









作为电商卖家,选款是一件很重要的事情,所以我们在选款上面需要下大功夫分析数据。
如何第一时间知晓同类商品及其价格,如何实时采集到新款、爆款,及其价格?
下面我对比两种方法,看看哪种方式更适合我们普通电商从业人员!
目标:抓取拼多多某类商品的列表页面信息,以“学生文具用品笔”为例,采集商品名称、价格。
方法一 python编写爬虫程序
A、思路分析
1)参数寻找
首先说明:图下这个url如果按照 “进首页、输关键字、点击搜索”的步骤会出现很多参数。
http://mobile.yangkeduo.com/search_result.html?search_key=小学生文具用品&search_src=new&search_met=btn_sort&search_met_track=manual&refer_page_name=search_result&refer_page_id=10015_1566810380672_oQen4fLq1E&refer_page_sn=10015
但有效参数就只有search_key一个。其他多余的参数应该删除。
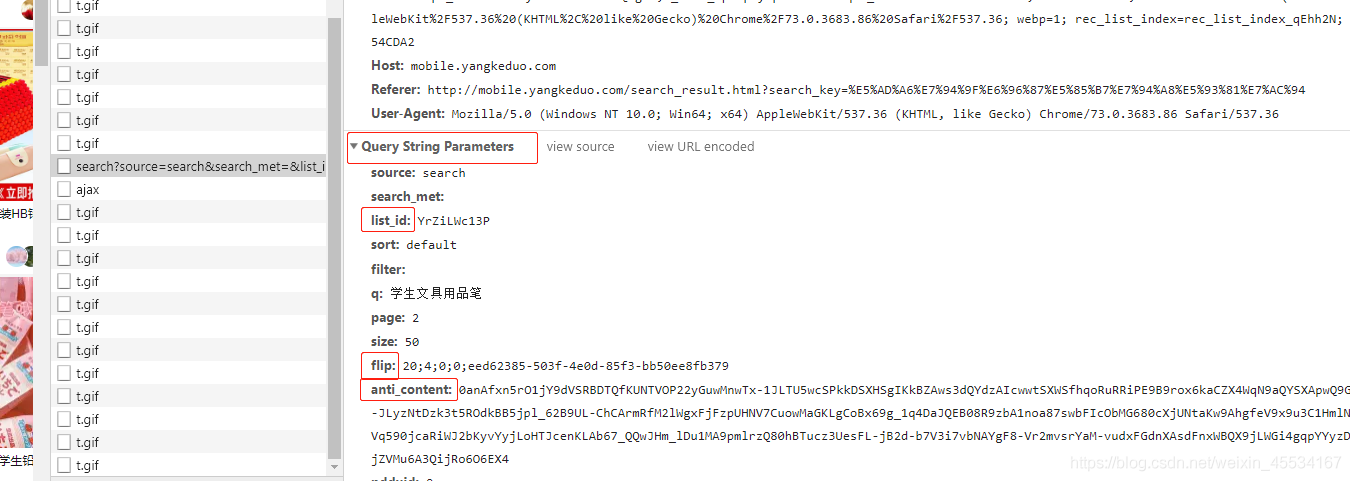
headers没啥说的,都挺正常。然后看params里面主要就是list_id、flip、anti_content三个参数,这三个参数不知道咋出来的了。
2)list_id、flip
仔细找就能发现,list_id、flip这俩参数是在主页里面的,这个id名为__NEXT_DATA__的script标签下就有list_id和flip。
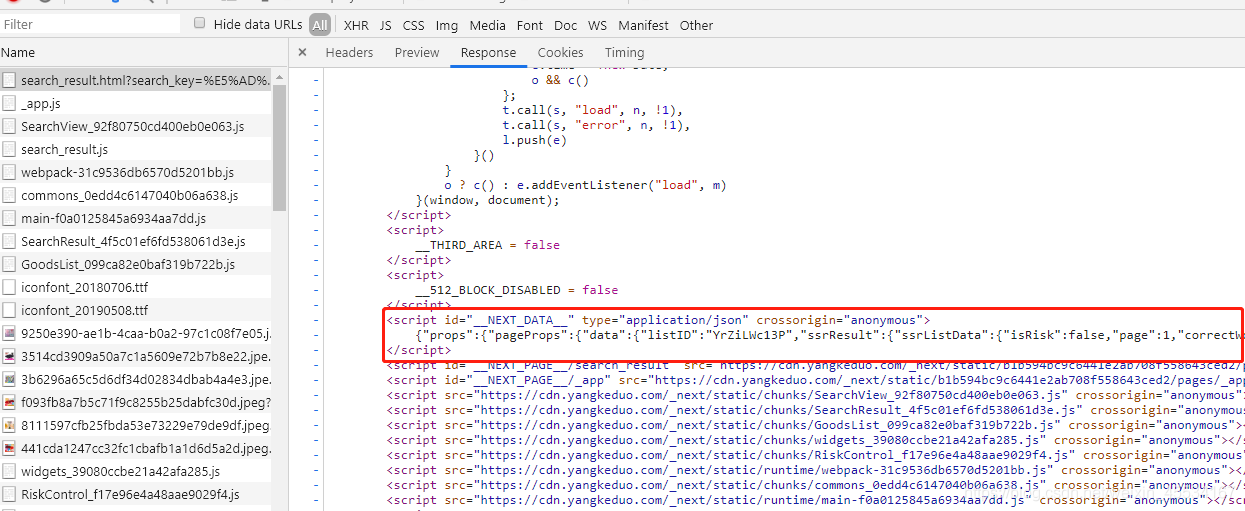
3)anti_content
在找到了list_id和flip后就只剩一个anti_content参数了,这就是拼多多在js上的反爬措施。
B、找入口
将鼠标悬浮到加载过的js后能看到很长一串,一般都是随便点一个,然后进去用上下栈慢慢找。
拼多多的这个js是真的不好找,因为是异步执行的,调用上下栈能看到的参数是以异步前后分开的,所以耐心特别重要了。当然不是纯看参数,有时候也可以搜,或者看看代码英文对应的大概意思。
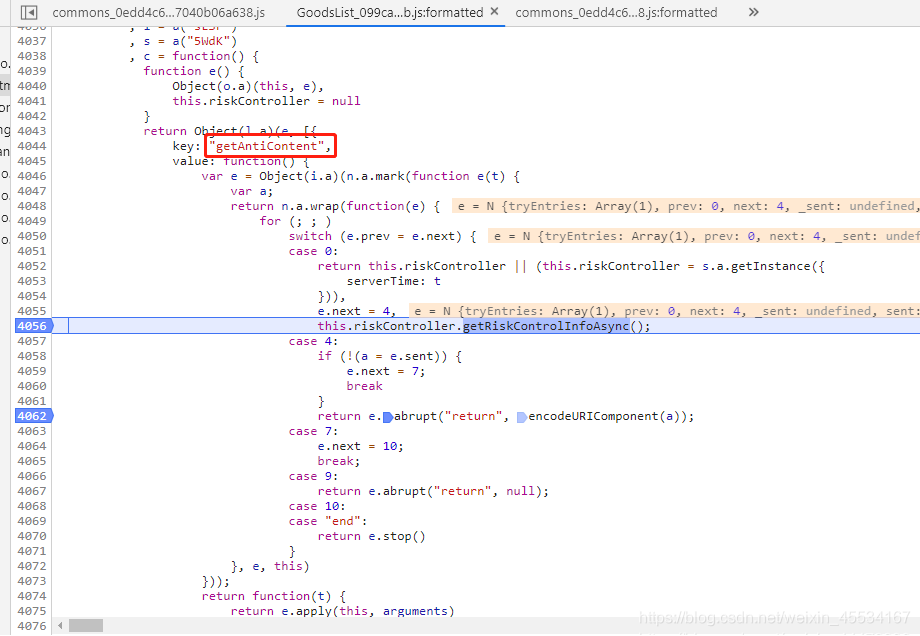
比如到这里的时候,这个getAntiContent那不就明摆着了吗?然后读一下riskController啥意思?不就是风险控制吗。这连anti_content的大概意思都懂了,然后再看看到了case 4的情况:
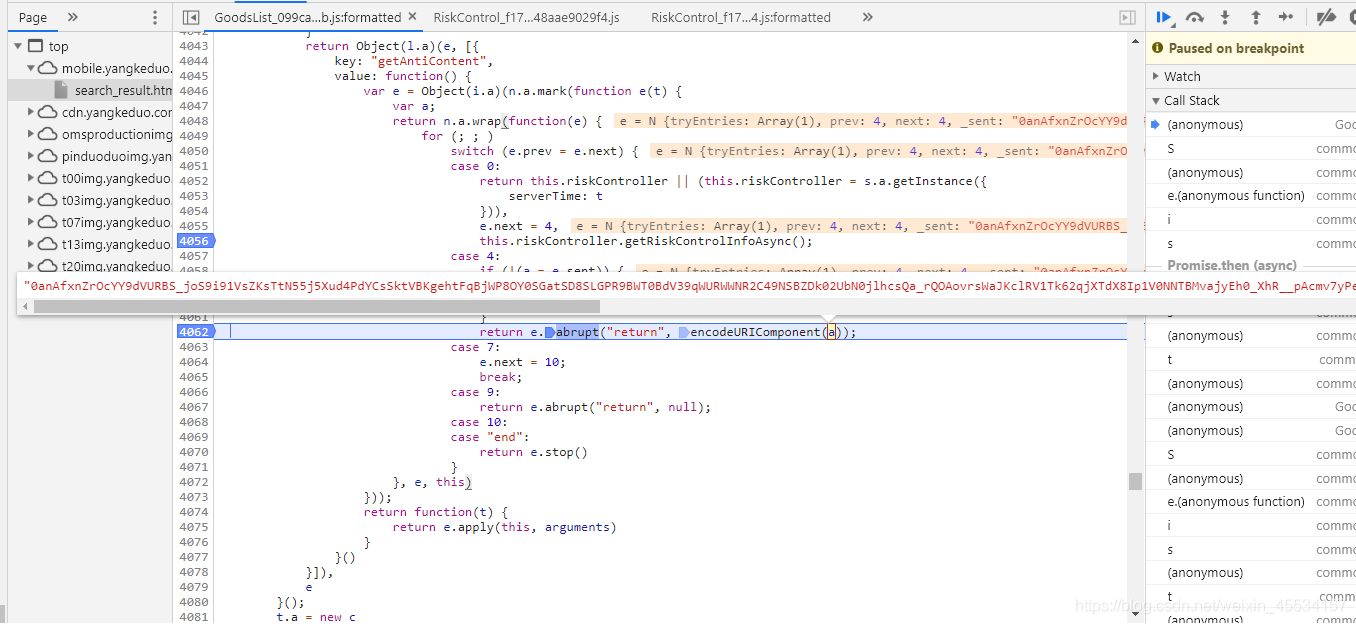
这个时候我们需要的anti_content已经出来,那么就意味着在case 0到case 4之间他已经加密完成了,接下来就再一次在case 0到case 4之间一直按F11观察情况了。然后按着按着就来到了这个js文件:
js文件名就叫RiskControl,再然后多按几下F11,这就是入口了。
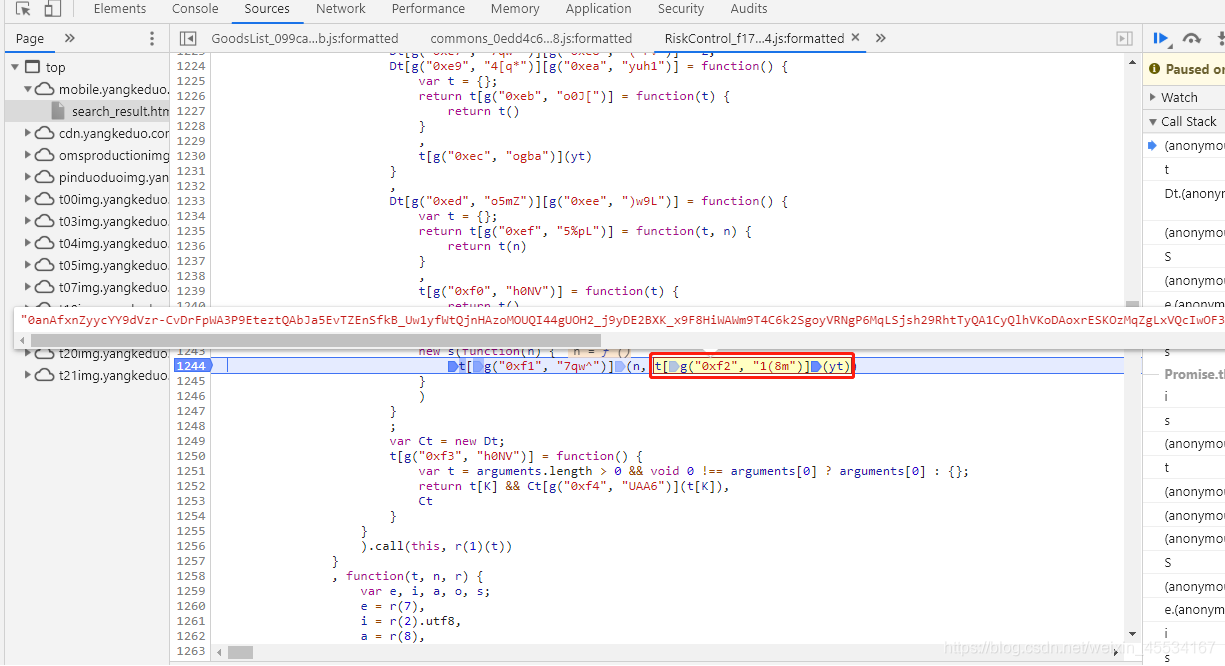
C、逆js
拼多多的js用了N多“语法丑化”的混淆方式,其目的就是为了增大代码阅读量。当解起来的时候会出现很多开发中不可能出现的调用。

1、获取初始化参数r;
2、以r为基础参数,产生最后需要转换成字符串的数组s。
第一步:r
……
第二步:o
……
此处省略五千字左右。太难了,程序员看起来都比较吃力,就不展示了。
总之,整个anti_content的破解,从开始找入口到解出来用了1天半,其中,大半天都用在了无用功上。
……
接下来如何爬取的规则也不进行演示了!
接下来如何爬取的规则也不进行演示了!
接下来如何爬取的规则也不进行演示了!
因为我在修改这篇文章时(大概就是一星期左右),拼多多的前后端代码又改了,已经不能通过先前那个url去分析了。要想编写采集爬虫,还得重新分析。
方法二 直接使用现成数据
相比之下,使用第三方现成数据可以少掉很多头发,因为平台的规则一直都在变化,需要有人专门盯着这个平台规则
总结
如上所述,要使用多多数据,建议使用第三方的数据,如果只是偶尔需要一两个数据分析,可以自己去抓取

















 4570
4570

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









