







 本次课介绍计算机视觉任务困难及典型模块结构,以Cifar - 10为例,讲解图像分类的两种朴素机器学习方法:最近邻和K近邻分类器、线性分类器。介绍了L1和L2距离,提及算法超参数设置方法,还指出线性分类器的限制,最后给出相关思考题。
本次课介绍计算机视觉任务困难及典型模块结构,以Cifar - 10为例,讲解图像分类的两种朴素机器学习方法:最近邻和K近邻分类器、线性分类器。介绍了L1和L2距离,提及算法超参数设置方法,还指出线性分类器的限制,最后给出相关思考题。
概述
本次课首先介绍了计算机视觉任务的困难所在;从宏观的角度设计了计算机视觉的典型模块结构;以Cifar-10为例,介绍了两种朴素的机器学习分类方法:最近邻分类器和K近邻分类器、线性分类器。
准备要搭实验环境,目前刚入门,还是先用免费的线上的弄弄
暂定Google Colab,使用的链接先Mark一下:Colab使用心得
里面还包含了如何在国内访问Google的方案,看了一下,貌似不是用的VPN,用的AWS的服务器,不知道是否稳定,求告知。
补充:
最后用的Google访问助手解决了,先下载谷歌访问助手,解压后文件后缀应该是crx。
然后打开浏览器,在设置里面找到扩展程序,把crx文件拖入浏览器即可,如果有报错提示,可以看看下面这个文章:
如何给Chrome添加插件
在线Latex公式
图像分类
image classification 是CV中的一个核心问题,其目的是把图片与语义信息(标签)对应起来,因此存在Semantic Gap。存在困难有很多(以识别猫咪为例):
1、同一个猫咪从不同角度拍摄,获得的图像不一样;
2、光照会使得图像的明暗度不一样;
3、不同动作的猫咪也不一样;
4、遮挡问题,例如只看到猫咪的尾巴;
5、猫咪与背景图像的相似会使得识别比较困难;
6、不同猫咪的种类,大小、颜色、年龄。对于识别也造成困难;
传统的通过判断的方式来解决这些问题是行不通的。实现这个的算法叫:Data-Driven Approach
数据驱动方法
偷懒贴上ppt的内容
Machine Learning: Data-Driven Approach
- Collect a dataset of images and labels
- Use Machine Learning to train a classifier
- Evaluate the classifier on new images
这里给出写代码的方法,就是先写出函数框架,然后再去具体实现,例如KNN分类器:
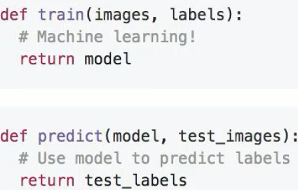
就是两个方法。
第一个算法:最近邻分类器
算法思想很简单,分两步:
1、Memorize all data and labels
2、Predict the label of the most similar training image
使用的数据集CIFAR10(西发ten),它包含:
10 classes
50,000 training images
10,000 testing images
计算相似度就需要就有一个度量相似度的东西,这里有提到L1和L2距离,这些概念在李航《统计学习方法》中有讲过。
L1距离
L1 distance:
d
1
(
I
1
,
I
2
)
=
∑
p
∣
I
1
p
−
I
2
p
∣
d_1(I_1,I_2)=\sum_{p}{\left | I_1^p-I_2^p \right |}
d1(I1,I2)=p∑∣I1p−I2p∣
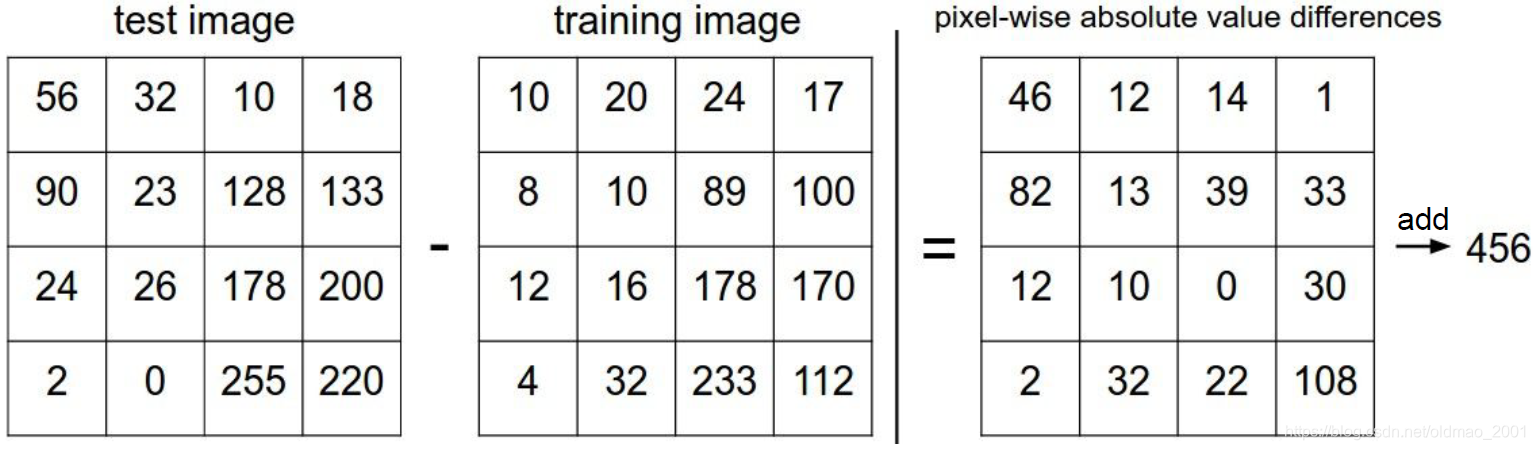
假设图像是4*4大小,以上就是L1距离(曼哈顿距离 Manhattan)计算。
算法的代码先偷懒直接贴图:
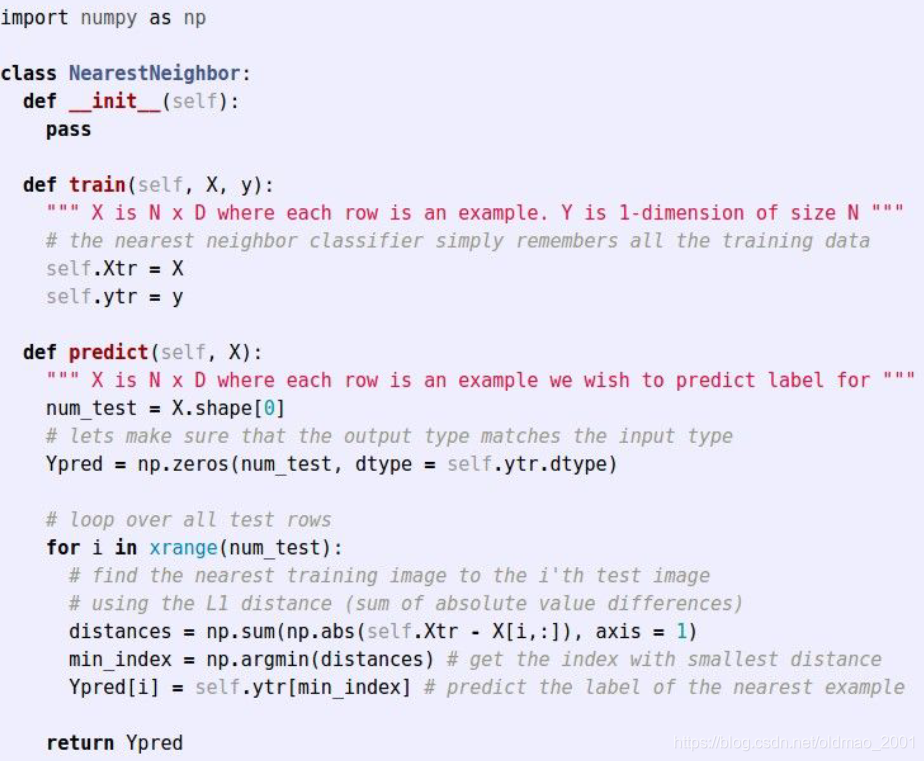
在train方法中,主要是记录训练数据集,这里其实就是一个指针指向里面的某一个图片
在predict方法里面,用L1距离去逐一比较所有训练数据集的图片,找到距离最小的图片,然后输出预测结果
可以看出来,这个算法有缺点:
Q: With N examples, how fast are training and prediction?
A: Train O(1), predict O(N)
This is bad: we want classifiers that are fast at prediction; slow for training is ok
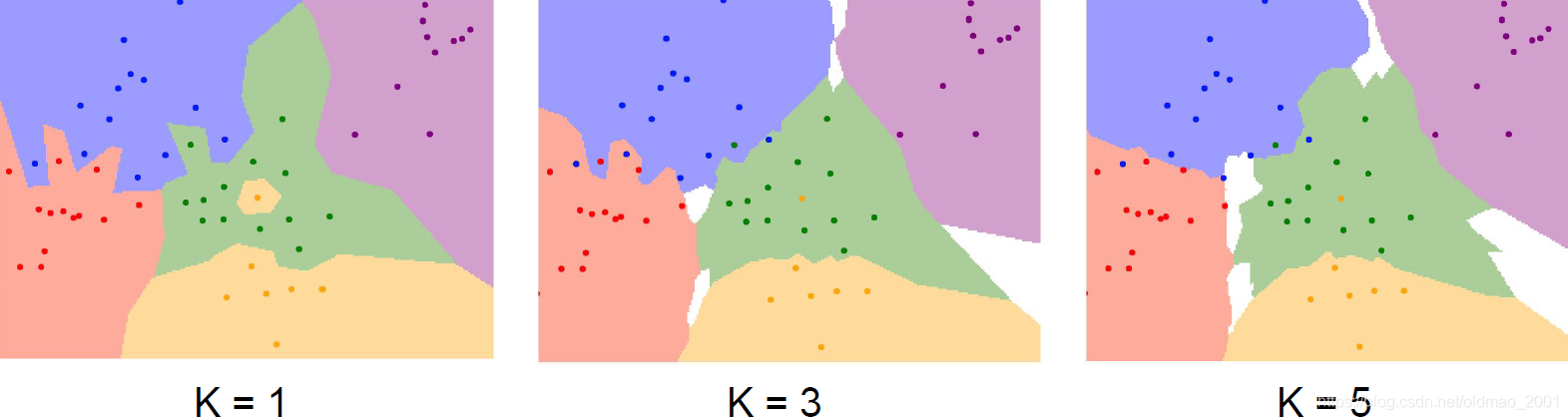
从点图上看,其缺点更加明显
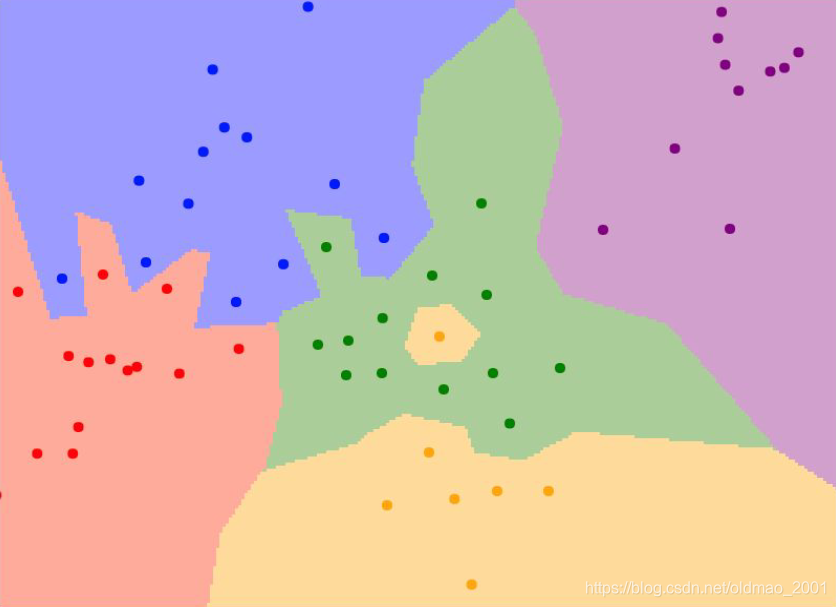
例如绿色区域里面出现了黄点,绿色区域插入了蓝色和粉色区域,改进一下就得到下面算法:
K近邻分类器
不再考虑所有点,而是只考虑K个最近邻的点
L2距离
当然,使用不同的度量距离的方式,得到的结果也不一样,如果使用L2距离:
L1 distance:
d
1
(
I
1
,
I
2
)
=
∑
p
(
I
1
p
−
I
2
p
)
2
d_1(I_1,I_2)=\sqrt{\sum_{p}{\left ( I_1^p-I_2^p \right )^2}}
d1(I1,I2)=p∑(I1p−I2p)2
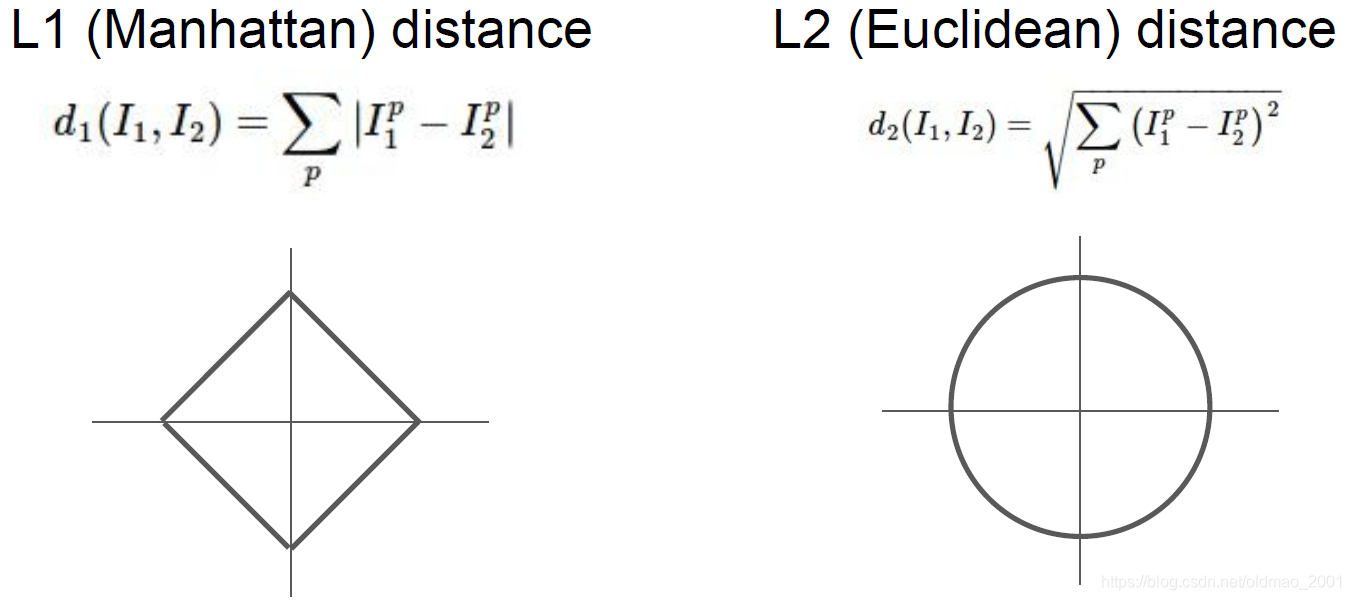
重要原则可以看到L1在旋转坐标后,距离是变化的,而L2不会,因此如果输入的特征向量中的一些值对于输出有非常重要的意义或影响,这个时候应该使用L1距离,但是如果特征向量只是某个空间中的一个通用向量,用L2会好一点。
这里还给出了一个KNN的DEMO:添加链接描述
算法的超参数
超参数的概念ng的深度学习中已经讲过,就是不是机器学习的参数,而是人为设置的,这里出超参数为:
K和距离度量方式。
设置超参数的方法ng的课里面也讲了,就是把数据分train,validation,test,三部分来调参,三者比例在ng的笔记里面有。
当然还可以用cross-validation的方法,在dl里面不怎么常用(dl的train的时间太长)。
磕盐人员要注意这里,需要非常严谨的对待test set
线性分类器
Linear classifiers用于组成神经网络,也可以看出网络中的基本神经元,因此,了解线性分类器是很有必要的。
f
(
x
,
W
)
=
W
x
+
b
f(x,W)=Wx+b
f(x,W)=Wx+b
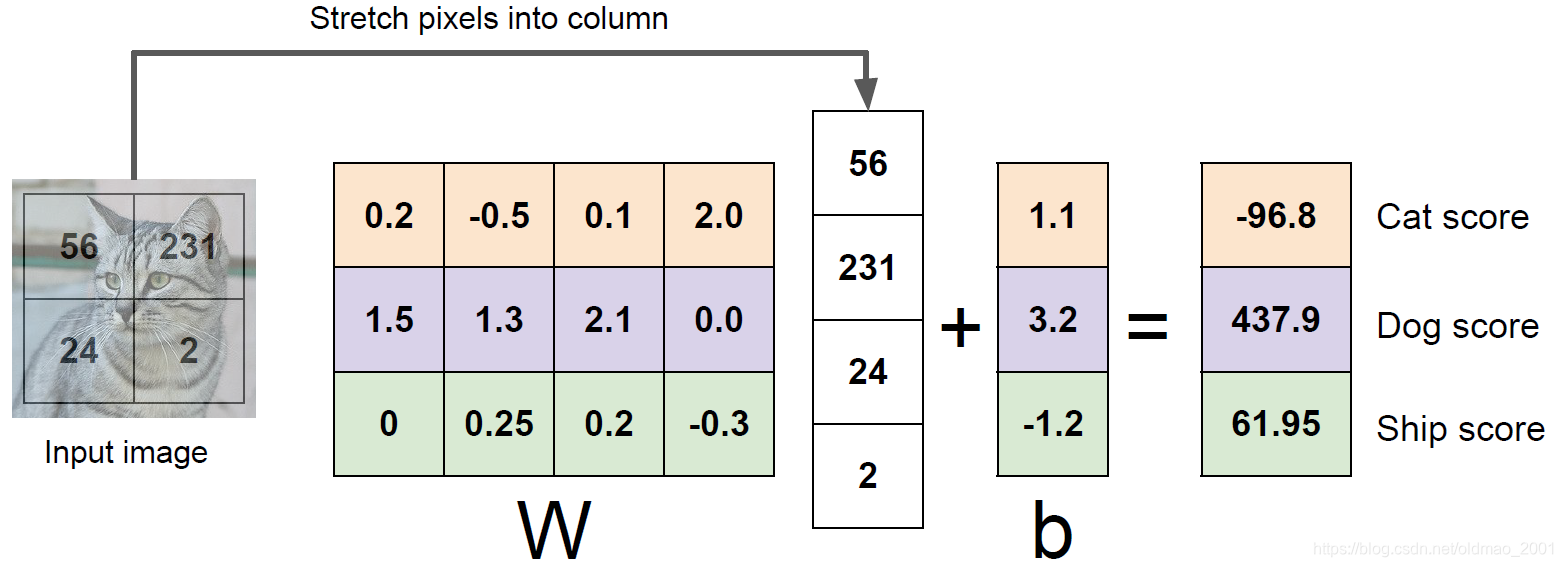
重点这里面注意行的颜色,W的每一行都对应了一个分类。这个观点是第一次看到有老师提到!把训练好的单独的每一行的提取出来,还原为图像,就可以看到线性分类器是如何根据什么特征进行分类的。
这里要注意一个概念:图像分类模板,这个模板在CNN里面和每个图片进行点乘后,相应分类就会得到比较大的结果。
线性分类器的限制
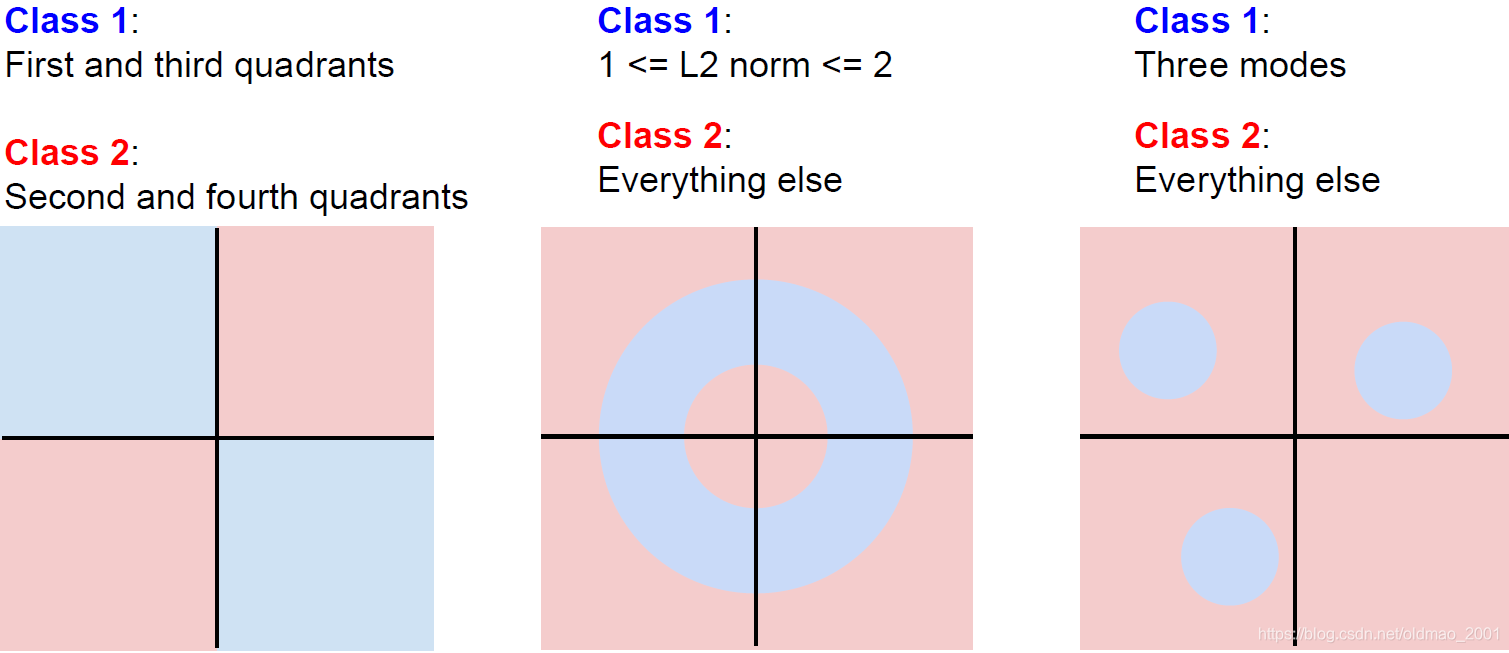
这里面的例子一经常有出现在各种教程里面,后面两种不常见,所以要对线性分类器进行堆叠,变成神经网络,就可以解决以上问题,这里可以参考李宏毅学习笔记5的后面部分。
用老师的话说:线性分类器没法划分multi model data。
下节课将学习如何选择W,或者说判断函数f(x,W)的好坏。
思考题
有关L1距离和L2距离的如何实现,思考如何绘制决策边界?
怎样划分训练集和测试集?



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











