




 本课程由李宏毅教授于2020年开设,重点讲解深度学习在人类语言处理(HLP)领域的应用,涵盖了语音识别、语音合成、文字处理等六大类主题,强调了语音处理不仅仅是语音识别,还包括了多种复杂的语音与文字转换技术。
本课程由李宏毅教授于2020年开设,重点讲解深度学习在人类语言处理(HLP)领域的应用,涵盖了语音识别、语音合成、文字处理等六大类主题,强调了语音处理不仅仅是语音识别,还包括了多种复杂的语音与文字转换技术。
文章目录
介绍
本门课程是2020年李宏毅老师新课:Deep Learning for Human Language Processing(深度学习与人类语言处理)
课程网站:http://speech.ee.ntu.edu.tw/~tlkagk/courses_DLHLP20.html
B站视频:https://www.bilibili.com/video/BV1EE411g7Uk?t=222
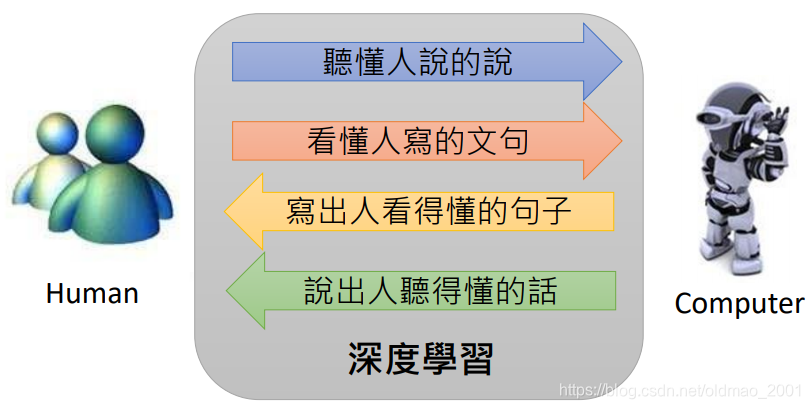
HLP vs NLP
Natural Language Processing, NLP
• A language that has developed naturally in use (e.g. Chinese, English)
• As contrasted with an artificial language (e.g. JAVA, Python)
• Natural Language can be Speech or Text
• Most NLP textbook and course mainly focus on text (Text v.s. Speech = 9 : 1)
这门课叫HLP的原因:
• In this course, Text v.s. Speech = 5 : 5
• Speech processing is NOT only speech recognition.语音处理不单单是语音识别
• Only 56% languages have written form (Ethnologue, 21st edition). 有很多语言没有文字
• We don’t always know if the existing writing systems are widely used. 即使有文字也未必使用这些文字
公式输入请参考:在线Latex公式
语音概述
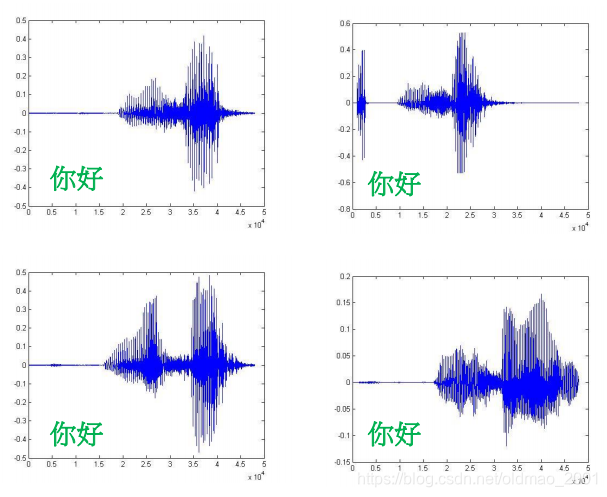
Human Language is complex:1 second has 16K(一万六千) sample points Each point has 256 possible values.

没有有人可以说同一段话两次,下面是老师说四次你好。
文字概述
William Faulkner, “Absalom, Absalom.”: “Just exactly like Father if Father had known ……” (1289 words)早期最长的句子
Jonathan Coe’s The Rotters’ Club has a sentence with 13,955 words (2014年世界最长句纪录)
这个纪录是随时可以打破的,例如下面三个句子一个比一个长一点。
Faulkner wrote, “Just exactly like Father …”
Pinker said Faulkner wrote, “Just exactly like Father …”
Who cares that Pinker said Faulkner wrote, “Just exactly like Father …”
可以看到句子是可以无限长,也就是说句子可以非常复杂。
本课程内容(六类)
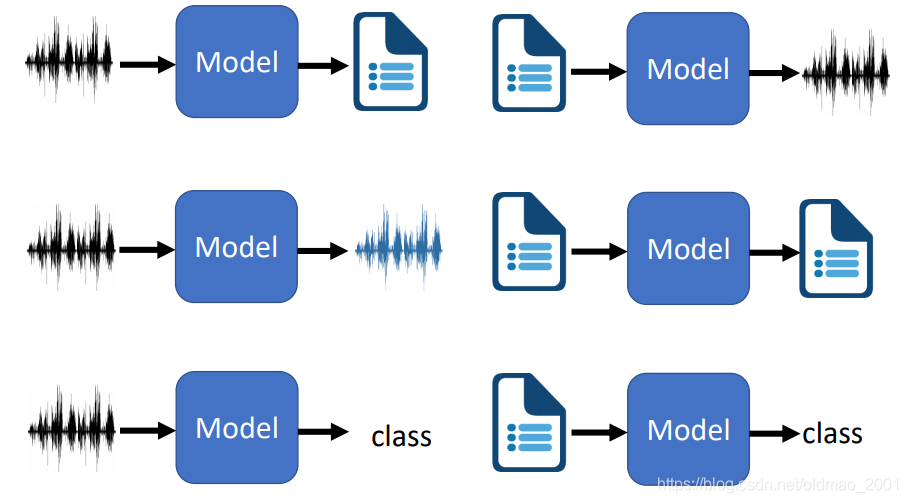
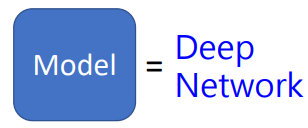
虽然可以用Seq2Seq进行硬【 train 一发】,但是这个并不是最终解决方案,下面大概对这几种处理分别简单介绍。
Automatic Speech Recognition(ASR)
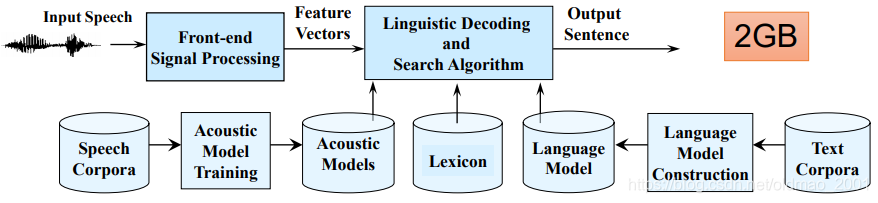
Traditional Speech Recognition 模型复杂,有很多模块构成
而在手机上实现的端到端语音识别系统仅需要80MB,而且用的还不是传统的Seq2Seq。
语音合成
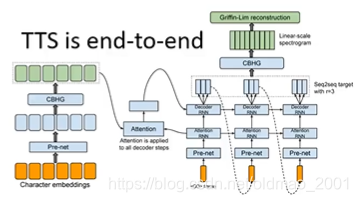
语音转语音

Speech Separation:主要用于鸡尾酒会效应(cocktail party effect)分离合成会话
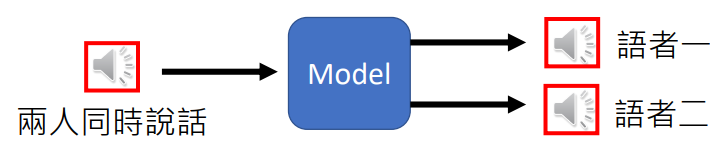
Voice Conversion:变声器(柯南)
按下图的思路是行不通的,例如你想要变声为川普,他出场费你出不起,出得起也不可能会说同样的中文。
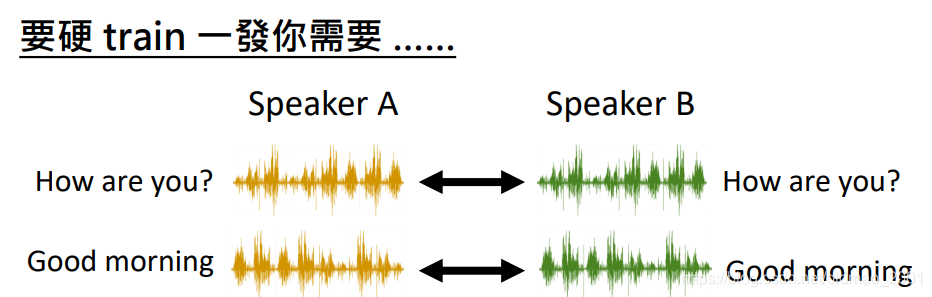
因此:Speakers A and B are talking about completely different things.

老师还给了一个demo的例子: Only one utterance from each speaker (one-shot learning)

Input Audio, Output Class
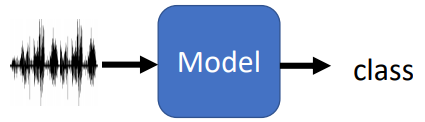
应用:
Speaker Recognition:辨别声音所属人
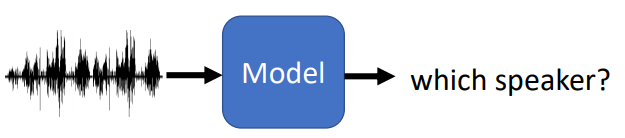
Keyword Spotting
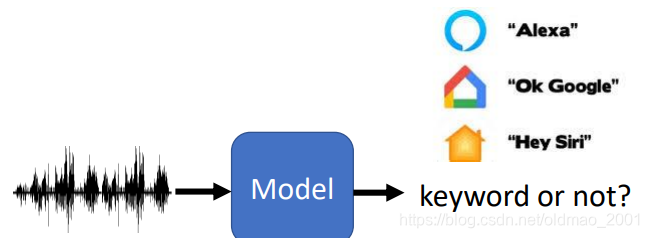
关键字唤醒,小米曾经有报道过,小爱能做到在日常对话中只相应关键问句,而非指向性的说话则不反应。
模型不能太大,否则太耗电,因为模型要不停的运行监听。
文字2文字
有很多应用:
翻译Translation
摘要Summarization
聊天Chat-bot
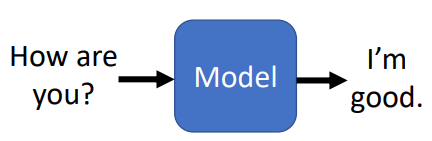
问答Question Answering
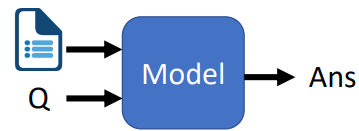
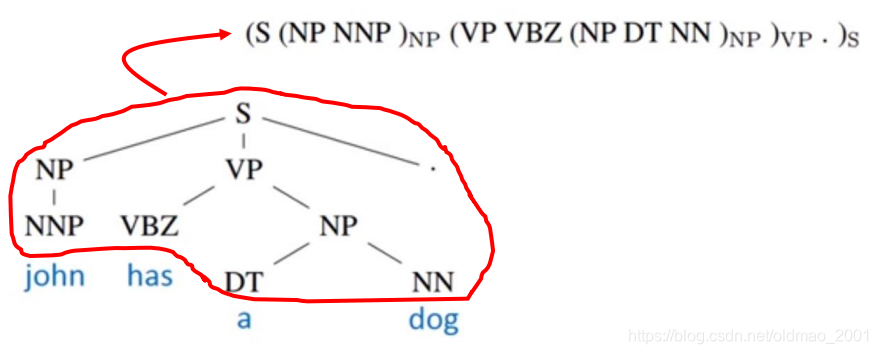
语法解析
以上应用原理相似,只会讲Question Answering
其他
本课程还包括:
Meta learning
Knowledge Graph知识图谱
Adversarial Attack
Explainable AI



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











