







paper:RandAugment: Practical automated data augmentation with a reduced search space
third-party implementation:https://github.com/open-mmlab/mmpretrain/blob/main/mmpretrain/datasets/transforms/auto_augment.py
存在的问题
自动增强策略已经在图像分类和目标检测任务取得了sota的效果,大规模采用这些方法的一个障碍是它们包含一个单独搜索阶段,这增加的训练的复杂性并可能大大增加计算成本。此外由于单独搜索阶段的存在,这些方法无法发根据模型或数据集的大小来调整正则化强度。自动搜索策略通常是在小数据上训练小模型,然后应用于训练更大的模型。
本文的创新点
本文为了消除了上述两个障碍,提出了一种新的数据增强策略RandAugment,它显著减小了搜索空间,并可以直接在目标任务上训练而不需要一个单独的代理任务。此外它的正则化强度可以根据不同模型和数据集的大小进行定制,并可以在不同任务和数据集上统一使用。在CIFAR-10/100、SVHN、ImageNet数据集上,RandAugment相较于之前的所有自动增强方法,取得了匹配或更优的性能。
本文的贡献总结如下:
- 本文证明了数据增强的最佳强度取决于模型的大小和训练集的大小。这一观察结果表明,在一个较小的代理任务上,对增强策略的单独优化对于学习和迁移增强策略可能是次优的。
- 本文引入了一个大大简化的数据增强搜索空间,其中包含2个可解释的超参数。我们可以使用简单的网格搜索来为模型和数据集定制增强策略,去除了单独搜索的过程。
- 利用该方法,我们在CIFAR、SVHN、ImageNet上取得了sota的结果。在目标检测任务上,我们和sota只有0.3%的微小差距。在ImageNet上,我们取得了85.0%的sota精度,比之前的方法提升了0.6%,比baseline增强方法提升了1.0%。
方法介绍
RandAugment的主要目标是去掉在在代理任务上的单独搜索。因为单独的搜索阶段使训练变得复杂而且计算成本很高。更重要的是,代理任务可能导致结果是次优的。为了去除独立的搜索阶段,我们希望将数据增强策略的参数变为训练模型的超参。考虑到之前的学习的增强方法包含了30+参数,我们专注于大幅减少数据增强的参数空间。
以往的研究表明,learned增强策略的主要好处在于增加的示例的多样性。例如AutoAugment列举了一个策略,即从 \(K=14\) 个图像变换中选择应用哪些,以及应用每种变换的概率。

为了减少参数空间但同时保持图像的多样性,我们将学习的策略和应用每种变换的概率替换成parameter-free的过程,即总是以 \(\frac{1}{K}\) 的均匀概率选择一种变换。给定一个训练图像的 \(N\) 个变换,RandAugment可以有 \(K^N\) 种策略。最后需要考虑的一组参数是每个增强变换的大小magnitude。仿照AutoAugment,我们使用同样的线性尺度来表示每种变换的强度。简单的说就是每个变换的强度都表示为一个从0到10之间的整数,其中10表示最大强度。数据增强策略包括为每个变换确定一个整数。为了进一步减少参数空间,我们观察到,在训练过程中,每个变换学习到的强度都遵循一个相似的schedule(具体可以参考文章Population based augmentation中的图4),因此我们假设一个全局distortion \(M\) 足以参数化所有的变换。我们在训练中实验了4种 \(M\) 的schedule:常量强度、随机强度、线性增加的强度、上限一直增加的随机强度。
最终的算法包含两个参数 \(N,M\) 并且两行Python代码就可以实现,如下

这两个参数就是可解释的,比如 \(N\) 和 \(M\) 越大正则化的强度越大。一些标准方法可以用来进行参数优化,但考虑到搜索空间非常小,我们发现网格搜索grid search就相当有效了。
实验结果
作者首先通过实验验证了单独的代理任务失败的情况。
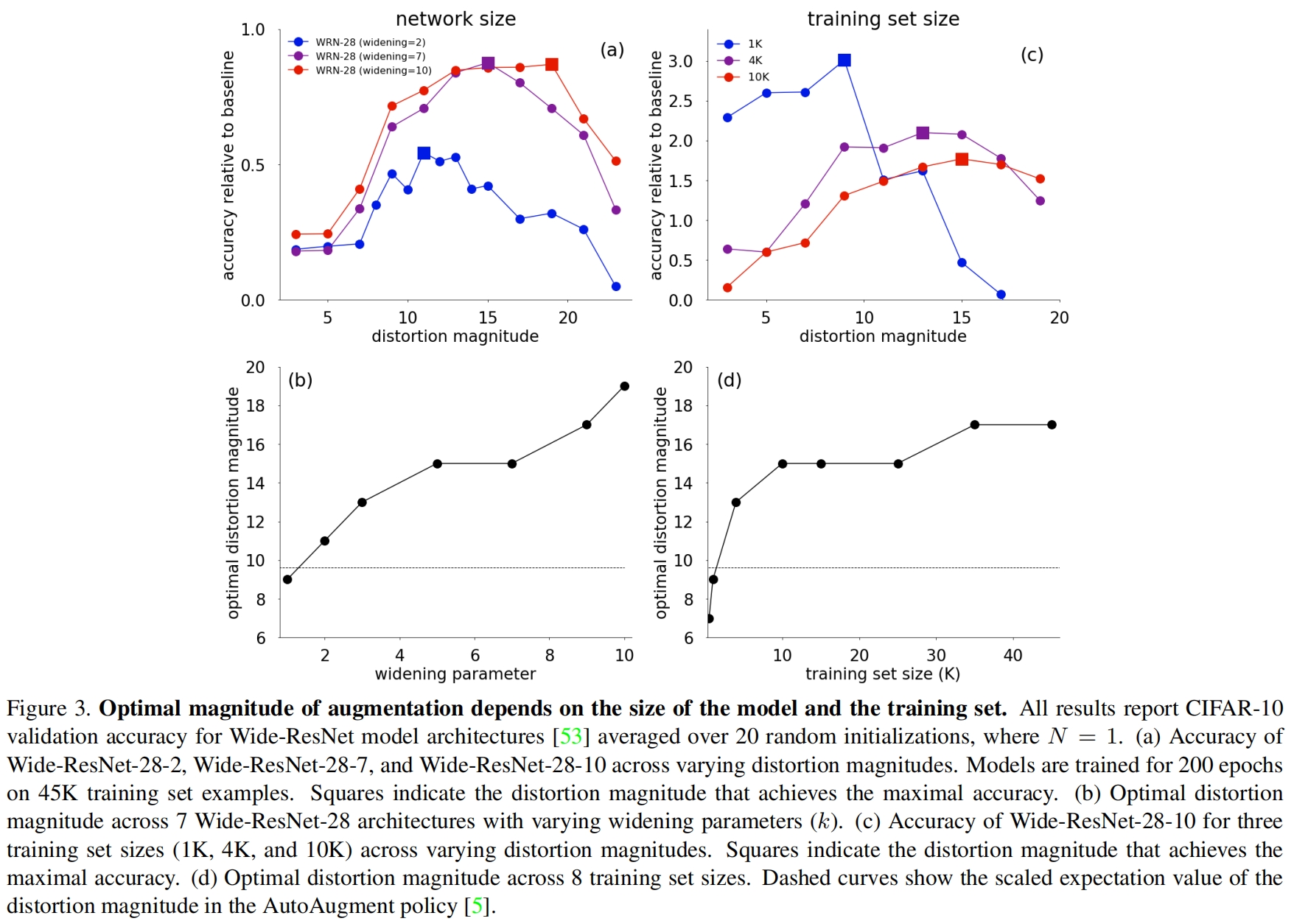
图3(a)展示了三种Wide-ResNet模型在逐渐增加的失真强度下精度相对baseline的提升,正方形处表示达到最高精度的失真强度。可以看出越大的模型,在达到最高精度时所需的失真强度也越大。这表明更大的网络需要更大的数据distortion来进行正则化,图3(b)也验证了这一点。图3(c)展示了Wide-ResNet-28-10在不同大小训练集上精度相对baseline的提升,同样训练集数据量越大,达到最高精度所需的失真强度也越大,图3(d)也验证了这一点。因此在代理任务上学习到的变换强度可能更针对于代理任务而不是目标任务。
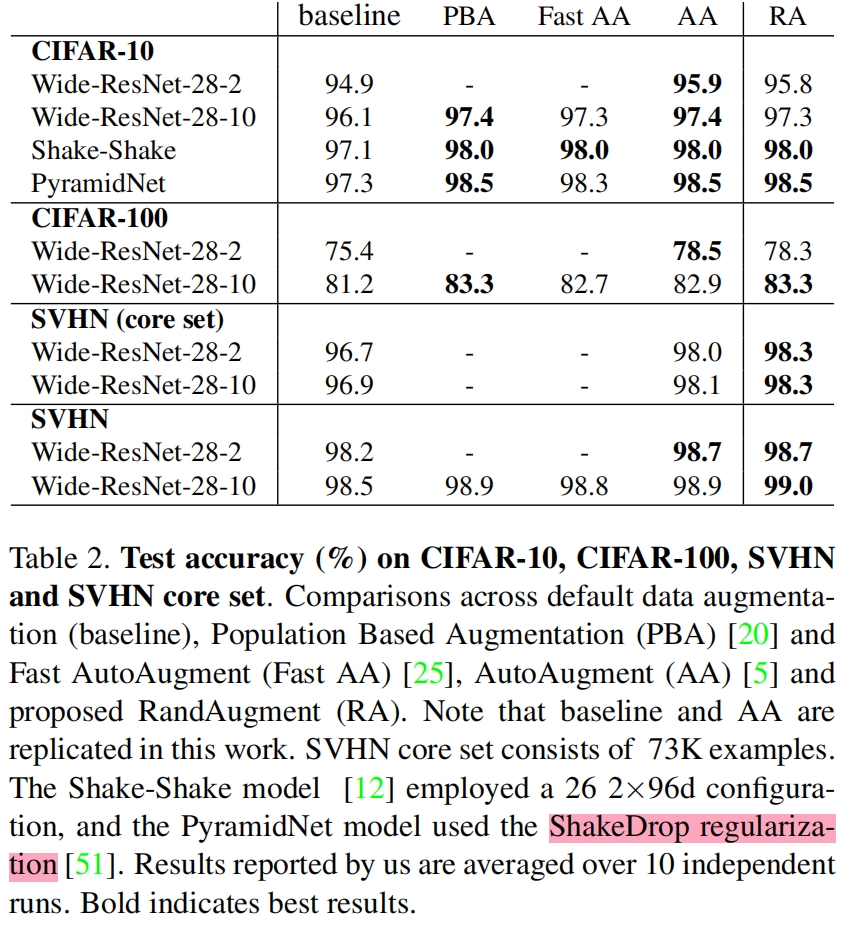
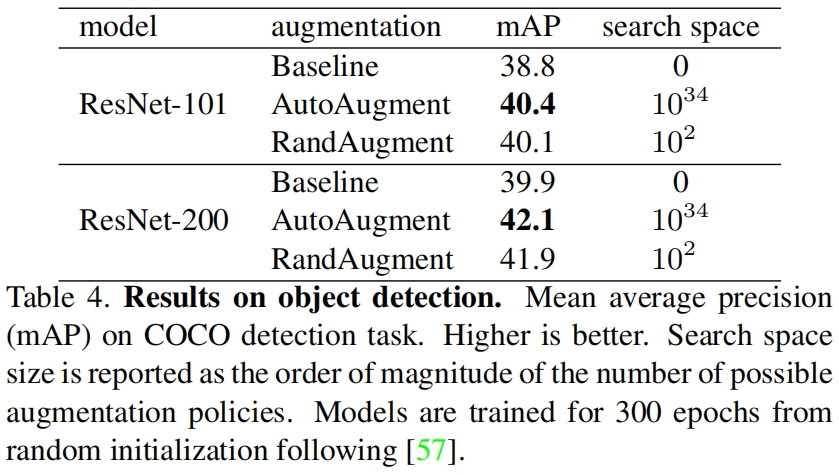
表2-表4分别是RandAument在CIFAR-10、CIFAR-100、SVHN、ImageNet、COCO数据集上与之前学习的增强方法的对比,可以看到RandAument取得了类似或更好的结果。



















 965
965

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











