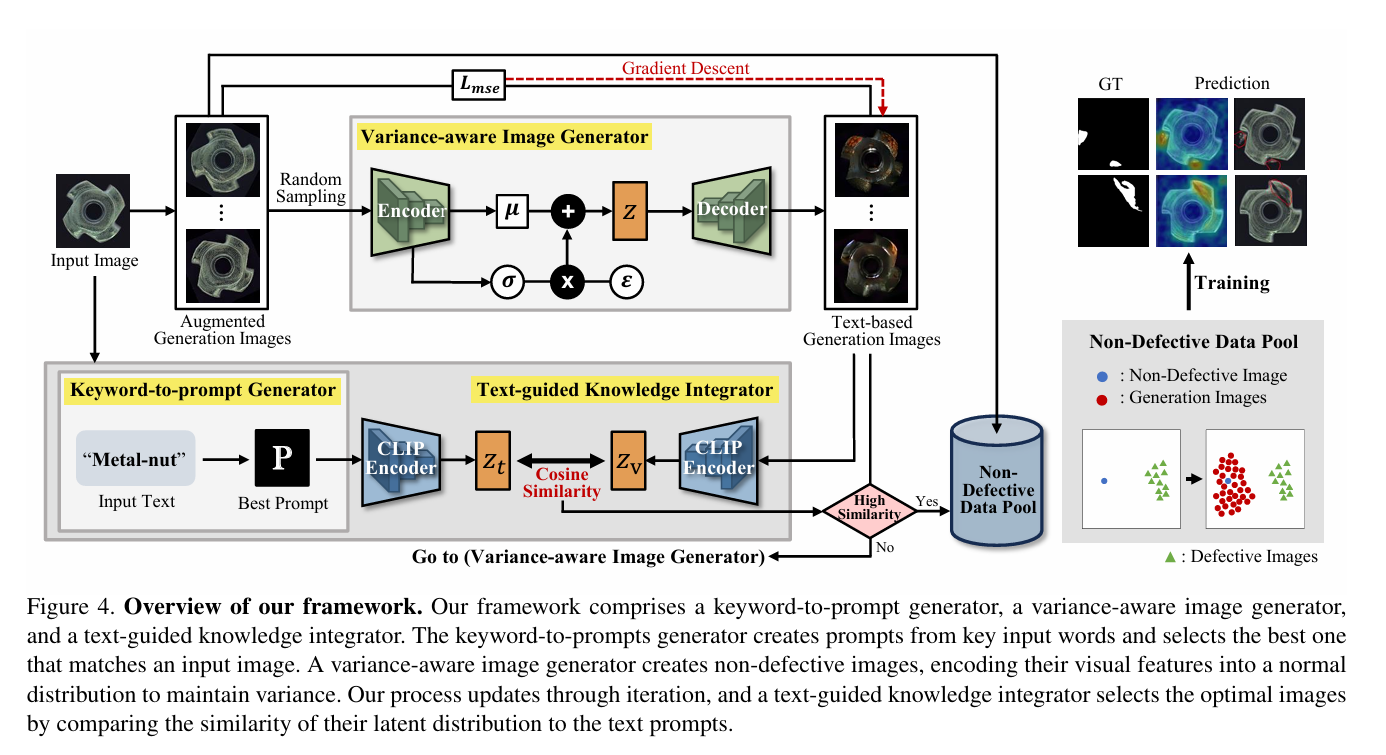
摘要:我们提出一种文本引导的变分图像生成方法,以应对为工业制造中的异常检测获取纯净数据这一挑战。我们的方法利用从大量文本库文档中学习到的关于目标物体的文本信息,生成与输入图像相似的无缺陷数据图像。所提出的框架确保生成的无缺陷图像符合从文本和图像知识中推导出的预期分布,从而保证稳定性和通用性。实验结果表明我们的方法行之有效,即便在无缺陷数据有限的情况下也优于先前的方法。我们通过在四个基准模型和三个不同数据集上进行泛化测试来验证该方法。此外,我们还开展了一项额外分析,探索如何利用生成的图像来提升异常检测模型的效能。
三、三维异常检测
3.1 Towards Scalable 3D Anomaly Detection and Localization: A Benchmark via 3D Anomaly Synthesis and A Self-Supervised Learning Network
面向可扩展三维异常检测与定位:基于三维异常合成与自监督学习网络的基准
(看过了)
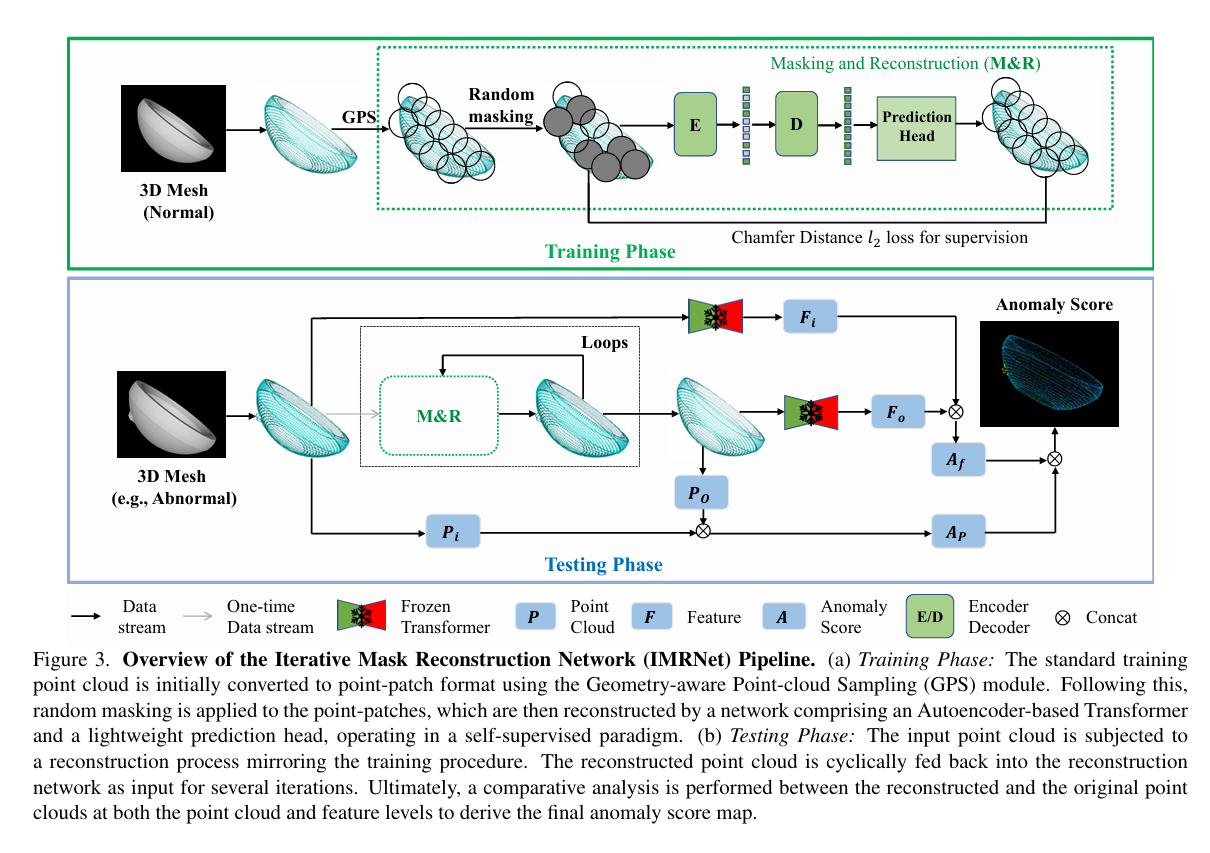
摘要:近来,三维异常检测作为一项涉及精细几何判别能力的关键问题,受到了越来越多的关注。然而,由于缺乏丰富的真实三维异常数据,当前模型的可扩展性受到限制。为实现可扩展的异常数据收集,我们提出了一种三维异常合成流水线,以适配现有的大规模三维模型用于三维异常检测。具体而言,我们基于ShapeNet构建了一个合成异常数据集Anomaly - ShapeNet,它包含1600个点云样本,涵盖40个类别,提供了丰富多样的数据集合,能够实现高效的训练,并增强对工业场景的适应性。 同时,为实现三维异常定位的可扩展表示学习,我们提出了一种自监督方法,即迭代掩码重建网络(IMRNet)。在训练过程中,文章提出一个几何感知采样模块,以在点云下采样时保留潜在的异常局部区域。然后,我们随机遮蔽点云块,并将可见块输入到基于重建的自监督变换器中。在测试时,点云通过掩码重建网络反复输入,每次迭代的输出与下一次输入相融合。通过将最终重建的点云与初始输入进行比较,我们的方法成功定位了异常。实验表明,IMRNet优于先前的先进方法,在Anomaly - ShapeNet数据集上实现了66.1%的IAUC,在Real3D - AD数据集上达到了72.5%。我们的代码和数据集将在https://github.com/Chopper-233/Anomaly-ShapeNet上发布。
四、多模态异常检测
4.1 Multimodal Industrial Anomaly Detection by Crossmodal Feature Mapping
跨模态特征映射的多模态工业异常检测
(看过了)
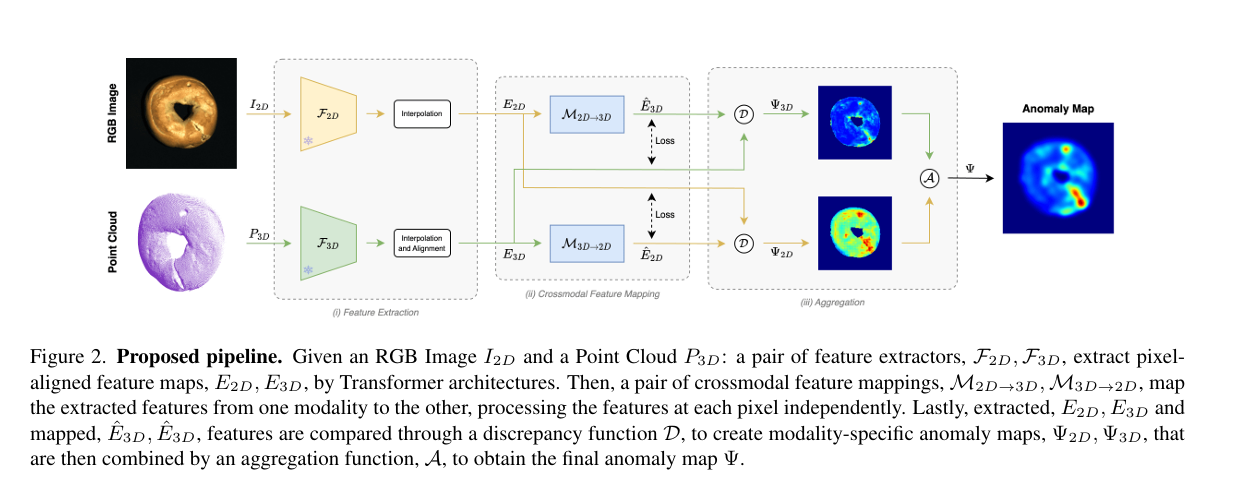
摘要:近期的研究进展表明,利用点云和图像来定位异常具有潜力。然而,它们在工业制造中的适用性常常受到显著缺陷的限制,例如使用记忆库,这会导致内存占用和推理时间大幅增加。 我们提出一种全新的轻量快速框架,该框架在正常样本上学习将特征从一种模态映射到另一种模态,并通过精确找出观测特征与映射特征之间的不一致来检测异常。大量实验表明,我们的方法在MVTec 3D - AD数据集上,无论是标准设置还是小样本设置,均取得了领先的检测和分割性能,同时与先前的多模态异常检测方法相比,推理速度更快且内存占用更少。此外,我们提出一种层剪枝技术,在性能稍有牺牲的情况下提高内存和时间效率。
4.2 Looking 3D: Anomaly Detection with 2D-3D Alignment
三维视角:基于二维-三维对齐的异常检测
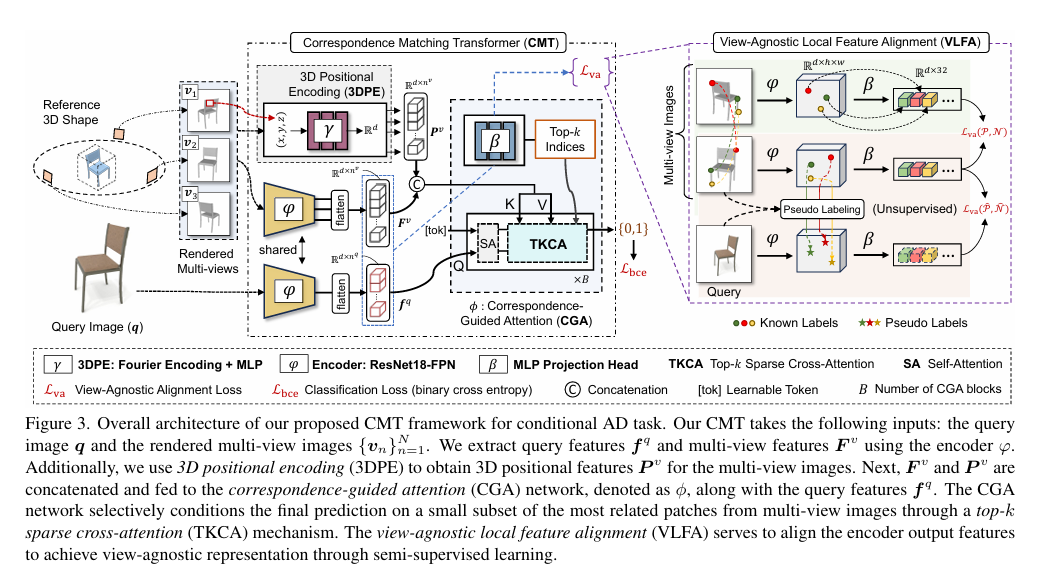
摘要:基于视觉线索的自动异常检测在制造和产品质量评估等多个领域具有实际意义。本文引入了一种新的条件异常检测问题,该问题涉及识别查询图像中的异常,并将其与参考形状进行比较。为应对这一挑战,我们创建了一个大型数据集BrokenChairs - 180K,该数据集包含约180K张图像,这些图像具有不同的异常、几何形状和纹理,且配有8,143个参考三维形状。为解决此任务,我们提出了一种基于变换器的新方法,该方法明确学习查询图像与参考三维形状之间的对应关系,通过特征对齐来实现,并采用了定制的注意力机制进行异常检测。我们的方法已通过全面实验进行了严格评估,为该领域未来的研究提供了基准。
五、生成图像的异常分数
5.1 Anomaly Score: Evaluating Generative Models and Individual Generated Images based on Complexity and Vulnerability
异常分数:基于复杂性和脆弱性评估生成模型及单个生成图像
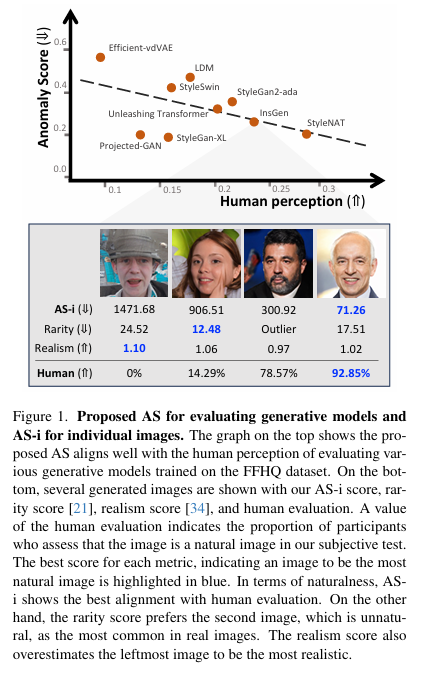
摘要:随着生成模型的发展,对生成图像的评估变得愈发重要。以往的方法多是测量经训练的视觉模型中参考图像与生成图像的特征。在本文中,我们深入探究生成图像周围表示空间与输入空间之间的关系。我们首先提出了两个衡量图像中不自然元素的指标:复杂性,用于指示表示空间中的非线性程度;脆弱性,与提取的特征因对抗性输入变化而改变的难易程度相关。基于此,我们引入了一种用于评估图像生成模型的新指标——异常分数(AS)。此外,我们还提出了AS - i(单个图像异常分数),它能够有效评估单个生成图像。实验结果证明了所提方法的有效性。

















 1577
1577

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









