






之前认知里面,java的String一直是使用char数组,但是今天点进去瞟了一眼,发现不对。
源码如下:
/**
* The value is used for character storage.
*
* @implNote This field is trusted by the VM, and is a subject to
* constant folding if String instance is constant. Overwriting this
* field after construction will cause problems.
*
* Additionally, it is marked with {@link Stable} to trust the contents
* of the array. No other facility in JDK provides this functionality (yet).
* {@link Stable} is safe here, because value is never null.
*/
@Stable
private final byte[] value;
这分明就是byte数组,哪里是char了?于是上网查了下,这个改动在 Java9以后就发生了。
为什么有这个改动?char -> byte
主要还是节省空间。
JDK9 之前的库的 String 类的实现使用了 char 数组来存放字符串,char 占用16位,即两字节。
private final char value[];
这种情况下,如果我们要存储字符A,则为0x00 0x41,此时前面的一个字节空间浪费了。但如果保存中文字符则不存在浪费的情况,也就是说如果保存 ISO-8859-1编码内的字符则浪费,之外的字符则不会浪费。
而 JDK9 后 String 类的实现使用了 byte 数组存放字符串,每个 byte 占用8位,即1字节。
private final byte[] value
但是如果遇到ISO-8859-1 编码外的字符串呢?比如中文咋办?
Java9之后String的新属性,coder编码格式
借用网上盗的一个图:
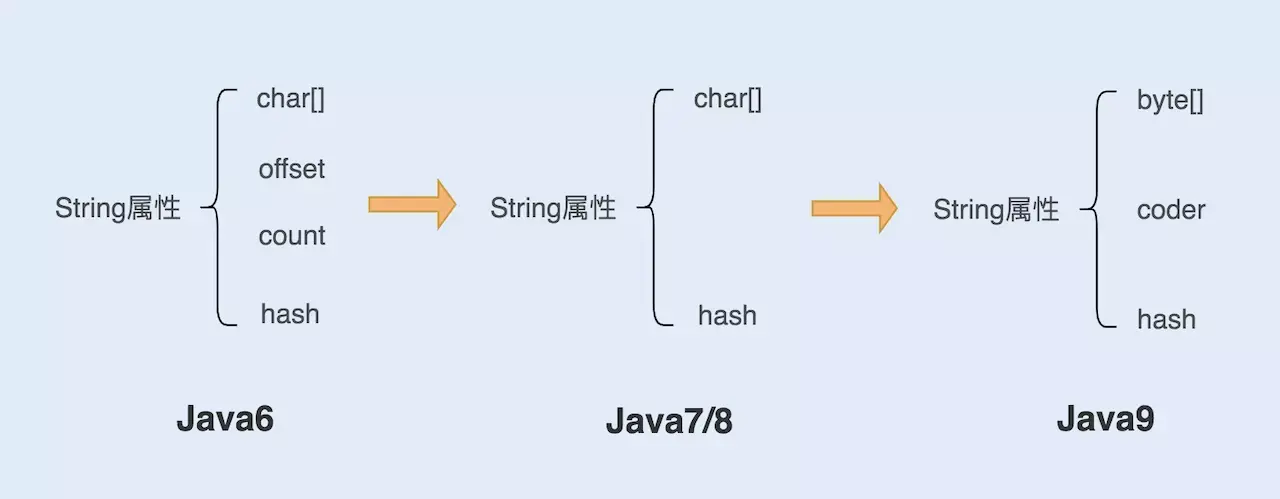
Java String的演进
private final byte coder;
static final boolean COMPACT_STRINGS;
static {
COMPACT_STRINGS = true;
}
byte coder() {
return COMPACT_STRINGS ? coder : UTF16;
}
@Native static final byte LATIN1 = 0;
@Native static final byte UTF16 = 1;
是编码格式的标识,在计算字符串长度或者调用 indexOf() 函数时,需要根据这个字段,判断如何计算字符串长度。
coder 属性默认有 0 和 1 两个值。如果 String判断字符串只包含了 Latin-1,则 coder 属性值为 0 ,反之则为 1
- 0 代表Latin-1(单字节编码)
- 1 代表 UTF-16 编码。。
Java9 默认打开COMPACT_STRINGS, 而如果想要取消紧凑的布局可以通过配置 VM 参数-XX:-CompactStrings实现。
















 451
451

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











