






Idea of WGAN
在GAN01:GAN的原理与DCGAN的Keras实现中,我们了解到,GAN的目的是使用生成器分布PG拟合数据的真实分布Pdata,在GAN的初始paper以及DCGAN的实现中,实际上计算这两者之间分布差的那个度量标准是JS-Divergence,而利用Sample的方法计算Divergence,就是上文中我们使用的Binary Crossentropy Loss。
由下图可以看出,JSD造成的问题是梯度下降不够平缓,生成器没有足够的动力向Pdata逼近。

WGAN被提出以解决这个问题,WGAN使用W量度(EM量度)来度量两个分布之间的相近程度,这种量度可以保证梯度的平缓,换句话说,能够为PG提供足够的动力逼近Pdata。

W距离的初始定义由上图所示,但是在实作中,我们sample的方式计算
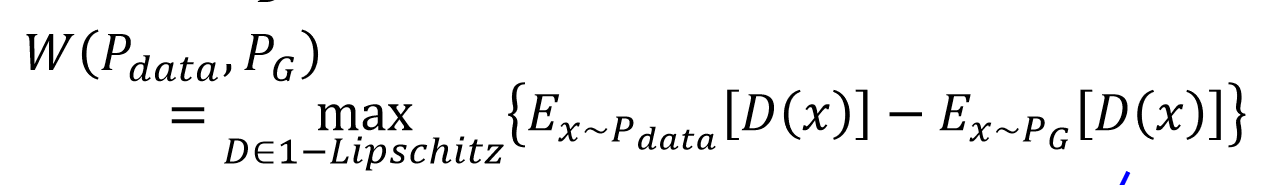
只要D在1~李普希茨函数内取值,即y的变化慢于x的变化,就可以以上式计算W距离
两种满足1~李普希茨的方式
1.weight clipping,这种方式在初始时将所有的weight设在-c到c之间,并且在每次更新后将超出[-c,c]的规范化参数到[-c,c]之间,这种方法被证明可以满足k-lipschitz条件。

2. Weight Penalty,第一种方式的问题是他经常导致参数集中在-c和c的位置,因此人们开发了这种方式,通过对超出-1的weight添加惩罚项,来限制函数处于lipschitz范围内。

WGAN的Keras实现
这种方式相比之前我们实现的DCGAN有两点主要的不同,我只说一下这两点不同。
使用W-loss代替二分类交叉熵loss
WGAN的paper中提出了一种新的loss_function
Loss=D(real)-D(fake)
在Keras中,我们是这样实现的:

因为我们会给real的sample传lable=1,因此real的Loss=y_pred*1=y_pred
因为我们会给real的sample传lable=-1,因此fake的Loss=y_pred*-1=-y_pred
二者结合即得W-Loss
Weight Clipping

WGAN-GP的pytorch实现
这种实现中的疑点较多,换句话说,值得理解的地方也较多,写在下篇blog里。















 1715
1715











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









