







DOM= Document Object Model,文档对象模型,DOM可以以一种独立于平台和语言的方式访问和修改一个文档的内容和结构。换句话说,这是表示和处理一个HTML或XML文档的常用方法。
在Java中使用DOM解析XML文件,将整个xml文件加载到内存中,之后通过各种调用方法获取xml文件中的内容
1.DocumentBuilderFactory对象
2.DocumentBuilder对象
3.Document对象使用parse方法进行解析
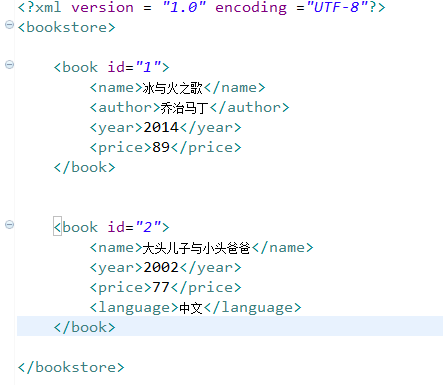
具体代码实现如下:
import java.io.IOException;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import org.w3c.dom.Document;
import org.w3c.dom.NamedNodeMap;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.xml.sax.SAXException;
public class DOMTest {
public static void main(String[] args) {
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
try {
DocumentBuilder builder = factory.newDocumentBuilder();
Document document = builder.parse("books.xml");
// 获取book节点的集合
NodeList bookList = document.getElementsByTagName("book");
// 通过nodeList的getLength()方法,获取长度
System.out.println("共有"+bookList.getLength()+"本书");
for (int i = 0; i < bookList.getLength(); i++) {
// 获取一个book节点
Node book = bookList.item(i);
// 获取book节点所有属性的集合
NamedNodeMap attrs = book.getAttributes();
System.out.println("第"+(i+1)+"本书共有"+attrs.getLength()+"个属性");
// 遍历book的属性
for (int j = 0; j < attrs.getLength(); j++) {
Node attr = attrs.item(j);//通过item(index)方法获取属性
// 获取属性名
System.out.println("属性名:"+attr.getNodeName());
// 获取属性值
System.out.println("属性名:"+attr.getNodeValue());
}
// 获取book节点下所有子节点的集合
NodeList childNodes = book.getChildNodes();
System.out.println("第"+(i+1)+"本书下共有"+childNodes.getLength()+"个子节点");
for (int k = 0; k < childNodes.getLength(); k++) {
// 空白部分看做 Node.TEXT_NODE 标签部分 Node.ELEMENT_NODE,所以一共有9个子节点
if(childNodes.item(k).getNodeType()==Node.ELEMENT_NODE){
// 标签间的内容被看做是标签子节点的节点值
// 获取第一个子节点的内容
//System.out.println(childNodes.item(k).getNodeName()+":"+childNodes.item(k).getFirstChild().getNodeValue());
// 获取标签间所有子标签的text内容
System.out.println(childNodes.item(k).getNodeName()+":"+childNodes.item(k).getTextContent());
}
}
}
} catch (ParserConfigurationException e) {
e.printStackTrace();
} catch (SAXException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}















 1513
1513

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









