







文章目录
介绍
本门课程是2020年李宏毅老师新课:Deep Learning for Human Language Processing(深度学习与人类语言处理)
课程网站
B站视频
公式输入请参考:在线Latex公式
本节课程讲的内容属于:
Related Tasks
情感识别:Emotion Recognition
声音事件识别:安保系统,不装摄像头,可以保护隐私
自闭症识别:Autism Recognition
关键字识别:Keyword Spotting

本节只讲Speaker Verification这个任务。
Task Introduction
• Speaker Recognition / Identification:语者识别,判断一段语音是谁说的。多分类任务

• Speaker Verification:语者验证,判断两段语音是不是同一个人说的。比对相似度,银行会用这个算法验证人的身份
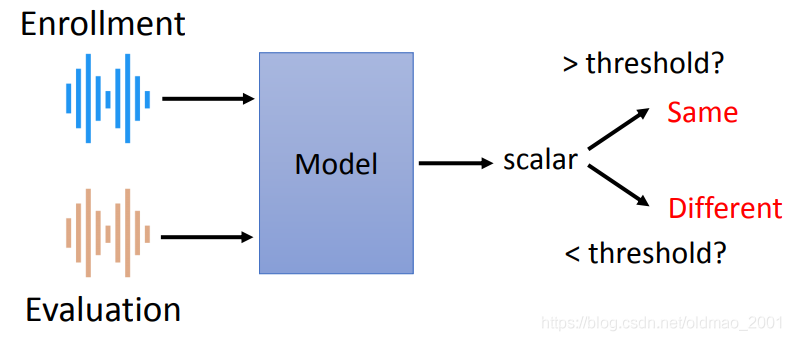
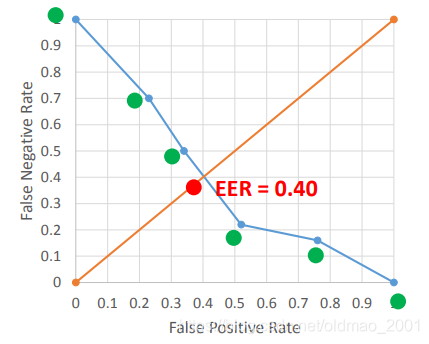
这里衡量判别的效果通常使用:Equal Error Rate (EER)
False Negative (FN) Rate:同一语者被判断为不同语者的比例
False Positive (FP) Rate:不同语者被判断为同一语者的比例
当threshold为1的时候,无论什么声音都会被判别为不同语者,因此FN为100%而FP为0
当threshold为0的时候,无论什么声音都会被判别为相同语者,因此FN为0而FP为100%
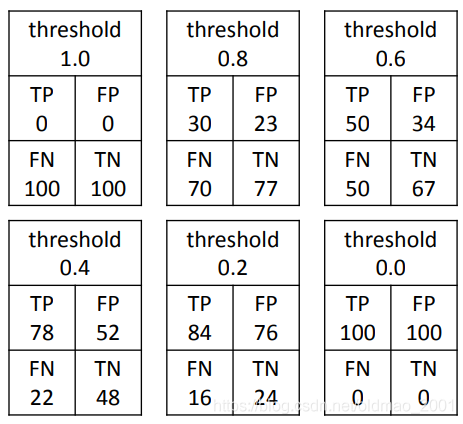
调整threshold,两个指标会互为消长,然后要找出它们相交的地方的threshold,这里的FN=FP,就称为Equal Error Rate (EER)
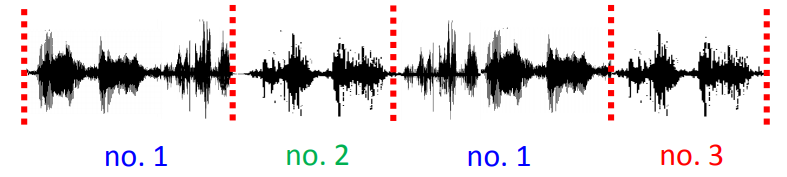
• Speaker Diarization:语者分段标记,判断在一段声音中,谁在什么时候说话。
diarize: to write down your future arrangements, meetings, etc. in a diary
例如我们有一段很长的录音(会议录音或者电话录音等)

先对这段声音进行分段(按句分或者按段落分):

然后对分段的语音进行聚类:(The number of speakers can be known or unknown.客服一般是两个人,会议就是人数不对)
本节课主要关注第二类任务。
Speaker Embedding
上讲过Speaker Verification的大概模型如下图所示:
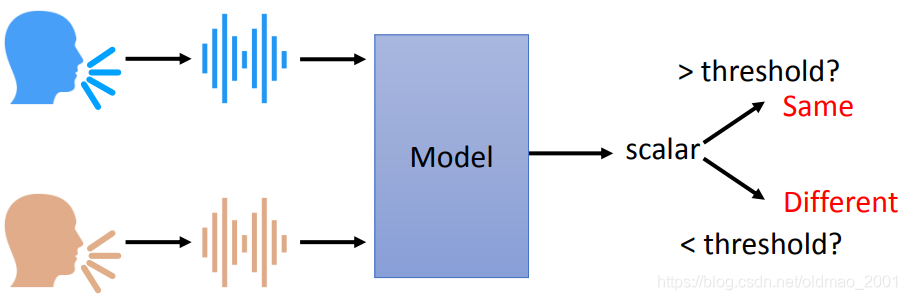
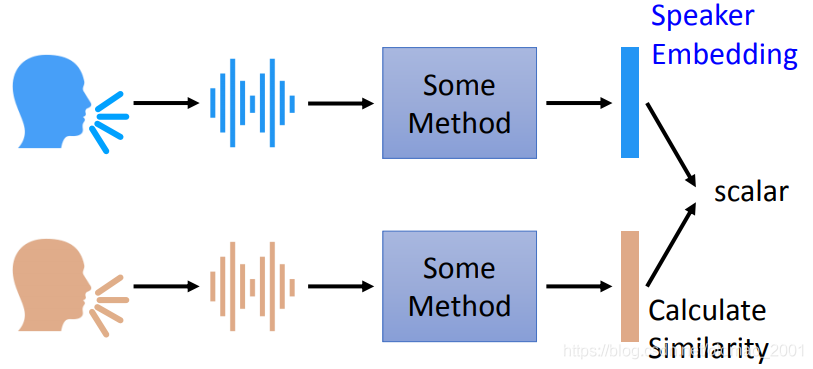
具体来说,模型要使用某种方法抽取出语者特征,忽略说话的内容,得到一个向量,然后比较两个语音的向量的相似度。
Framework
整个框架分三个部分。
Stage 1: Development,找出获取speaker embedding的方法,先收集一个语料库,里面包含很多人说话的声音。然后训练一个模型,可以将某段声音表示为embedding。
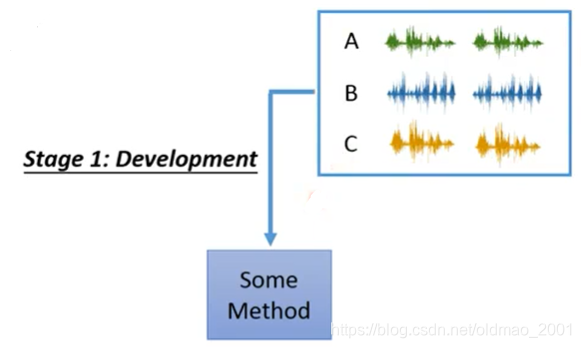
Stage 2: Enrollment 将要验证的语者的声音样本录入系统,如果录入多个声音样本,则对多个embedding结果求平均。
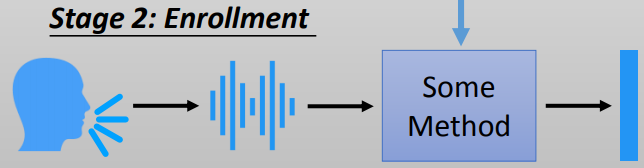
Stage 3: Evaluation 验证阶段,将要比对的声音样本通过模型得到embedding表示,然后和注册库中的embedding进行相似度比较。
这里注意:用于训练模型的语料库中的声音不会出现在注册和验证阶段
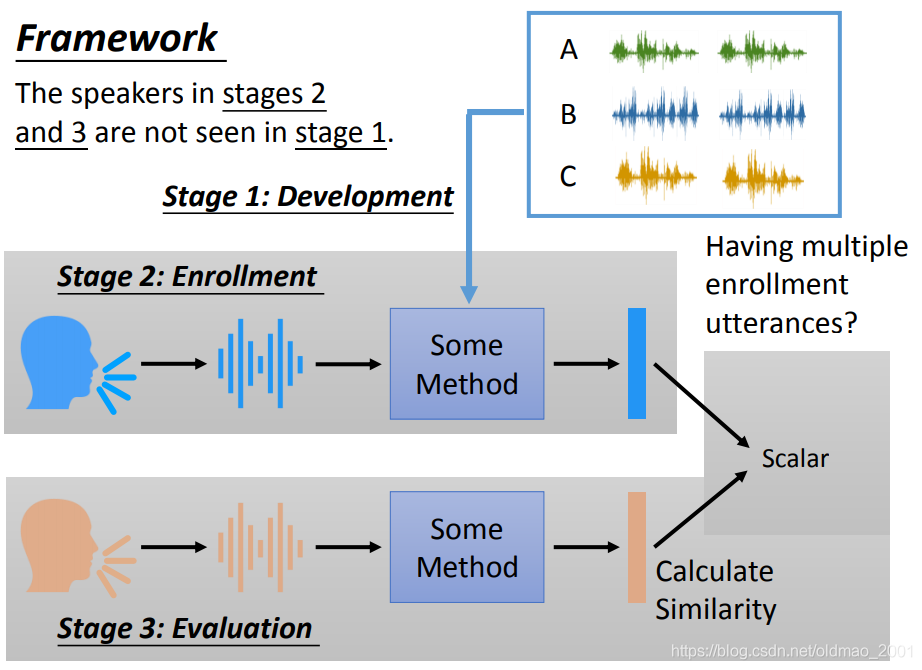
这个和老师之前讲的Metric-based meta learning是一样的,具体看这里
Stage 1: Development
这里单独讲下Stage 1: Development在实作的过程中用到的语料大小:
• Google’s Dataset (private)
36M utterances, 18000 speakers
• VoxCeleb
0.15M utterances, 1251 speakers
• VoxCeleb2
1.12M utterances, 6112 speakers
下面来看看如何抽取语音中的与内容无关的embedding表示。
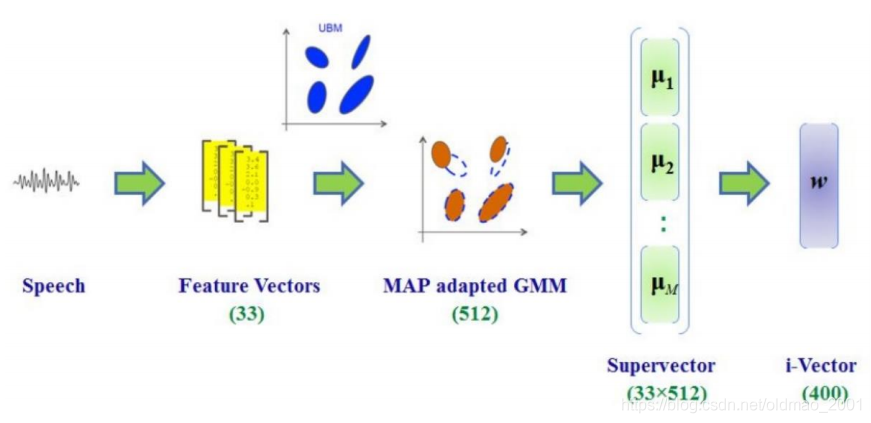
i-vector
“i” means “identity”
这是一种早期的抽取语音embedding表示的方法,这个方法得到的是一个400维的向量,与输入声音长度没有关系。是一个非DL的方法。
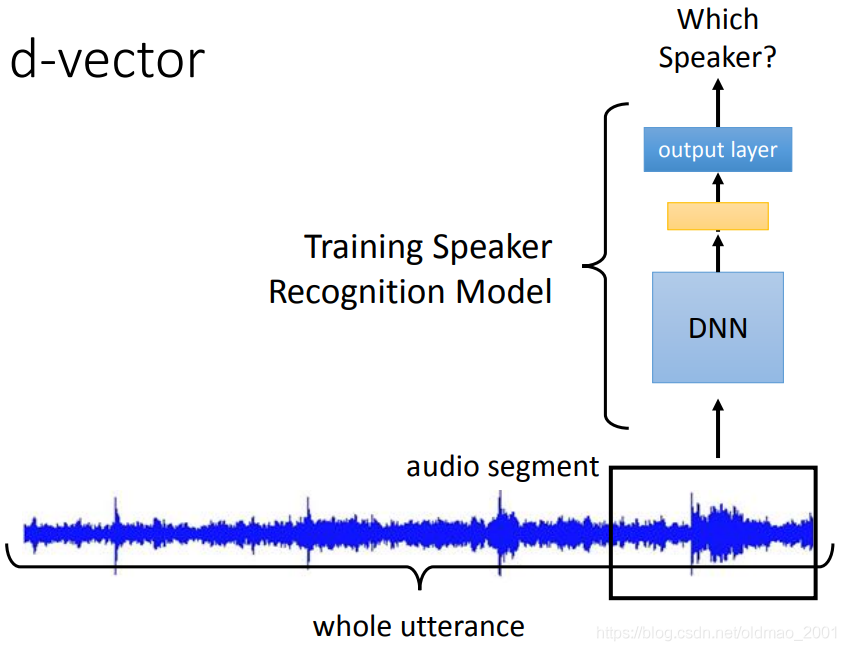
d-vector
d代表DL,先将声音信号截取一段audio segment,然后丢到DNN中,DNN只能吃固定长度的输入。

训练按Training Speaker Recognition Model进行训练,然后用最后一个隐藏层的输出(黄色)作为语音的embedding。为什么不用最后输出层的结果呢,因为那个结果是和语者数量有关,例如有5000个人的声音,那么就会有5000维大小的向量出来。
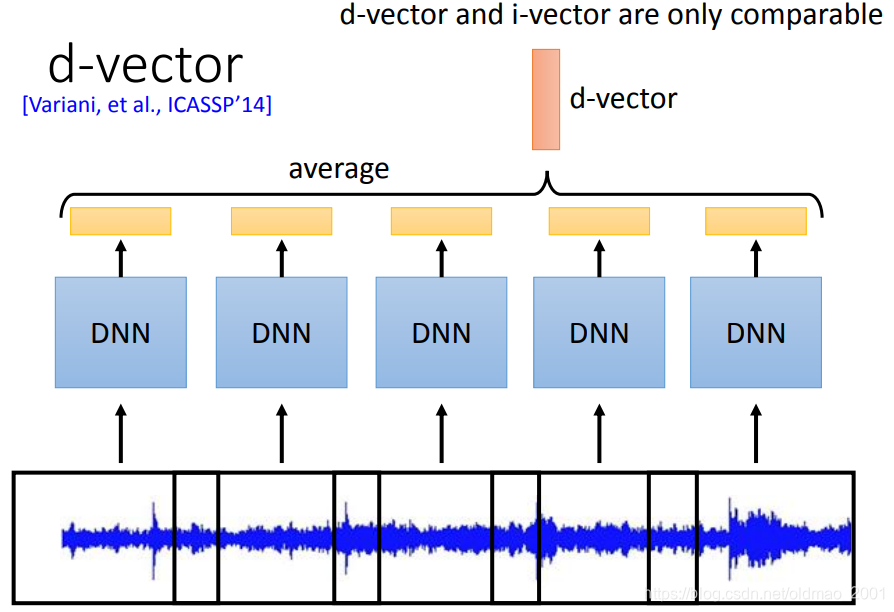
如果是要对整个句子进行抽取就可以对每个segment(可以重叠)进行DNN操作,最后结果求平均就得到d-vector。
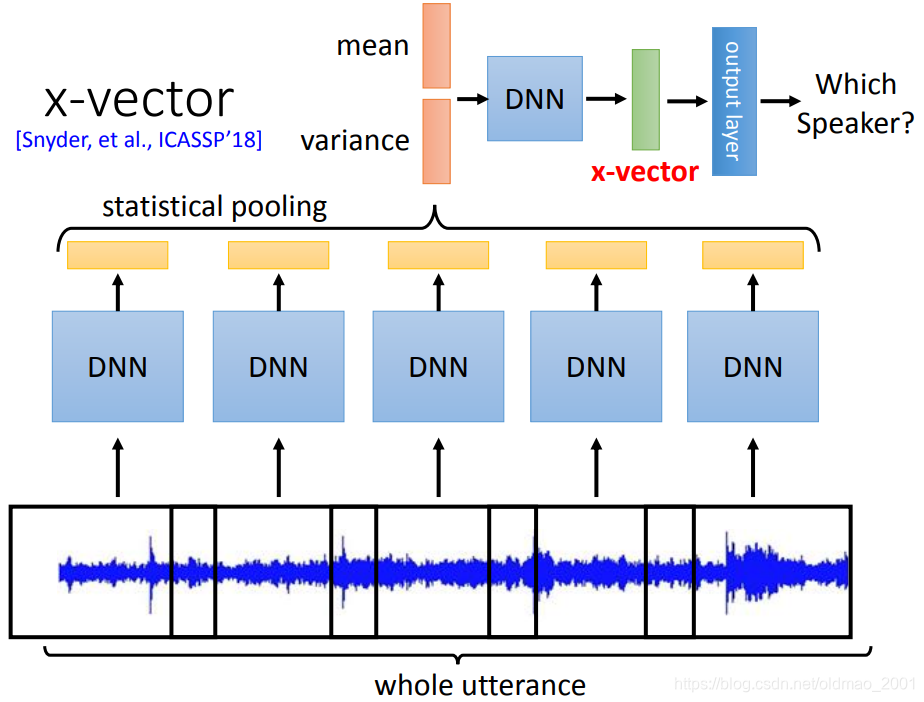
x-vector
前面的步骤都差不多,就是最后是把每个segment(可以重叠)进行DNN操作得到的结果的求得mean和variance,再经过DNN,经过输出层得到最后结果,这里也是抽最后一个隐藏层的输出作为x-vector。
这个算法的思路对于d-vector而言,是看完整个语音句子进行的训练,全局性更好。
Attention Mechanism
思路是在d-vector的基础上,不要直接做average,而是引入注意力机制,做加权求和。
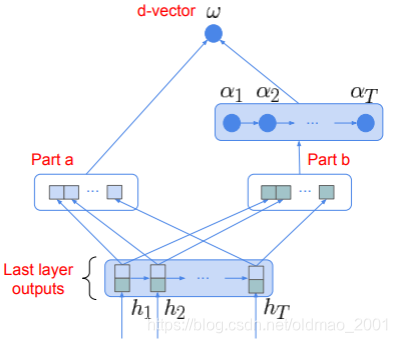
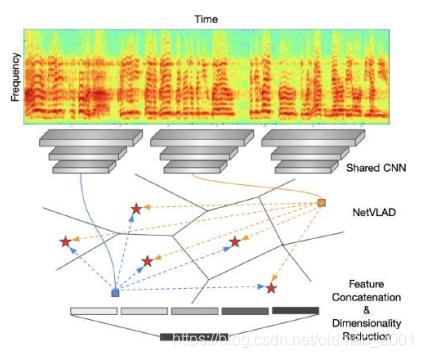
NetVLAD
VLAD = Vector of Locally Aggregated Descriptors
这个算法的思想是将语音中(尤其是长语音)不属于语者说话的声音部分去除掉,例如噪音,停顿等。
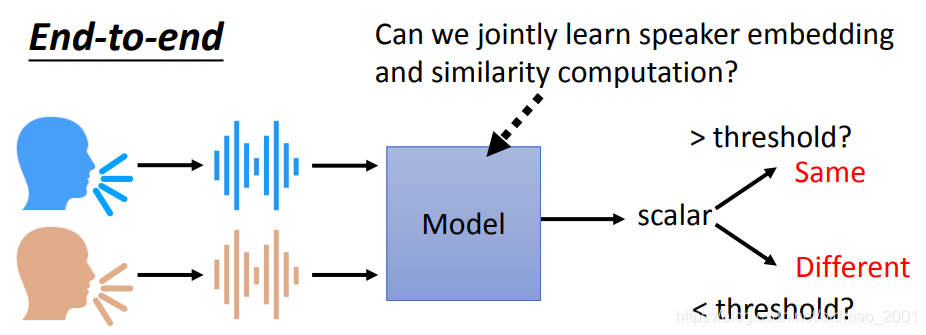
End-to-end
就是想要把获取语音embedding,以及比较相似度两个事情串在一起做掉
这里准备数据有点像做字迹识别,就是取同一个人的语音作为正样本对:
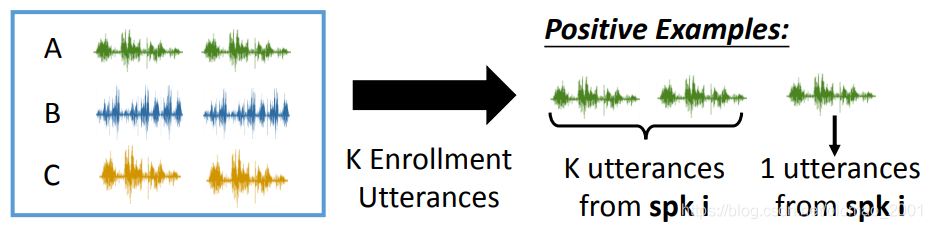
不同人的语音作为负样本对:
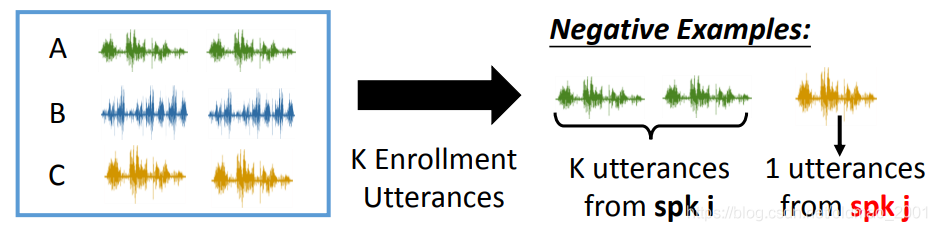
这里还提到一个方法:
GE2E [Wan, et al., ICASSP’18]
整个End-to-end构架如图所示,这里要把注册的语音(同一个人)的embedding求平均后再进行相似度计算。
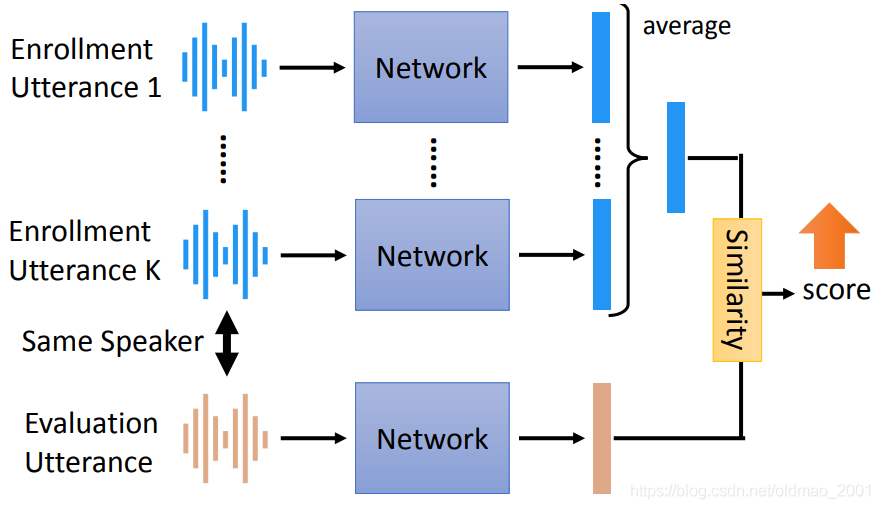
可以看到,上面的模型将抽取语音embedding和相似度计算都包含起来了,可以一起训练。
这里的End-to-end方法还分两种:
Text-dependent v.s. Text-independent
上面那种其实是Text-dependent的
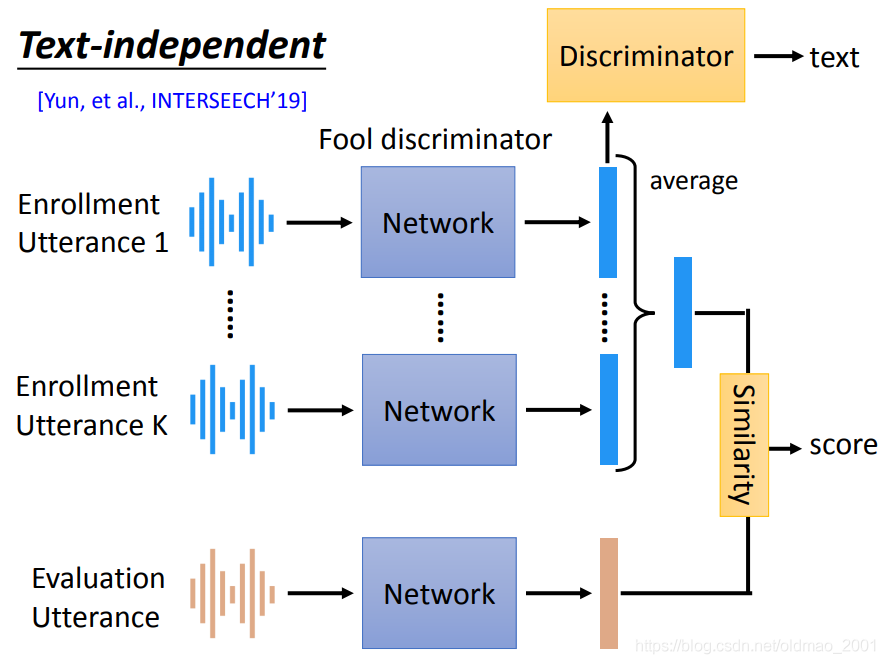
Text-independent
实际上和前面讲过的语音识别技术非常类似,就是加入一个Discriminator,用于分辨文字信息,而蓝色的模型就是要骗过Discriminator,训练完成后,Discriminator就会自然的过滤掉文字信息,从而达到骗过Discriminator的目的。
















 6063
6063











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











