







介绍
本门课程是2020年李宏毅老师新课:Deep Learning for Human Language Processing(深度学习与人类语言处理)
课程网站:http://speech.ee.ntu.edu.tw/~tlkagk/courses_DLHLP20.html
B站视频:https://www.bilibili.com/video/BV1EE411g7Uk?t=222
公式输入请参考:在线Latex公式

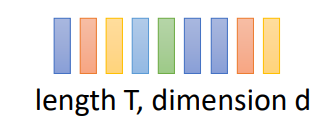
Speech: a sequence of vector (length T, dimension d)
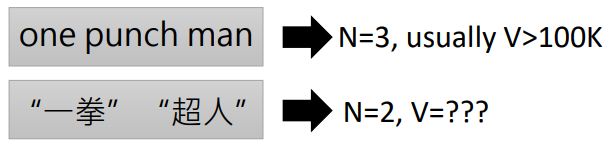
Text: a sequence of token (length N, V different tokens)
Usually T > N
下面看看构成语音的不同要素单位:Token
或者说看一看语音识别的输入是啥东西
Token
Phoneme
a unit of sound
音位,又译音素,是人类语言中能够区别意义的最小声音单位,是音位学分析的基础概念。一个字或词可由一至数个音节组成,一个音节可由一至数个“音段”组成。

音素词典Lexicon: word to phonemes

有了词典就可以找出音素与单词的对应关系。
Phoneme和声音对应关系非常明显,在深度学习出现前,Phoneme常常用于语音识别,但是其缺点是需要音素词典才能把Phoneme对应到词,这个词典不好做,要专业语言学家才可以,而且有一些语言的Phoneme还不好找~!
Grapheme
smallest unit of a writing system
字位(字形、字素,英語:grapheme)这个术语,是由语音学里的“音位”(音素)类推到文字学的。
对于英文:26 English alphabet + { _ } (space空格)+ {punctuation marks标点符号}
Chinese does not need “space”
例如:

比Phoneme难训练
Word
For some languages, V can be too large!例如中文不是用空格来划分词,所以中文分词超级麻烦
老师来旁征博引给了一个
Agglutinative language:土耳其文

Morpheme
the smallest meaningful unit
词素是构成词的要素。是语言中最小单位的音义结合体。词素是比词低一级的单位,词是语言中能够独立运用的最小单位,是指词在句法结构中的地位和作用而言的。从语言的词本身来讲,很多词可以进一步分析成若干个最小的音义统一体,即词素。
例如:
unbreakable → “un” “break” “able”
rekillable → “re” “kill” “able”
What are the morphemes in a language? linguistic or statistic
Bytes
The system can be language independent! 用二进制来表示语言

根据19年的论文统计:Go through more than 100 papers in INTERSPEECH’19, ICASSP’19, ASRU’19

常见语言识别应用




接下来看语音识别的输出部分
Acoustic Feature
我们通常会把声音表示为长度为T,维度为d的特征向量
下面看这个表示是怎么来的,假设有一段声音信号如下图所示,我们用一个大小为25毫秒的窗口对其进行扫描,得到
一个frame的向量表示,这个计算frame向量的方法有三种:
400 sample points (16KHz)直接做采样,得到400维结果
39-dim MFCC:一种老的算法,得到39维向量
80-dim filter bank output:结果是80维向量
以上后面两种算法自行百度,这里不展开。

每个窗口之间间隔是10ms,1秒钟就会有100个frame向量

下面看一下特征的抽取大概步骤:
第一步先经过离散傅里叶变换(Discrete Fourier Transform) 得到时谱图,时谱图在之前的课程有介绍,这个东东和语音识别关系非常强,甚至人经过训练可以直接从时谱图中读出发音;
第二步,时谱图经过filter bank(前辈们已经设计好的)得到一组数据,然后经过log(这个不可省略)然后经过离散余弦变换(discrete cosine transform, DCT)得到MFCC特征表示。

这里的每个阶段的产物都可以用来做语音辨识。具体应用情况为:

语音识别的两种模型
Seq-to-seq

HMM

HMM是课外学习内容
seq2seq则具体介绍5个模型
• Listen, Attend, and Spell (LAS)
• Connectionist Temporal Classification (CTC)
• RNN Transducer (RNN-T)
• Neural Transducer
• Monotonic Chunkwise Attention (MoChA)
当前趋势:

















 7328
7328











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











