







 文章探讨了搜索引擎如何使用爬虫技术抓取数据并分析,以及电商网站如何防止数据被大规模采集。作者提到,网站通过混淆JavaScript代码和加密核心逻辑来阻止爬虫。文章旨在用于学术研究,强调遵守法律和互联网规则,同时鼓励读者通过学习和讨论提升技能,但不应用于非法活动。
文章探讨了搜索引擎如何使用爬虫技术抓取数据并分析,以及电商网站如何防止数据被大规模采集。作者提到,网站通过混淆JavaScript代码和加密核心逻辑来阻止爬虫。文章旨在用于学术研究,强调遵守法律和互联网规则,同时鼓励读者通过学习和讨论提升技能,但不应用于非法活动。
序言
各大搜索引擎用到了爬虫技术实现网络数据的抓取,通过抓取的数据进行分析来方面我们检索想要的数据。很多电子商务平台有万级、亿级的产品数据数据,他们希望客户可以正常浏览。他们同时又防止数据
被大量的采集。至少他们要防止90%的用户很难进行大量采集。作为逆向工作的你和我,对技术有向往和追求的,我们通过要实现反反爬工程来挑战自我,为的是超越自我。一些网站的反爬手段通过会用javascript代码把一些
执行函数进行混淆,把核心逻辑进行加密。让逆向工作很难通过协议来抓取数据。
注意事项
本文展示的内容目的是为了学术研究,按理脱敏工作做得非常到位,希望大家学会本领不要攻击任何人的服务器,一定要遵守互联网各项正确的规则,一定要遵守法律法规。
顺藤摸瓜
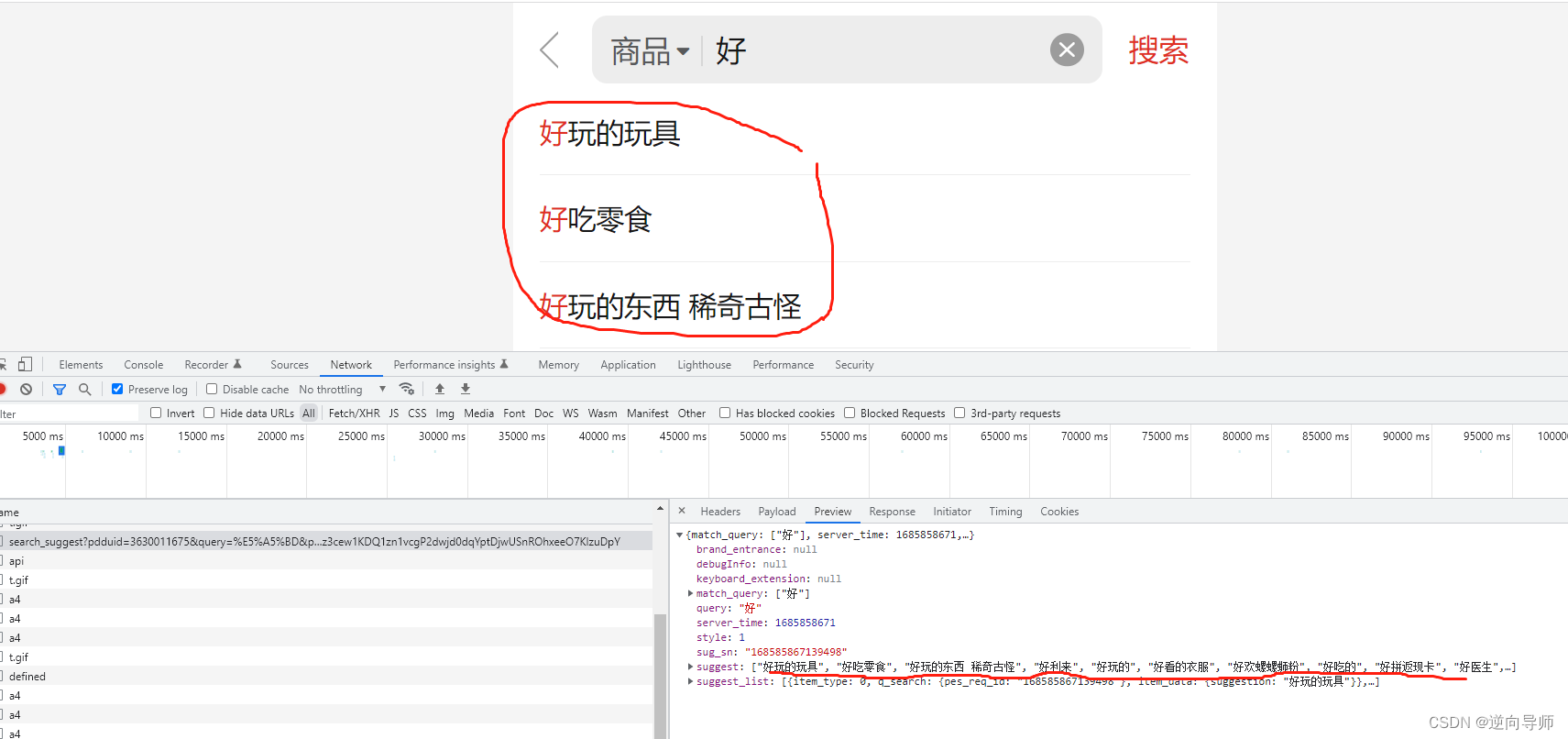
分析问题,一定要找一个切入点,我们一般用谷歌浏览器打开网址,打开开发者工具,找到一个跟输入内容有相应回应的请求地址,例如search_suggest?pdduid=*&query=*
第一步:打开wap网址:mobile.***/search_result.html?search_key=%E6%89%8B%E6%9C%BA&search_type=goods
‘
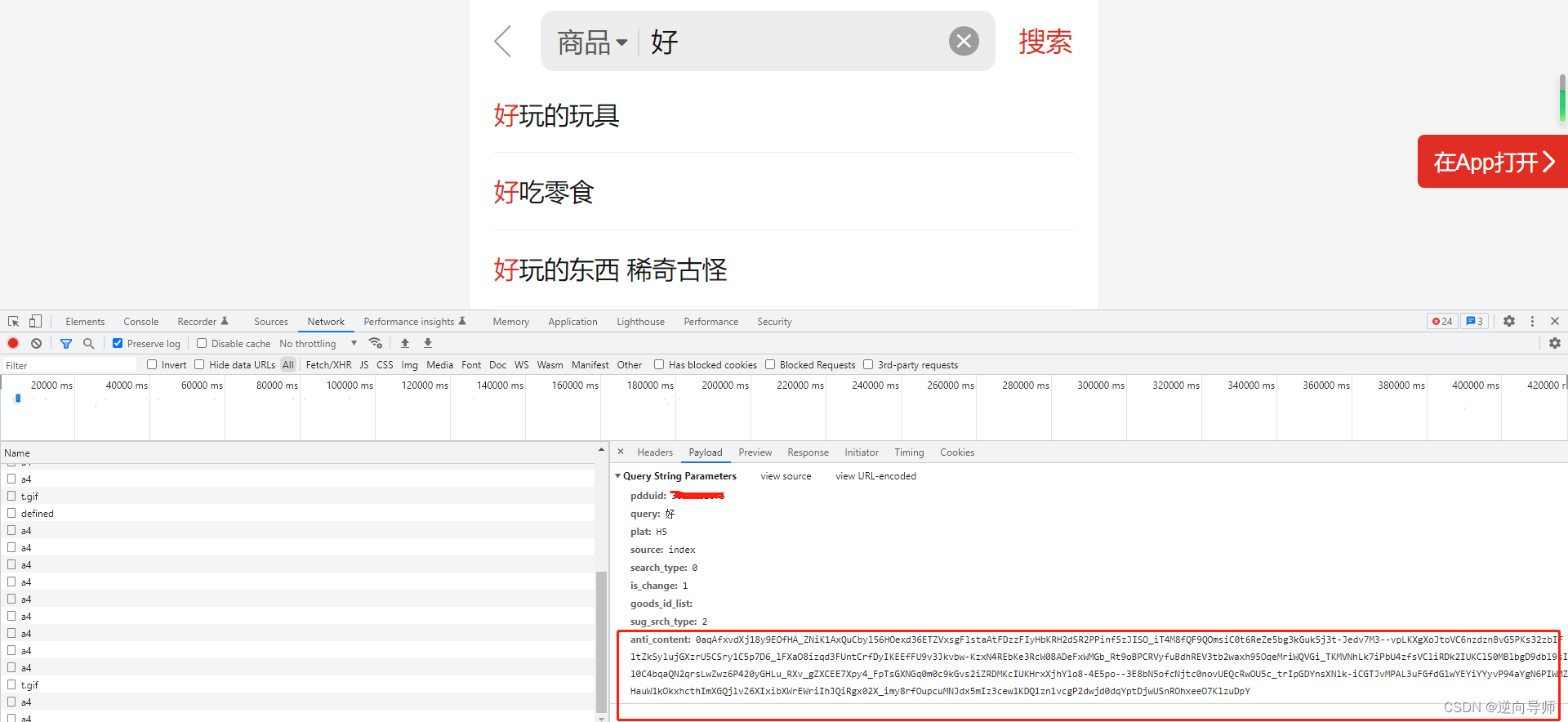
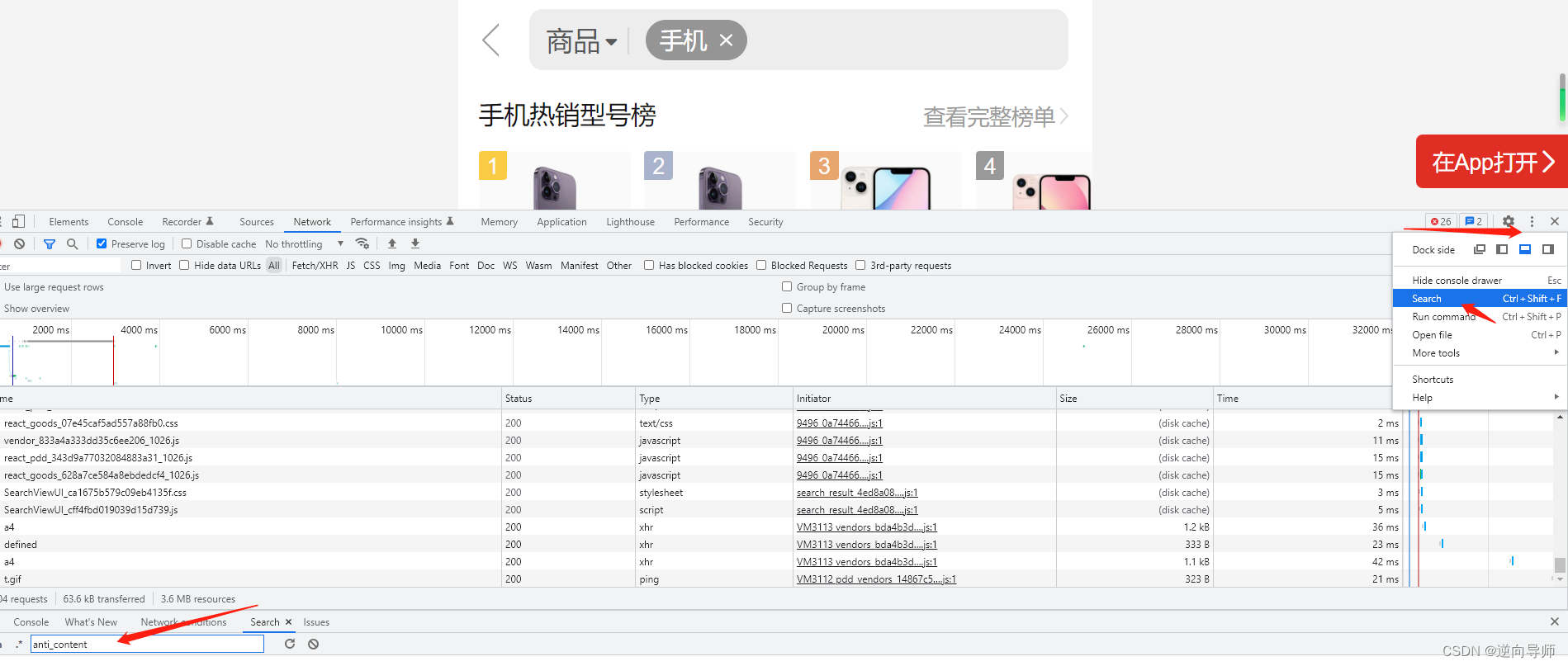
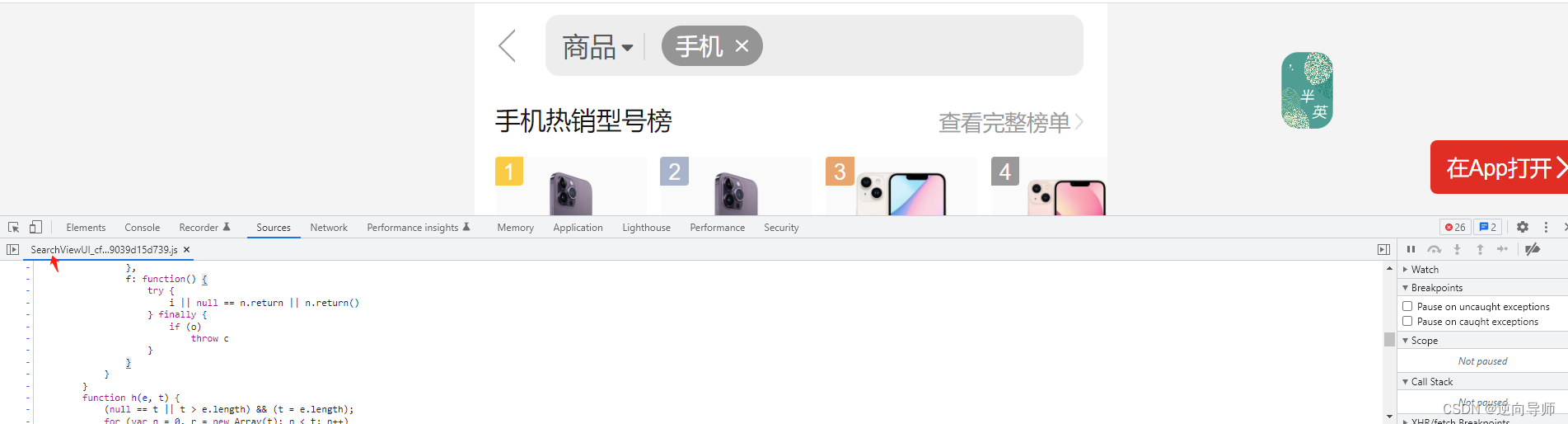

最后就是扣js和补环境
!(function (t) {
var n = {};
function r(e) {
if (n[e])
return n[e].exports;
var o = n[e] = {
i: e,
l: !1,
exports: {}
};
return t[e].call(o.exports, o, o.exports, r),
o.l = !0,
o.exports
};
window.q258599831 = r;
})([function (t, n, r) {
// 此部分与原 js 文件一样, 在此省略
])
let anti_content = window.q258599831(4);
result = new anti_content({ serverTime: new Date().getTime() });
做成云端
然后把逆向工程可以向我一样做成云接口,以后爬去数据可以先调一个云接口获取anti_content
特别声明,水能载舟,水亦能覆舟。IT技术可以让互联网更快,更高,更好发展。同样IT技术也会危害互联网的发展。So,我们要掌握IT技术,我们同样要了解互联的知识,遵守互联网的规则,切勿触碰违法事业。
以上代码百分百原创,仅供学习。欢迎大家一起讨论,共同进步。有兴趣欢迎私聊。


















 1407
1407

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











