







paper:Self-training with Noisy Student improves ImageNet classification
official implementation:https://github.com/google-research/noisystudent
本文的创新点
本文提出了一种新的半监督方法Noisy Student Training,主要包括三步:(1)在有标签数据上训练一个教师模型(2)利用教师模型在无标签数据上生成伪标签(3)结合有标签的图片和伪标签的图片训练学生模型。重复迭代这个过程,将学生作为教师重新生成伪标签,然后再训练一个新的学生模型。
Noisy Student Training从两个方面提高自训练和蒸馏的能力。首先,它使用的学生模型比教师模型更大(或至少相等),这样学生可以更好的从一个更大的数据集中学习。其次,它给学生模型增加的噪声,这迫使学生模型更努力的从伪标签中学习。
方法介绍

算法1概述了Noisy Student Training的过程。算法的输入包括有标签和无标签的图片。我们首先在有标签图片上用交叉熵损失训练一个教师模型。然后用教师模型在无标签图片上生成伪标签。伪标签可以是soft(连续分布)或hard(one-hot分布)。然后我们训练一个学生模型,在标签图片和无标签图片上最小化交叉熵损失。最后我们迭代这个过程,将训练好的学生模型作为教师模型在无标签数据上生成新的伪标签,并训练一个新的学生模型。算法的过程如图1所示
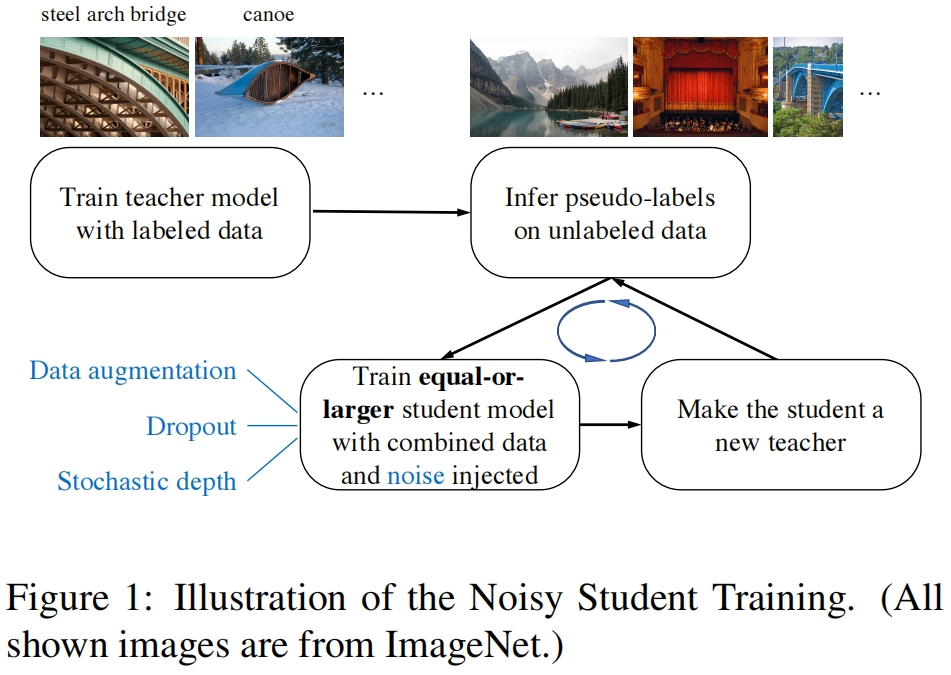
本文方法的关键改进在于给学生模型增加噪声,并使用不小于教师模型的学生模型。这使得该方法不同于知识蒸馏:1)蒸馏中通常不适用噪声 2)蒸馏中通常使用比教师小的学生模型。我们可以把本文的方法看作一种knowledge expansion,通过给学生模型足够的容量和更困难的学习环境(添加噪声),我们希望学生模型比教师更好。
作者在实验中使用了两种类型的噪声:输入噪声和模型噪声。输入噪声使用了数据增强方法RandAugment(具体见RandAugment(NeurIPS 2020)论文速读-CSDN博客),模型噪声使用了dropout和stochastic depth(见Stochastic Depth 原理与代码解析-CSDN博客)。
当应用于无标签数据时,噪声有一个重要的好处,即enforce决策函数在标签数据和无标签数据上的不变性。首先,数据增强是Noisy Student Training中一种重要的噪声方法,因为它迫使学生在同一张图片的不同增强变形上的预测一致性。具体来说,教师在干净的图片上生成高质量的伪标签,而学生则需要用增强后的图片来复制这些标签,即学生必须确保增强后的图片和原始图片是相同的类别。其次,当使用dropout和stochastic depth作为噪声时,教师模型在推理时(生成伪标签时)表现的像一个集成模型,而学生则像一个单一的模型。换句话说,学生被迫模仿一个更强大的集成模型。
Other Techniques 作者还使用了额外的trick:data filtering和balancing,这让Noisy Student Training的效果更进一步。具体来说,我们过滤掉教师模型推理时置信度低的图片,因为这些通常是out-of-doman图片。为了确保无标签图片的分布和训练集的分布相匹配,我们还需要平衡无标签图片中每个类别的数量,因为ImageNet中所有类别都有相似数量的标签图片。具体做法是,对于数量不够的类别进行复制,对数量太多的类别,只用置信度最高的图片。
最后作者还强调了下在实验中使用hard或soft伪标签Noisy Student的效果都很好。对于out-of-doman的无标签数据,soft伪标签的效果稍好些。
实验结果
实验细节
数据集. 有标签数据选用ImageNet数据集。无标签数据选用JFT数据集,并从中过滤掉ImageNet验证集中的图片。然后在剩下的图片上进行data filtering和balancing。首先用在ImageNet上训练的EfficientNet-B0模型为JFT中的每张图片预测一个标签,然后选择置信度大于0.3的图片。每个类别,选择置信度最高的130K张图片,如果本身不足130K的随机复制进行补齐。这样用于训练学生模型的图片共有130M张(实际只有81M,其它都是复制的)。
模型结构. 作者选择EfficientNet作为baseline模型,并进一步增大EfficientNet-B7得到EfficientNet-L2,后者并前者更深更宽但用了更小的输入分辨率。
训练细节. 对于有标签数据,batch size默认选择2048。有标签数据的训练时长和学习率根据batch size进行调整,具体来说,对于大于EfficientNet-B4的学生模型训练350个epoch,对于更小的学生模型训练700个epoch。训练350个epoch且batch size为2048时,初始学习率为0.128每个2.4个epoch衰减0.97,训练700个epoch时每个4.8个epoch进行衰减。
噪声. 对EfficientNet-B7和L2选择相同的噪声超参。其中最后一层stochastic depth的概率为0.8,其它层遵循linear decay rule。最后一层的dropout rate为0.5。对于RandAugment,选择两种随机变换,强度设置为27。
迭代训练. 作者实验得到的最好模型是将学生作为教师模型迭代三次得到的。首先在ImageNet上训练一个EfficientNet-B7作为教师模型。然后在无标签数据上训练一个EfficientNet-L2的学生模型,无标签数据的batch size是有标签数据的14倍。然后将这个EfficientNet-L2的学生模型作为教师模型再训练一个新的EfficientNet-L2的学生模型。最后再迭代一次,此时无标签的batch size设置有标签的28倍。
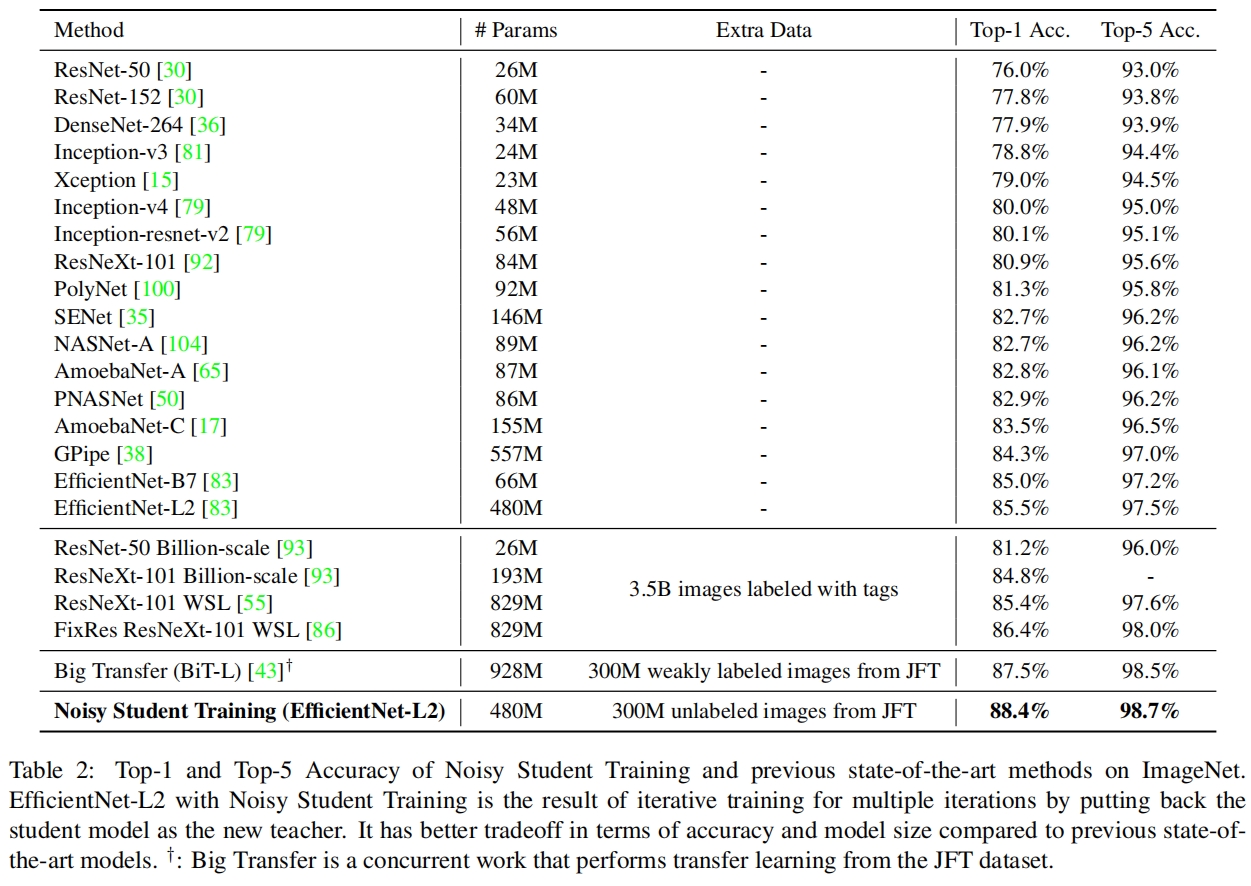
在ImageNet验证集上的结果如表2所示,用Noisy Student训练的EfficientNet-L2达到了88.4%的准确率,远超于之前EfficientNet系列的85.0%的准确率。提升的3.4%中0.5%来源于更大的模型,2.9%来源于Noisy Student Training,这表明Noisy Student Training对模型精度的影响比调整网络结构大得多。
此外,88.4%的精度还超过了之前采用FixRes ResNeXt-101 WSL的86.4%的SOTA,且后者使用了35亿张有标签的Instagram图片。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











