






 本文介绍了在iOS16项目中选择Touchelf进行自动化测试的过程,作者遇到Esxi部署问题后,转向使用Umi-OCR并提供了一个Python脚本示例,用于通过Umi-OCR进行OCR识别,解决在Esxi环境中的部署问题。
本文介绍了在iOS16项目中选择Touchelf进行自动化测试的过程,作者遇到Esxi部署问题后,转向使用Umi-OCR并提供了一个Python脚本示例,用于通过Umi-OCR进行OCR识别,解决在Esxi环境中的部署问题。
最近有个项目,需要ios自动化,看了很多开发工具选择,最后选择touchelf(触摸精灵),当然其他精灵也可以用,就是post提交,因为我的系统是ios16,能支持最新系统的自动化开发工具少之又少,随后去B站看了很多touchelf教程.当然,又是少之又少,我有python开发经验,这个搞起来不难,发现有一个星点教育的,随后用了他们的ocr识别产品,想的是少造轮子,不是说它不好,而是出现了一个我无法忍受的BUG,就是不能部署在Esxi虚拟机里边,不论我如何搞,就是打不开,随后就有了下面教程,经过一顿搜索,发现星点用的也是开源项目打包来的,至于为什么收费,,,收打包费吗?
这里我推荐: Umi-OCR 下载地址
Umi-OCR暂时没有Linux的,直接Windows下载打开即可,版本根据自己电脑性能选择,电脑提前准备好7z解压,然后打开安装包,解压成一个文件夹,打开此文件夹,打开 Umi-OCR
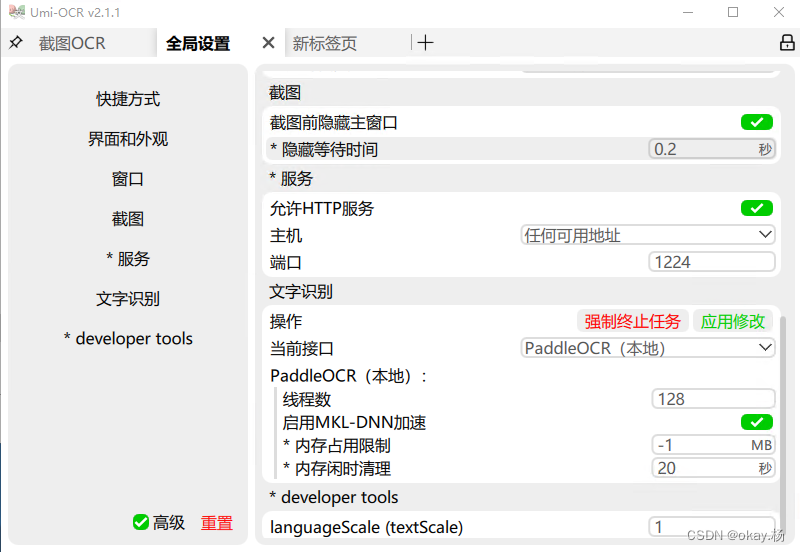
点击高级,勾选允许http服务 主机: 任何可用地址
然后找到自己电脑的ipv4地址(网卡里边也能看),cmd命令:
ipconfig我用了python作为中转服务器,减少手机数据处理,python代码量也更少,错误处理也相对容易,你也可以不用python服务,直接往umi ocr 提交,自己在lua里边配置这些提交参数,发给 http://192.168.0.17:1224/api/ocr
再进行遍历,拆分,计算中间坐标即可
zh = "models/config_chinese.txt"
tw = "models/config_chinese_cht(v2).txt"
kr = "models/config_korean.txt"
ru = "models/config_cyrillic.txt"
ja = "models/config_japan.txt"
local body = {}
body["base64"] = base64_data
local options = {}
options["tbpu.parser"] = 'multi_para'
options["data.format"] = 'json'
options["ocr.angle"] = false
options["ocr.language"] = zh
body["options"] =options
local header = {}
header["Content-Type"] = "application/json"
local body_data, _ = httpPost("http://192.168.0.17:1224/api/ocr",header,jsonEncode(body), 30)
local data = jsonDecode(body_data)
if data['code'] == "100" then
sys.log("umi-ocr识别成功: ")
sys.log(data)
return data
else
sys.log("识别失败")
sys.log(data) -- 失败的返回值
return nil
end我这里是: 192.168.0.17
python依赖,需要安装好python,如果不会python或者一点都看不懂,,,这教程不合适你
pip install requests
pip install uvicorn
pip install fastapi# -*- coding: utf-8 -*-
import requests
import uvicorn
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
def ocr(language, base64_data):
if language == "en":
# English
language_code = "models/config_en.txt"
elif language == "zh":
# 简体中文
language_code = "models/config_chinese.txt"
elif language == "tw":
# 繁體中文
language_code = "models/config_chinese_cht(v2).txt"
elif language == "kr":
# 한국어
language_code = "models/config_korean.txt"
elif language == "ru":
# Русский
language_code = "models/config_cyrillic.txt"
elif language == "ja":
# 日本語
language_code = "models/config_japan.txt"
else:
print("没有传入语言代码")
return None
payload = {
"base64": base64_data,
"options": {
# 通用参数
"tbpu.parser": "multi_para",
"data.format": "json",
# 引擎参数
"ocr.angle": False, # 是否进行图像旋转校正
"ocr.language": language_code,
}
}
result = requests.post('http://192.168.0.17:1224/api/ocr', json=payload).json()
if result['code'] == 100:
return result
else:
return None
def ocr_lua_data_dict(data, box):
return {
"text": data['text'],
"x": (box[0][0] + box[1][0]) / 2,
"y": (box[0][1] + box[2][1]) / 2,
"box": data['box'],
}
def umi_ocr(keyword, language, base64_data, contains: bool = True):
result = ocr(language, base64_data)
if result is None:
return None
# 左上角 右上角 左下角 右下角
# [111, 826], [330, 826], [330, 854], [111, 854]
for data in result['data']:
if contains:
if keyword in data["text"]:
print(data)
return ocr_lua_data_dict(data, data['box'])
else:
if data["text"] == keyword:
print(data)
return ocr_lua_data_dict(data, data['box'])
print("ocr没识别到包含文本")
return None
class OcrItem(BaseModel):
keyword: str
language: str
Base64: str
contains: bool
@app.post("/ocr_text", summary="umi ocr识别指定文本-返回坐标")
async def ocr_img(data: OcrItem):
# "英语":"en",
# "日语":"ja",
# "简体中文":"zh",
# "繁体中文":"tw",
# "俄语":"ru",
# "韩语":"kr",
# keyword: 要匹配的关键词 language:语言模型 contains:包含关键词还是等于,如果为假就是等于,全部匹配
# payload = {
# "keyword": "Search",
# "language": "en",
# "contains": "true",
# "Base64": img_data
# }
try:
body = data.model_dump()
result = umi_ocr(body['keyword'], body['language'], data.Base64, body['contains'])
if result is None or result == []:
return {"status": "error", "result": None}
else:
return {"status": "ok", "result": result}
except Exception as e:
return {"status": "error", "result": None, "error": e}
if __name__ == "__main__":
# 这python文件名字一定是 server.py 不然无法启动
uvicorn.run("server:app", host="0.0.0.0", port=8000, reload=False)
启动python服务器以后,触摸这边就可以提交了,代码如下
-- 这里是IOS目录
local img_path = "/var/touchelf/"..'截图.png'
screen.snapshot(img_path)
local file_data = file.read(img_path)
local body = {Base64=codec.base64.encode(file_data)}
body['language'] = 'zh' -- 语言模型
body['keyword'] = '搜索' -- 要匹配的关键字
body['contains'] = false -- 传布尔值,包含还是全匹配,这里选包含
local header = {}
header["Content-Type"] = "application/json"
local body_data, _ = httpPost("http://192.168.0.17:8000/ocr_text",header,jsonEncode(body), 30)
local data = jsonDecode(body_data)
if data['status'] == "ok" then
sys.log("umi-ocr识别成功: "..result["text"])
return result["x"],result["y"]
else
sys.log("识别失败")
sys.log(body_data) -- 失败的返回值
return -1,-1
end
















 1083
1083

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









