






作者:兰韵诗
新加坡管理大学博士
华东师范大学数据科学与工程学院副教授
背景介绍
随着人工智能2.0时代的到来,大语言模型掀起了时代的浪潮。阿里云联合华东师范大学推出PolarDB开源社区自动问答机器人,帮助PolarDB开源社区的开发者快速检索到需要的技术细节和内容,提高业务开发与部署效率,提升社区服务体验。支持领域内内容高效查询、自定义投放场景和渠道、社区动态实时监测等功能。
PolarDB 是阿里云自研的云原生数据库产品家族,采用存储计算分离、软硬一体化设计,既拥有分布式设计的低成本优势,又具有集中式的易用性,可满足大规模应用场景需求。2021年,阿里云把数据库开源作为重要战略方向,正式开源自研核心数据库产品 PolarDB(PolarDB PostgreSQL 版和PolarDB 分布式版)。
作为行业领先的数据库产品,PolarDB提供详细的产品手册、运维文档、自媒体技术专栏以及体系化的课程等丰富的学习内容与资料,为广大开发者更好的使用PolarDB良好的支撑。为了更好的满足开发者以及企业用户的服务诉求,PolarDB提供了开源官网、阿里云开发者社区、技术交流钉群、企业专属钉群、微信交流群 、视频号等全方位的服务和交流矩阵。本项目将利用AI能力,充分挖掘PolarDB产品内容价值,为社区用户提供更高效、更精准的自助服务。
系统架构
整体框架
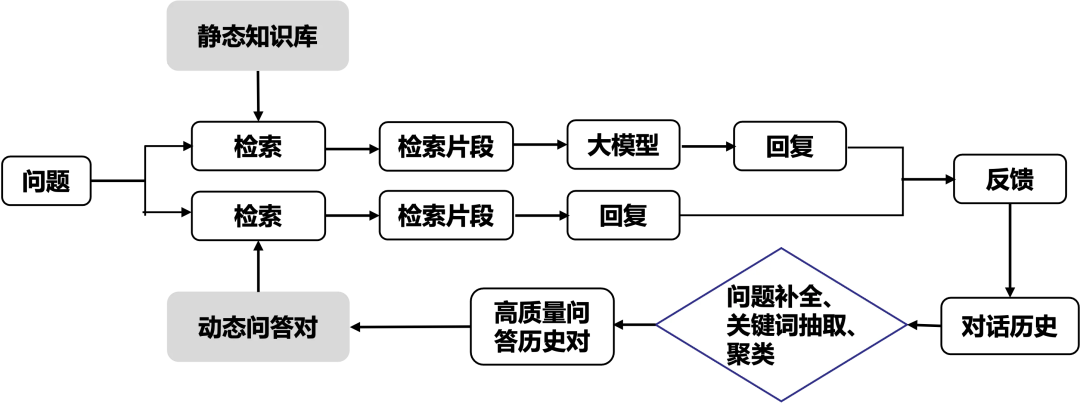
该框架延续目前广泛使用的大型语言模型驱动的应用LangChain系统,核心系统基于“PolarDB PostgreSQL版”+“通义千问模型”+RAG(Retrieval-Augmented Generation)框架,组装包括PolarDB各类手册文档、AnalyticDBV (ADBV)、钉钉在内的阿里云自研模块和华东师范大学自研工具OpenDigger以及开源数据可视化分析工具DataEase。实现一个从基础自研组件,大语言模型驱动,到上层系统维护和展示的全链路PolarDB机器人。
我们面向PolarDB业务场景整理多个维度的知识库,将PolarDB过去积累的领域和业务知识运转起来,有力地驱动企业的决策和生产效率。具体包括PolarDB PostgreSQL、PolarDB-X等官方技术文档、知乎高赞回答、微信推送文档以及运营历史问答等资料,覆盖包括PolarDB相关操作手册、技术讨论在内的领域知识库内容。除此之外,我们引入PostgreSQL、MySQL等技术手册、培训素材等资料,覆盖包含数据库相关基础查询、技术讨论在内的知识库内容。

整体工作流程如下:
-
知识上传与存储:相关知识内容上传后,系统会自动对上传文件进行解析、切片并存储在PolarDB中;
-
用户提问:根据用户输入的自然语言问题,系统会通过向量数据库递归检索与用户问题最相关的PolarDB相关内容,检索的文档切片作为上下文输入提示和归纳回复
-
答案输出:结合存储的历史提问上下文信息,规范重写“问题”,并生成和输出相应的答案。
支持的功能
目前实现的PolarDB社区机器人具有以下的功能:
-
支持知识库的安全上传和方便管理,并支持投放用户群的知识库配置
-
开源数据库使用、编码、PolarDB社区相关问题的回答能力。支持对于传统SQL代码转换为PolarDB-X的分布式查询代码
-
具备对语料良好准确的理解、总结、概括、阐述能力,针对用户发起的问题,提供专业准确的回答和畅通的对话
-
机器人支持多种服务场景:提供API接口,支持多渠道能力接入和投放
-
指定场景下支持用户的回复反馈,包括点赞和纠正交互入口
-
机器人基于收集到的社区问题,能够对数据进行有效统计用于效果分析
项目挑战
在项目开发过程中,为了取得良好的问答效果,也遇到了各种各样的问题,其中主要有以下三点:
历史对话未有效利用
在一定周期内,不同用户会提出类似的问题,传统RAG框架并未对社区对话历史和用户反馈进行建模,导致历史对话数据未有效利用,未发挥历史数据价值,影响服务效率。
不清晰问题引起的检索困难
用户的问题由于口语表达的不规范导致问题存在关键信息缺失、或者产生歧义(对话式交互可能需要结合历史上下文才能完整理解)、导致检索不到有效的内容,影响生成结果的准确性。
SQL开发相关问题复杂
数据库产品使用过程中,会涉及比较多的SQL开发相关问题,用户往往问询某一个具体SQL语句,而这一任务通常涉及到复杂的问题解析和SQL语法的使用。
针对以上问题,我们分别采取了以下解决方案:
实时收集社区问答记录,对问题进行关键词识别和聚类建模,挖掘历史问答数据价值。当社区内再次有相似的问题出现时,我们将直接检索出相似的历史已解决问题或返回高赞回复。这样的策略在提升系统的响应速率和准确性上均有一定效果。同时利用历史对话数据建模,可对模糊问题进行规范重写。
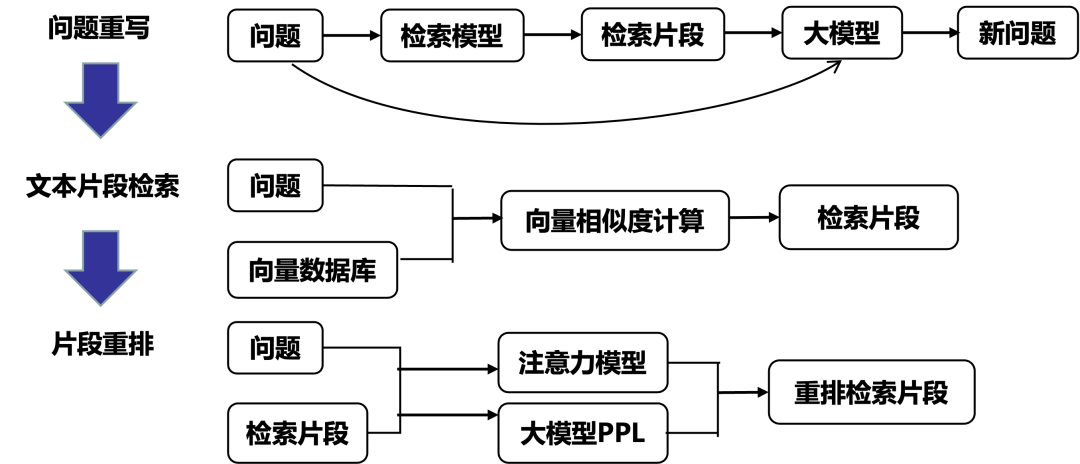
采取多种策略对问题进行重写和转述:
-
首先,我们通过伪相关片段,其包含和问题高度相关的信息,这些信息可以帮助消除查询歧义并生成清晰的新问题。
-
接着,我们利用低维稠密向量来表示问题,使得这个向量能够表达问题语义,通过计算向量的相似度反映问题与片段之间的相似性。
-
最后,在得到少量检索片段之后利用更加精细的排序方式,如注意力模型和使用大模型回复困惑度反向判断检索片段的精确度,得到重排之后的检索片段。
文本转SQL语句的流程中融入语句纠错能力,对生成的SQL语句进行二次验证,使生成的SQL语句尽可能地准确和完整。这是针对数据库查询类问题的创新探索。
总结
目前我们的机器人已经投放在PolarDB开源社区PolarDB-X技术交流钉群,相关服务能力在持续优化,欢迎开源社区的朋友使用并提出意见!
如果您对分布式数据库感兴趣,并想体验相关服务,可以通过扫码加入钉群:


















 3148
3148

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









