










目标检测:R-cnn、faster-r-cnn、YOLO等
R-cnn:
- 候选区域:使用 选择性搜索(Selective Search) 等算法(合并像素,非常耗时)在输入图像中生成一组候选区域。
- 特征提取:候选区->特征向量。
- 区域分类:SVM判断是否有物体,并进行分类。
- 区域校准:对边界框(bounding box)进行校准。
有大量的重复计算,非常耗时。
fast-r-cnn ICCV 2015
解决了特征图重复计算的问题。
- 候选区域:使用 选择性搜索(Selective Search) 等算法(合并像素,非常耗时)在输入图像中生成一组候选区域。
- 特征提取:对整张图像进行特征提取。
- 候选区域特征:利用 RoIPooling 算法分别生成每个候选区域的特征。
- 候选区域分类与回归。
ROI Pooling:
ref
ROI Pooling解决的是候选区域大小不一致的问题,ROI Pooling之后,候选区域的大小一致,就可以进行并行的计算,加快速度。
faster-r-cnn
- 特征提取:使用一组基础的conv+relu+pooling层提取image的feature maps。该feature maps被共享用于后续RPN层等。
- 生成锚框(anchors)。
注:其实这个锚框是作者自己人为设计的9个框。
每一个点都配备这9种anchors作为初始的检测框。
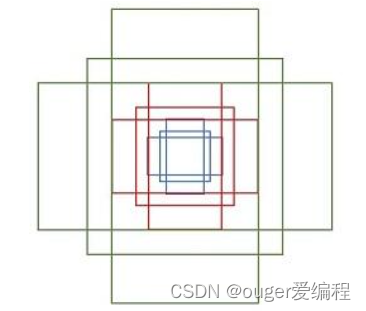
- 使用RPN将每个框映射到两个通道,一个用于二分类(目标/非目标),一个用于回归(调整锚框大小和位置)。然后就可以根据得分大小,经过回归生成候选区域。这里面的回归比较复杂,没看懂。大概的意思就是利用候选框和真实目标框训练一个回归器,回归器的输出是四维向量,分别表示锚框的水平偏移、垂直偏移、宽度调整和高度调整。
- ROI Pooling。
- 分类。
YOLO
思想:one-stage,本质上是一个回归算法。
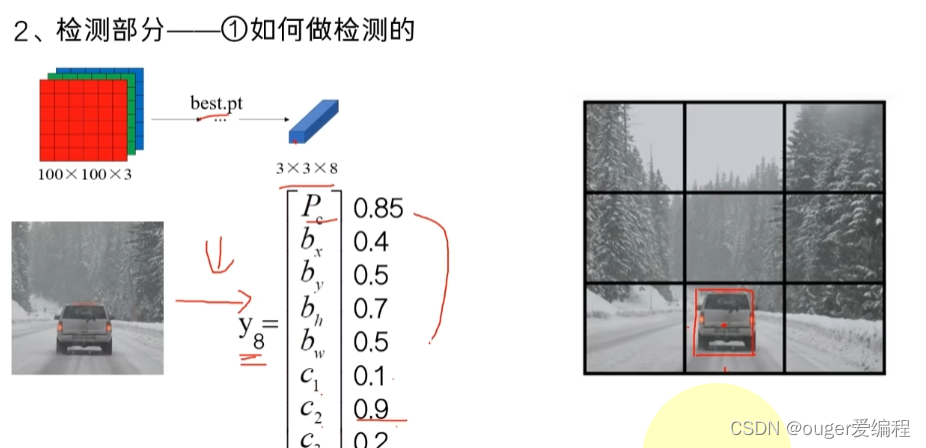
非极大值抑制(NMS):一图多目标时候用,IoU大于阈值时,就抑制置信度小的检测框。
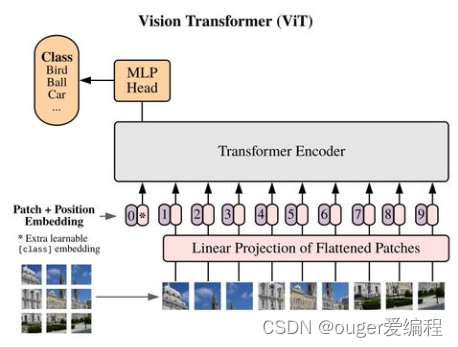
ViT
ref
思想:将图像分成
N
=
H
∗
W
/
(
P
∗
P
)
N=H*W/(P*P)
N=H∗W/(P∗P) 个 patch,把patch flatten为
P
∗
P
P*P
P∗P 的一维向量,再进行线性映射,得到
N
N
N 个 维度为
e
m
b
e
d
_
d
i
m
embed\_dim
embed_dim patch embedding,
等价于对输入图像 HxWxC 执行一个内核大小为 PxP ,步长为 P 的卷积操作
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
再和绝对位置编码的embedding(也是一个矩阵)相加,再通过transformer进行处理。
Swin Transformer
ref1 ref2
主要内容:Swin Transformer 是在Vit的基础上进行的改进,针对Vit的全局自注意力计算复杂度过大的问题,提出了window的思想,使得自注意力的计算局限在window里面,从而减少复杂度。还提出了相对位置编码的思想。为了在不同窗口间进行信息交互,还提出了shift window attention、Attention Mask的思想(非常巧妙)。巧妙的利用Attention Mask实现了与window attention等价的计算。
Swin Transformer V2
CV最常用的损失函数
交叉熵
:
−
∑
i
p
A
(
v
i
)
l
o
g
(
p
B
(
v
i
)
)
交叉熵:{\large -\sum_ip_A(v_i)log(p_B(v_i))}
交叉熵:−i∑pA(vi)log(pB(vi))
其中
p
B
(
v
i
)
是样本
i
属于类别
B
的概率,
p
A
(
v
i
)
取
0
或
1
,当样本
i
属于类别
B
时为
1
,否则取
0
。
其中p_B(v_i)是样本i属于类别B的概率,\\ p_A(v_i)取0或1,当样本i属于类别B时为1,否则取0。
其中pB(vi)是样本i属于类别B的概率,pA(vi)取0或1,当样本i属于类别B时为1,否则取0。
注:KL散度用于度量两个不同分布之间的差异,通过推导科研得到交叉熵的公式(应该说“最小化KL散度等价于最小化交叉熵”),所以交叉熵可以用来作为loss函数。
交叉熵常常用于分类问题。
L1 loss(又称MAE),平均绝对误差:预测值和真实值之间的误差:sum(|y_pre - y_true|)/n ,用于回归问题。
L2损失函数,又称均分误差 MSE: sum((y_pre-y_true)^2)/n,用于回归问题。
最先进的模型的好像是InternImage,基于cnn的模型。















 1033
1033

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









