







目录
前言
本课程来自深度之眼《多模态》训练营,部分截图来自课程视频。
文章标题:Image Captioning with Semantic Attention
神经图像描述生成
作者:Quanzeng You等
单位:罗切斯特大学+Adobe研究中心
发表时间:2016 CVPR
Latex 公式编辑器
泛读
摘要
Automatically generating a natural language description of an image has attracted interests recently both because of its importance in practical applications and because it connects two major artificial intelligence fields: computer vision and natural language processing.
第一句先讲Image Caption任务的难度与重要性
Existing approaches are either top-down, which start from a gist of an image and convert it into words, or bottom-up, which come up with words describing various aspects of an image and then combine them.
第二句讲现有的方法,当时的image caption的模式有两种:
top-down,将图片直接转化为词,优点是端到端,缺点是难以提取细节
bottom-up,先用几个词描述图片的各个方面,然后将词组合到一起,优点是可以提取细节,缺点是没有端到端的formulatio
In this paper, we propose a new algorithm that combines both approaches through a model of semantic attention. Our algorithm learns to selectively attend to semantic concept proposals and fuse them into hidden states and outputs of recurrent neural networks. The selection and fusion form a feedback connecting the top-down and bottom-up computation.
结合当前研究的优点,提出了一个semantic attention model,该算法学习选择性地注意语义概念建议,并将其融合到隐藏状态和递归神经网络的输出中。选择和融合形成连接自上而下和自下而上计算的反馈。
We evaluate our algorithm on two public benchmarks: Microsoft COCO and Flickr30K. Experimental results show that our algorithm significantly outperforms the state-of-the-art approaches consistently across different evaluation metrics.
最后讲效果:我们根据两个公开的基准评估我们的算法:Microsoft COCO和Flickr30K。实验结果表明,在不同的评估指标上,我们的算法明显优于最新方法。
Introduction
自动生成图像的自然语言描述,也称为图像说明,最近在计算机视觉领域受到了很多关注。这个问题之所以有趣,不仅是因为它有重要的实际应用,比如帮助视障人士看东西,而且还因为它被认为是图像理解的一个巨大挑战,而图像理解是计算机视觉的一个核心问题。生成一个有意义的图像自然语言描述需要一个远远超过图像分类和物体检测的图像理解水平。这个问题也很有趣,因为它将计算机视觉和自然语言处理联系在一起,这是人工智能的两个主要领域。
现有的图像说明任务有两种方法/范式:自顶向下和自底向上。自上而下的范式从图像的“要点”开始并将其转换为单词,而自下而上的范例首先提出描述图像各个方面的单词,然后将它们组合起来。在两种范式中都使用语言模型来形成连贯的句子。现有的SOTA技术是自上而下的范式,其中基于递归神经网络从图像到句子都有端到端的表述,并且可以从训练数据中学习递归网络的所有参数。但其局限性之一是很难关注细节,这对于描述图像可能很重要。自下而上的方法虽然可以在任何图像分辨率下自由操作,但不适合端到端的训练。
视觉注意[17, 30]是灵长类动物和人类视觉系统中的一个重要机制。它是一个反馈过程,将视觉皮层早期阶段的表征选择性地映射到一个更中心的非拓扑表征中,该表征只包含场景中特定区域或物体的属性。这种选择性的映射允许大脑在低层次图像特性的指导下,一次将计算资源集中在一个物体上。视觉注意力机制在偏向语义的图像自然语言描述中也发挥了重要作用。特别是,人们不会描述图像中的一切。相反,他们更倾向于谈论图像中语义上更重要的区域和物体。
我们提出了一种新的图像说明方法(框架见下图),通过语义注意模型将自上而下和自下而上的方法结合起来。我们对图像说明中语义注意力的定义是,能够在需要时准确地对语义上重要的对象进行详细、连贯的描述。我们的语义注意模型具有以下属性。
1)能够关注图像中的一个语义上重要的概念或感兴趣的区域
2)能够对多个概念所付出的注意力的相对强度进行加权
3)能够根据任务状态在概念之间动态地切换注意力。
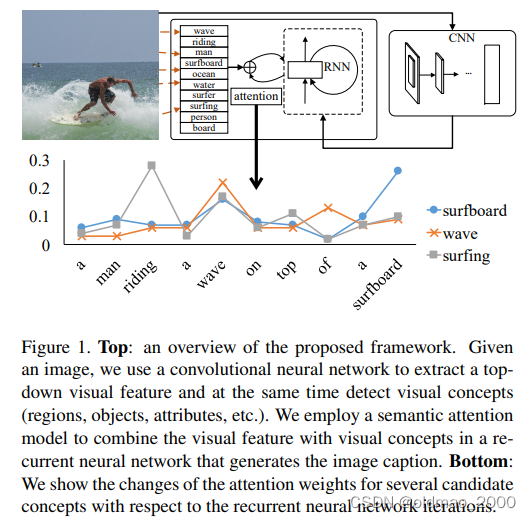
具体来说,我们使用自下而上的方法检测语义概念或属性作为注意力的候选者,并采用自上而下的视觉特征来指导注意力应该在何处和何时被激活。我们的模型建立在一个循环神经网络(RNN)之上,其初始状态捕捉来自自上而下特征的全局信息(就是初始化是吃全局的feature map)。随着RNN状态的转变,它通过对网络状态和输出节点强制执行的注意机制,从自下而上的属性中获得反馈和互动。这种反馈使该算法不仅能更准确地预测新词,还能导致对现有预测和图像内容之间的语义差距进行更有力的推断。
创新/贡献点
文的主要贡献是提出一种新的图像捕捉算法,该算法是基于一种新的语义注意力模型。我们的注意力模型在递归神经网络的框架内自然地结合了自上而下和自下而上两种方法的视觉信息。与最先进的方法相比,我们的算法产生了明显更好的性能。例如,在COCO和Flickr30K我们的算法在不同的评价指标上都比其他竞争者的方法要好(Bleu-1,2,3,4, Meteor, 和Cider)。我们还额外研究比较不同的属性检测器(attribute detectors)和注意力方案。
需要注意的是,文献[36](其实就是上一篇《Show, attend and tell》)也考虑了使用注意力来为图像加注说明。本文的工作和[36]之间有几个重要的区别。
首先,在[36]中,注意力是在一个固定的分辨率下进行空间建模的。在每一次循环迭代中,算法都会计算一组与预先定义的空间位置相对应的注意力权重。相反,我们可以使用来自图像中任何分辨率的任何地方的概念。事实上,我们甚至可以使用那些在图像中没有直接视觉存在的概念。
第二,在我们的工作中,有一个反馈过程,将自上而下的信息(全局视觉特征)与自下而上的概念相结合,这在[36]中并不存在。
第三,在[36]中使用了在特定空间位置的预训练的特征。相反,我们使用与检测到的视觉概念相对应的词语特征。这样,我们可以利用外部图像数据来训练视觉概念,利用外部文本数据来学习单词之间的语义。
Related Work
关于图像标题的文献越来越多,一般可分为两类:自上而下和自下而上。
自下而上的方法是 "经典 "的方法,它从视觉概念、对象、属性、单词和短语开始,并使用语言模型将它们组合成语句。[12]和[19]检测概念并使用模板获得句子,而[23]将检测到的概念拼凑起来。[9]和[20]使用更强大的语言模型。[11]和[22]是沿着这个方向的最新尝试,它们在各种图像caption的基准上取得了接近最先进的性能。
自上而下的方法是 较为先进的方法,它将图像caption作为一个机器翻译问题[31, 2, 5]。这些方法不是在不同的语言之间进行翻译,而是将图片表征翻译成语言。图片表征来自卷积神经网络,该网络通常在大规模数据集上为图像分类进行了预训练[18]。翻译是通过基于递归神经网络的语言模型完成的。这种方法的主要优点是整个系统可以端到端进行训练,也就是说,所有的参数都可以从数据中学习。代表性的工作包括[35,26,16,8,36,25]。各种方法的不同之处往往在于使用什么样的递归神经网络。自上而下的方法代表了这个问题的最先进水平。
视觉注意力在心理学和神经科学中早已为人所知,但最近才在计算机视觉和相关领域得到研究。在模型方面,[21, 33]用玻尔兹曼机进行处理,而[28]用递归神经网络进行处理。在应用方面,[6]研究它用于图像跟踪,[1]研究它用于多个物体的图像识别,而[15]则用于图像生成。最后,正如我们在第1节中所讨论的,我们并不是第一个考虑将注意力机制其用于图像caption的人。在[36]中,Xu等人提出了一个用于图像caption的空间注意力模型。
精读
我们从输入图像中提取自上而下和自下而上的特征。首先,我们使用卷积神经网络(CNN)分类的中间滤波器响应来建立一个全局视觉描述(表示为 v v v)。此外,我们运行一组属性检测器来获得最有可能出现在图像中的视觉属性或概念列表(表示为 { A i } \{A_i\} {Ai})。每个属性/概念 A i A_i Ai对应字典 Y \mathcal{Y} Y中的一个条目。属性检测器的设计将在第 4 节中讨论。
所有视觉特征都被输入一个递归神经网络(RNN)来生成caption。由于隐藏状态
h
t
∈
R
n
h_t\in\mathbb{R}^n
ht∈Rn随时间
t
t
t 演变,caption中的第
t
t
t个词
Y
t
Y_t
Yt 是根据概率向量
p
t
∈
R
∣
Y
∣
p_t\in\mathbb{R}^{|\mathcal{Y}|}
pt∈R∣Y∣由状态
h
t
h_t
ht 控制。生成的单词
Y
t
Y_t
Yt 将在下一个时间步反馈回 RNN(相当于当前时间步要吃上一步的输出)。作为网络输入的一部分
x
t
+
1
∈
R
m
x_{t+1}\in\mathbb{R}^m
xt+1∈Rm, 这将推动状态从
h
t
h_t
ht过渡到
h
t
+
1
h_{t+1}
ht+1。来自 来自
v
v
v和
{
A
i
}
\{A_i\}
{Ai}的视觉信息作为外部 的视觉信息,作为 RNN 生成
x
t
x_t
xt和
p
t
p_t
pt的外部指南。由输入和输出模型
φ
φ
φ 和
ϕ
ϕ
ϕ 指定。整个模型结构如图所示:
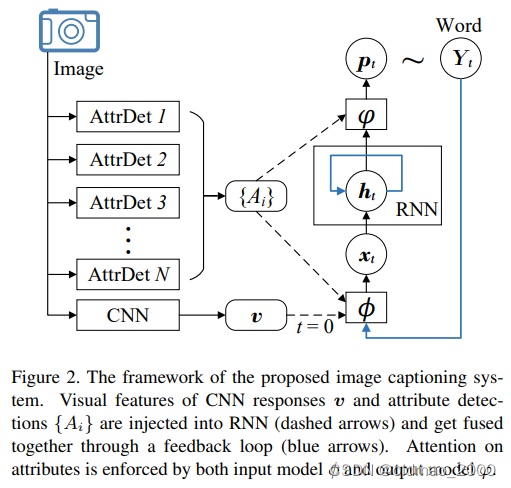
与之前研究不同,我们的模型使用一种独特的方法来利用和结合不同的视觉信息源。CNN提取的图像特征
v
v
v只在初始输入节点
x
0
x_0
x0中使用,这可以让 RNN快速了解图像全局内容。一旦 RNN 状态被初始化为包含整体/全局图片内容,它就能在随后的时间步骤中从
{
A
i
}
\{A_i\}
{Ai}中选择与任务相关的特定项目进行处理。具体来说,我们系统的主要工作流程受以下公式控制:
x
0
=
ϕ
0
(
v
)
=
W
x
,
v
v
h
t
=
RNN
(
h
t
−
1
,
x
t
)
Y
t
∼
p
t
=
φ
(
h
t
,
{
A
i
}
)
x
t
=
ϕ
(
Y
t
−
1
,
{
A
i
}
)
,
t
>
0
\begin{aligned}x_0&=\phi_0(v)=W^{x,v}v\\ h_t&=\text{RNN}(h_{t-1},x_t)\\ Y_t&\sim p_t=\varphi(h_t,\{A_i\})\\ x_t&=\phi(Y_{t-1},\{A_i\}),t>0\end{aligned}
x0htYtxt=ϕ0(v)=Wx,vv=RNN(ht−1,xt)∼pt=φ(ht,{Ai})=ϕ(Yt−1,{Ai}),t>0
公式1表示使用
W
x
,
v
W^{x,v}
Wx,v进行线性变换,这里为了简便省略了偏置项。
式(3)和式(4)中的输入和输出注意模型旨在根据当前模型状态自适应地注意 {Ai} 中的某些认知线索,从而使提取的视觉信息与现有单词的解析和未来单词的预测最为相关。
公式 (2) 至 (4) 是递归应用,通过这些公式,被关注的属性被反馈到隐藏层状态
h
t
h_t
ht,并与来自
v
v
v的全局信息相整合。
输入的注意力模型
针对输入的注意力模型
ϕ
\phi
ϕ:
x
t
=
ϕ
(
Y
t
−
1
,
{
A
i
}
)
,
t
>
0
x_t=\phi(Y_{t-1},\{A_i\}),t>0
xt=ϕ(Yt−1,{Ai}),t>0
要根据属性
{
A
i
}
\{A_i\}
{Ai}和上一个预测值
Y
t
−
1
Y_{t-1}
Yt−1来计算在
t
t
t时刻每一个属性的得分
α
t
i
\alpha_t^i
αti,
{
A
i
}
\{A_i\}
{Ai}和
Y
t
−
1
Y_{t-1}
Yt−1都对应属性字典
Y
\mathcal{Y}
Y中的一个条目,都可以表示为
R
∣
Y
∣
\mathbb{R}^{|\mathcal{Y}|}
R∣Y∣空间中的独热向量(这里分别用
y
i
y^i
yi和
y
t
−
1
y_{t-1}
yt−1表示)。
作为在矢量空间中建立相关性模型的一种常见方法,这里使用双线性函数来计算
α
t
i
\alpha_t^i
αti。
α
t
i
∝
exp
(
y
t
−
1
T
U
~
y
i
)
\alpha_t^i\propto \exp (y^T_{t-1}\tilde U y^i)
αti∝exp(yt−1TU~yi)
exp指数相当于使用softmax对
{
A
i
}
\{A_i\}
{Ai}进行归一化操作。
矩阵
U
~
∈
R
∣
Y
∣
×
∣
Y
∣
\tilde U\in\mathbb{R}^{|\mathcal{Y}|\times |\mathcal{Y}|}
U~∈R∣Y∣×∣Y∣由于词表size较大,因此其包含的参数量也较大,size×size个。
因此为了减少参数量,可以对两个独热编码投影到低维空间(使用Word2Vec或Glove都可以),上式变成:
α
t
i
∝
exp
(
y
t
−
1
T
E
T
U
E
y
i
)
\alpha_t^i\propto \exp (y^T_{t-1}E^TU Ey^i)
αti∝exp(yt−1TETUEyi)
其中表征矩阵
E
∈
R
d
×
∣
Y
∣
E\in\mathbb{R}^{d\times|\mathcal{Y}|}
E∈Rd×∣Y∣,
d
≪
∣
Y
∣
d\ll |\mathcal{Y}|
d≪∣Y∣
U
U
U则是
d
×
d
d\times d
d×d的方阵。
α
t
i
\alpha_t^i
αti将作为输入attention来调节各个属性的重要性,并映射到输入空间,因此输入可以表示为:
x
t
=
W
x
,
Y
(
E
y
t
−
1
+
diag
(
w
x
,
A
)
∑
i
α
t
i
E
y
i
)
x_t=W^{x,Y}(Ey_{t-1}+\text{diag}(w^{x,A})\sum_i\alpha_t^iEy^i)
xt=Wx,Y(Eyt−1+diag(wx,A)i∑αtiEyi)
其中投影矩阵
W
x
,
Y
∈
R
m
×
d
W^{x,Y}\in\mathbb{R}^{m\times d}
Wx,Y∈Rm×d,
diag
(
w
)
\text{diag}(w)
diag(w)表示以向量
w
w
w为对角线元素构成的对角矩阵
∑
i
α
t
i
E
y
i
\sum_i\alpha_t^iEy^i
∑iαtiEyi表示各个属性上的注意力加权,再乘以
diag
(
w
)
\text{diag}(w)
diag(w)表示各个维度上的注意力加权。
输出的注意力模型
输出的注意力模型
φ
\varphi
φ与 输入的注意力模型设计理念差不多。但是,由于在分析和合成一个句子的过程中,视觉属性/概念可能以不同的顺序被关注,因此需要计算一组不同的注意力分数。当前状态
h
t
h_t
ht 包含了对预测
Y
t
Y_t
Yt 有用的所有信息,因此每个属性
A
i
A_i
Ai 的分数
β
t
i
\beta_t^i
βti都是根据
h
t
h_t
ht 来测量的:
β
t
i
∝
exp
(
h
t
T
V
σ
(
E
y
i
)
)
\beta_t^i\propto\exp(h_t^TV\sigma(Ey^i))
βti∝exp(htTVσ(Eyi))
二元参数矩阵
V
∈
R
n
×
d
V\in\mathbb{R}^{n\times d}
V∈Rn×d,可以理解为V建立了隐状态
h
t
h_t
ht与单词表征之间的相关性。
σ
\sigma
σ是连接RNN的输入节点到隐藏层的激活函数,它可保证两个特征向量在比较前应用的非线性变化相同。或者说,因为
h
t
h_t
ht 输出的时候经历了一个非线性变换,因此这里也要加入激活函数
σ
\sigma
σ来对
E
y
i
Ey^i
Eyi进行同样的变换。
由于加入了随时间变化的
h
t
h_t
ht,所以
β
t
i
\beta_t^i
βti跟
α
t
i
\alpha_t^i
αti不一样。在不同位置的同一单词对下一个单词的
β
t
i
\beta_t^i
βti是会变化的。
原文提到,
{
β
t
i
}
\{\beta_t^i\}
{βti}用来模块化所有视觉属性/概念的注意力,它通过激活函数后的加权求和与
h
t
h_t
ht一起来生成概率分布
p
t
p_t
pt:
p
t
∝
(
E
T
W
Y
,
h
(
h
t
+
diag
(
w
Y
,
A
)
∑
i
β
t
i
σ
(
E
y
i
)
)
)
p_t\propto(E^TW^{Y,h}(h_t+\text{diag}(w^{Y,A})\sum_i\beta_t^i\sigma(Ey^i)))
pt∝(ETWY,h(ht+diag(wY,A)i∑βtiσ(Eyi)))
其中,
W
Y
,
h
∈
R
d
×
n
W^{Y,h}\in\mathbb{R}^{d\times n}
WY,h∈Rd×n是投影矩阵;
w
Y
,
A
∈
R
n
w^{Y,A}\in\mathbb{R}^n
wY,A∈Rn用于建模每个RNN状态空间维度可视化属性/概念的重要性;
E
T
E^T
ET和上面提到的减少参数量的低维投影trick一样。
模型学习
训练数据的每一张图片由三部分组成:输入图片特征
v
v
v,
{
A
i
}
\{A_i\}
{Ai}和输出的caption词序列
{
Y
t
}
\{Y_t\}
{Yt}。
我们的目标为学习所有的注意力模型参数权重:
Θ
A
=
{
U
,
V
,
W
∗
,
∗
,
w
∗
,
∗
}
\Theta_A=\{U,V,W^{*,*},w^{*,*}\}
ΘA={U,V,W∗,∗,w∗,∗}
以及RNN参数:
Θ
R
\Theta_R
ΘR
并使得训练集对应的损失函数最小。
单个训练样本的损失值可定义为词的负对数似然和attention score的正则
化项组成:
min
Θ
A
Θ
R
−
∑
t
log
p
(
Y
t
)
+
g
(
α
)
+
g
(
β
)
\underset{\Theta_A\Theta_R}{\min}-\sum_t\log p(Y_t)+g(\alpha)+g(\beta)
ΘAΘRmin−t∑logp(Yt)+g(α)+g(β)
α
,
β
\alpha,\beta
α,β为attention score矩阵,其第
(
t
,
i
)
(t,i)
(t,i)个元素表示为:
α
t
i
,
β
t
i
\alpha_t^i,\beta_t^i
αti,βti
正则化函数
g
g
g是为了保证权重对于每个属性的完备性和对于不同时间的稀疏性,其定义如下:
g
(
α
)
=
∣
∣
α
∣
∣
1
,
p
+
∣
∣
α
T
∣
∣
q
,
1
=
[
∑
i
[
∑
t
α
t
i
]
p
]
1
/
p
+
[
∑
t
[
∑
i
α
t
i
]
q
]
1
/
q
g(\alpha)=||\alpha||_{1,p}+||\alpha^T||_{q,1}\\ =[\sum_i[\sum_t\alpha_t^i]^p]^{1/p}+[\sum_t[\sum_i\alpha_t^i]^q]^{1/q}
g(α)=∣∣α∣∣1,p+∣∣αT∣∣q,1=[i∑[t∑αti]p]1/p+[t∑[i∑αti]q]1/q
视觉属性/概念预测
视觉属性
{
A
i
}
\{A_i\}
{Ai}预测在模型的训练和测试中非常重要,本文提出了了两种预测方法:非参数方法和参数方法。非参数方法基于的是最近邻算法,参数方法是预测使用深度神经网络预测属性标签。
首先,我们探索了一种基于近邻图像检索的非参数方法,该方法可从具有丰富和非结构化文本元数据(如标签和标题)的大型图像集合中检索图像。通过从检索到的具有相似视觉外观的图像中转移文本信息,可以获得查询图像的属性。第二种方法是使用参数模型直接预测输入图像的视觉属性。这是最近深度学习模型在视觉识别任务中取得成功[10, 18]的结果。属性检测所面临的独特挑战在于,图像中通常存在不止一个视觉概念,因此我们面临的是多标签(multi-label)问题,而不是多类别(multi-class)问题。需要注意的是,这两种获取属性的方法是互补的,可以联合使用。图 3 显示了一个使用不同方法预测图像视觉属性的例子:

非参数属性提取器
利用网上(社交媒体)的大量弱标签图片,基于的假设是相似的图片更可能共享相似的标注,使用最近邻算法, 用GoogleNet来度量图片间的距离,对于一个测试图片,搜索它的近邻然后计算每个词的TF来选择出现频率最高的词作为属性。
参数属性提取器
从训练集中找出出现频率最高的一些词,将它们作为label供神经网络学习,本文使用了当时最先进的一些属性提取的方法:使用ranking loss作为损失函数来学习多标签分类,使用全卷积网络(FCN)。
实验
| Metric | Datasets |
|---|---|
| BLEU Meteor Rough-L CIDEr | Flickr30k, 31, 783 张 MS-COCO,123, 287张 |
每个图片由不同的AMT给出至少5个标签。
作者测试了单独使用input或者output attention的效果,发现只使用一个的话只对模型只有少量的提升,但同时使用则有较大提升,说明两个具有比较强的协同作用。
而对于visual attributes的提取,作者发现使用FCN的效果是最好的。
对于attributes的使用,除了前面介绍的attention方法ATT,作者还测试了MAX(element-wise max)和CON(concatenate),效果都没有ATT好。
数据集划分参考了公开的划分方法。
caption使用的LSTM模型输入和隐藏层均为512维,激活函数为tanh,词向量使用了300维的Glove结果。
图片特征
v
v
v是从GoogleNet中提取出来的1024维向量。
在训练阶段,使用了RMSProp来更新loss,mini-batch大小为256,正则化项参数为:
p
=
2
,
q
=
0.5
p=2,q=0.5
p=2,q=0.5
MS-COCO的性能
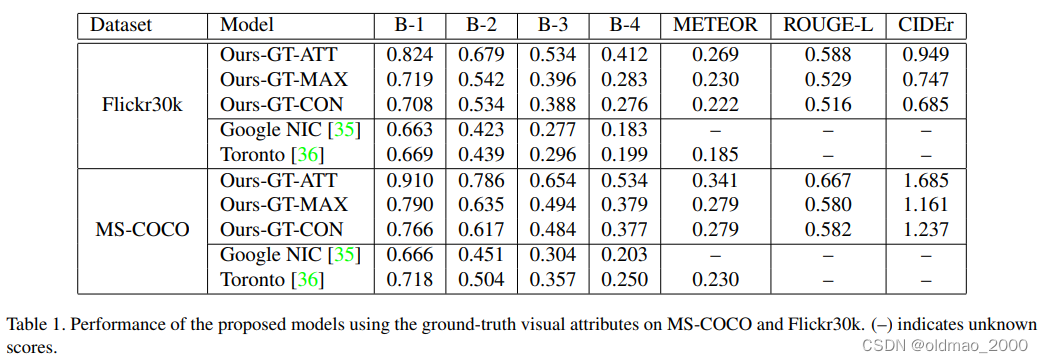
由于图片caption任务结果的好坏与视觉属性生成方法有关,因此,我们首先假设视觉属性标签已知,并评估了选择这些属性的不同方式(CON、MAX、ATT)。这将表明利用视觉属性进行字幕的性能极限。更具体地说,我们从字幕标签中选择最常见的单词作为视觉属性,以帮助生成字幕。表1显示了三个模型使用全局视觉属性标签的性能。这些结果可以被认为是所提出模型的上限,这表明如果给定高质量的视觉属性,所有所提出的模型(ATT、MAX和CON)都可以显著提高图像字幕系统的性能。现在,我们在属性检测和选择方面评估整个管道。表2的右半部分显示了所提出的模型在MS-COCO验证集上的性能。特别是,我们提出的注意力模型在大多数度量方面优于所有其他最先进的方法,这些方法通常用于公平和全面的绩效衡量。注意,B-1与单个单词的准确性有关,我们的模型和[36]之间的性能差距可能是由于单词词汇表的不同处理。
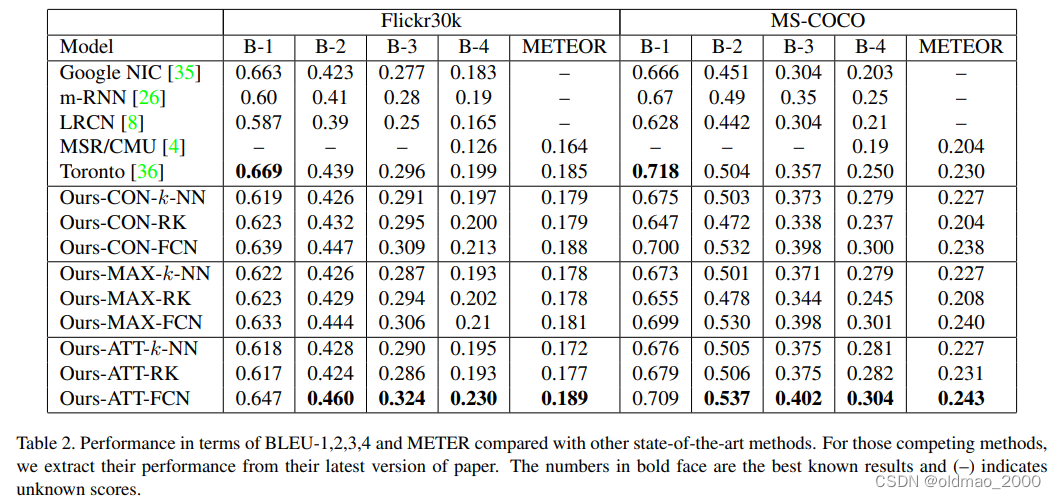
在表2中,前缀为“Ours”的条目显示了配置了属性检测和选择方法的不同组合的方法的性能。一般而言,在所有基准测试中,具有FCN模型预测属性的注意力模型ATT的性能优于其他组合。对于属性融合方法MAX和CON,我们发现使用前3个属性可以获得最佳性能。由于缺乏关注方案,过多的关键字可能会增加CON的参数,并可能会减少不同组关键字之间的差异。这两种模型的性能相当。结果表明,FCN提供了更稳健的视觉属性。
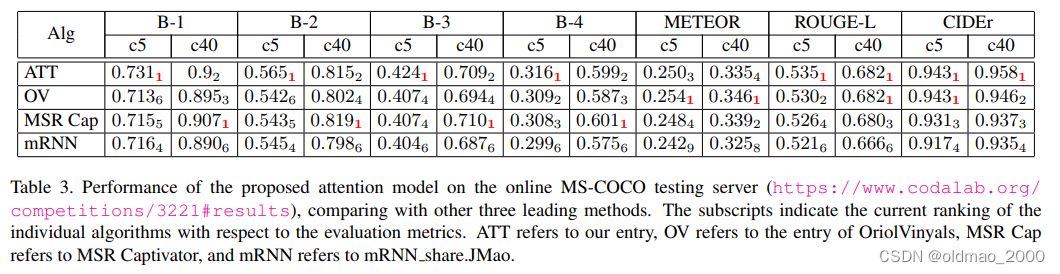
我们还通过将结果上传到官方测试服务器,在MS COCO Image Captaining Challenge集合c5和c40上评估了我们的最佳模型Ours ATT FCN。通过这种方式,我们可以将我们的方法与所有最先进的方法进行比较。尽管这场比赛很受欢迎,但在提交时,我们的方法在许多指标上都占据了前1的位置。表3列出了我们的模型和其他主要方法的性能。除了绝对分数,我们还提供了我们的模型在每个度量的所有竞争方法中的排名。通过与其他两种领先的方法进行比较,我们可以看到,我们的方法在不同的指标中实现了更好的排名。
Flickr30k的结果与COCO类似,这里不赘述。
实验分析
在某些指标上,使用输出注意力的表现略优于仅使用输入注意力。然而,这两种关注的结合在几乎每一个指标上都会提高性能几个百分点。这可以归因于这样一个事实,即输入层和输出层的注意力机制并不相同,并且它们都关注不同的视觉属性。因此,将它们结合起来可能有助于提供更丰富的上下文解释,从而提高性能。
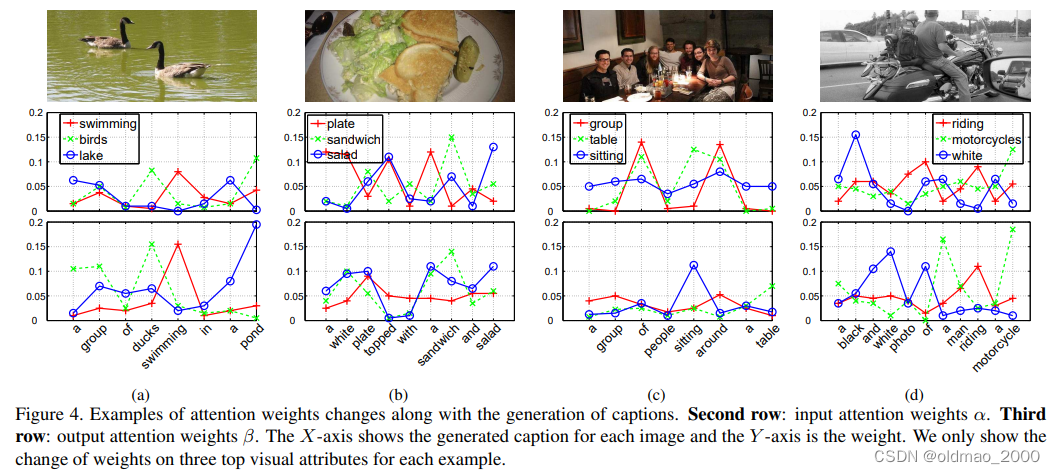

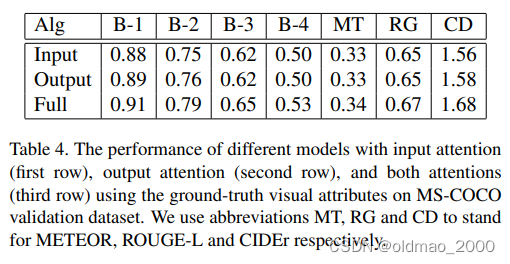
表4是消融实验,对输入和输出注意力机制进行消融。
Conclusion
在这项工作中,我们提出了一种新的图像caption任务方法,该方法在流行的标准基准上实现了最先进的性能。与以前的工作不同,我们的方法结合了自顶向下和自底向上的策略从动画中提取更丰富的信息,并将它们与RNN相结合,RNN可以选择性地处理从图像中检测到的丰富语义属性。因此,我们的方法不仅利用了输入图像的概况,还利用了丰富的细粒度视觉语义方面。我们模型的真正力量在于它能够关注这些方面,并无缝融合全球和本地信息以获得更好的caption。在接下来的步骤中,我们计划尝试基于短语的视觉属性及其分布式表示,并探索我们提出的语义注意机制的新模型。
















 632
632











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











