







2月22日,2025GDC“浦江AI生态论坛”在上海徐汇举行。论坛现场,大模型开放评测平台司南正式发布“以人为本”(Human-Centric Eval)的大模型评测体系,系统评估大模型能力对人类社会的实际价值,为人工智能应用更贴近人类需求,提供可量化的人本评估标注
司南团队突破性引入认知科学理论,秉持“以人为本”的核心精神,提出“解决问题能力、信息质量、交互体验”三维度的大模型主观评测体系。通过构建真实场景任务链与人机协同解决方案,最终由人类对模型辅助能力进行感知评分,从而实现技术指标与人文价值的有机统一。
该评测体系将于3月5日上线司南大模型竞技场,欢迎体验。
评测入口:https://opencompass.org.cn
认知科学驱动:从技术性能到人文价值
随着大模型等AI技术的飞速演进,各类AI技术已日渐融入人类生活场景,如何让AI更贴近人类需求,成为新阶段大模型能力提升的关键之一。司南团队认为,大模型最终要服务于人,因此“以人为本”的主观评估范式,将有效反映大模型的真正价值。
在传统的大模型基准测试中,普遍采用结果导向的评价标准,这种评价方式虽然能够直观地反映模型的性能,却忽略了人类的实际需求。在司南团队提出的评测方案中,从人类需求设计实际问题,让人与大模型协作解决,再由人类对模型的辅助能力进行主观评分,以此补充客观评价的不足,使评估更贴合人类感知。
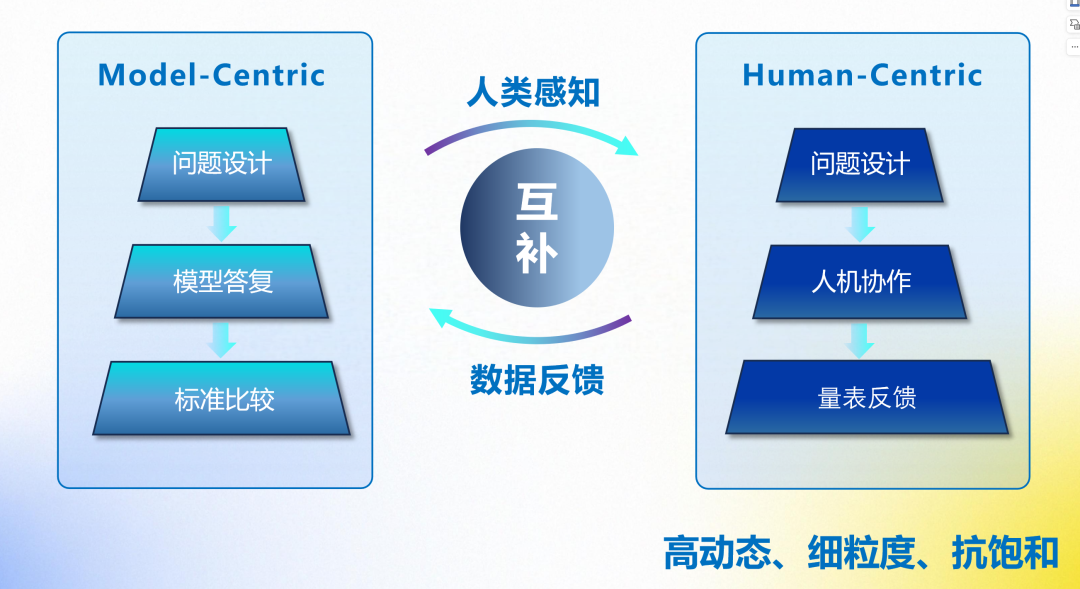
“以人为本”的评测体系将人类感知与数据反馈互补,实现技术指标与人文价值的有机统一
其中“认知科学驱动”评估框架,围绕解决问题能力、信息质量、交互体验三大核心维度,构建覆盖多场景、多领域的主观评测体系。通过模拟真实人类需求(如学术研究、数据分析、决策支持等),由用户与大模型协作完成任务,并基于人类主观反馈量化评估模型的实际应用价值,为下一步技术研发与产业落地提供了科学参考。
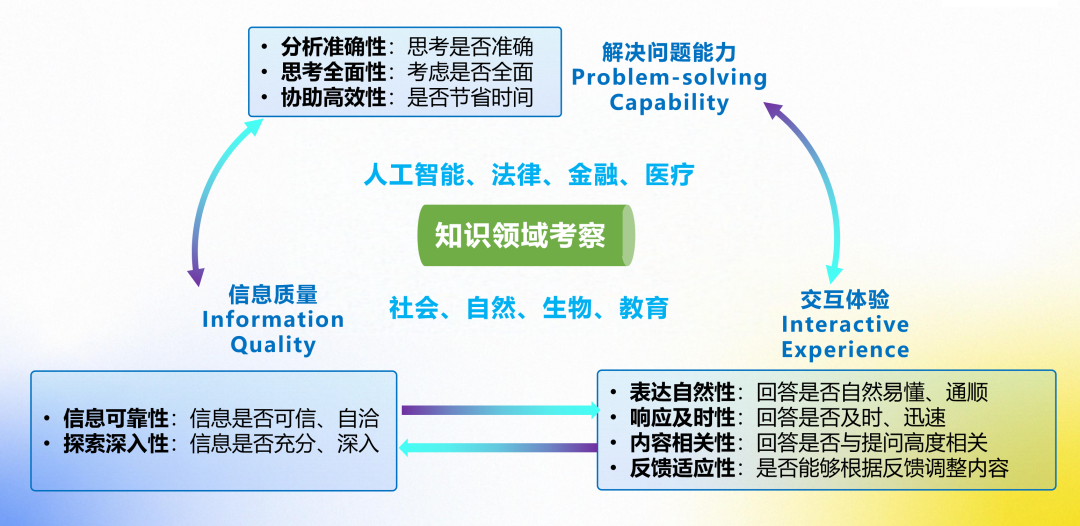
模拟真实人类需求,由用户与大模型协作完成评测
科研应用价值评估:主流模型准确分析能力均势,学科偏好存在分野
为了验证“以人为本”评估方式的有效性,同时评测大模型在研究生学术研究中的应用价值,司南团队选取了当前公认的优秀模型DeepSeek-R1、GPT-o3-mini、Grok-3作为评测对象,组织有学术研究需求的研究生参与。司南团队根据文献综述、数据分析、可行性研究等学术研究中的常见需求,设计了人工智能、法律、金融等8个领域的相关问题,使研究生与大模型协作解决。
参与评测的研究生与模型进行多轮交流,从解决问题能力、信息质量和交互体验三个主观维度对大模型打分,衡量其实际应用表现。
实验结果显示,所有受测模型分析准确性、思考全面性、协助高效性维度能力均势。DeepSeek-R1在解决生物、教育学科问题上表现突出;Grok-3在金融、自然领域优势明显;GPT-o3-mini则在社会领域表现良好,当前主流大模型已显示出学科偏好分野。与此同时,部分模型因服务负载过高导致响应延迟,未来在技术落地中,可着重解决此工程瓶颈。
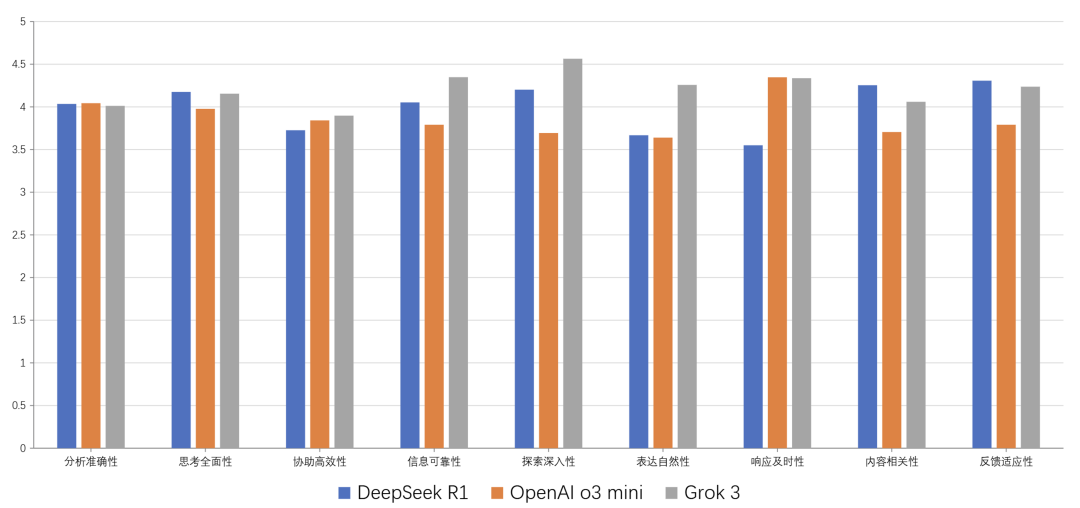
“以人为本”视角下的主流模型的多维度评估结果
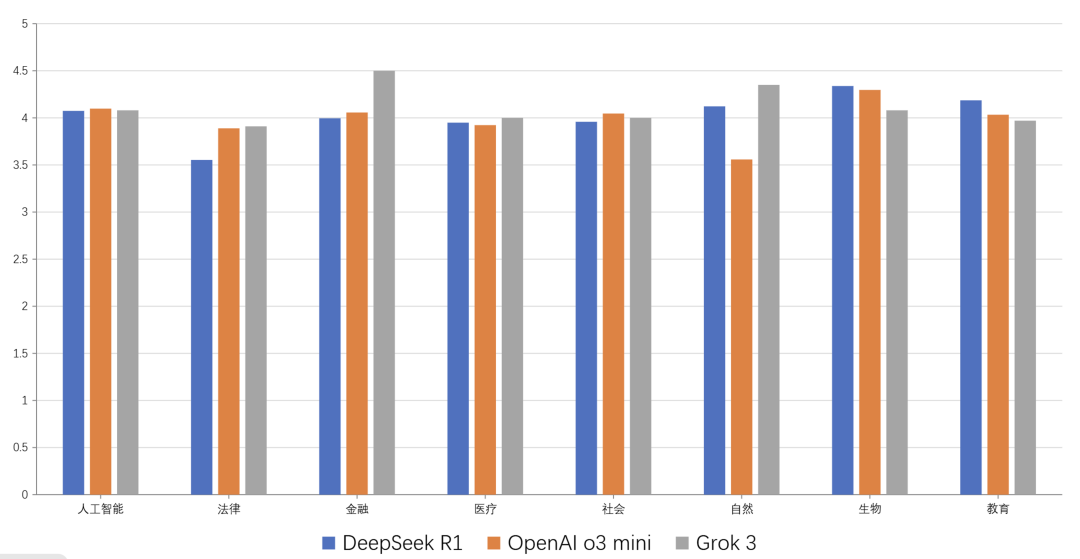
“以人为本”视角下的跨学科维度评估结果
开放共建:以评测推动大模型生态创新
作为面向大模型的开源方、厂商和使用者的评测体系及开放平台,司南为大语言模型、多模态模型等各类模型提供一站式评测工具。全面评测模型在语言、 知识、推理、数学、代码、指令跟随、智能体等能力维度的表现,客观中立地为大模型技术创新提供坚实的技术支撑。
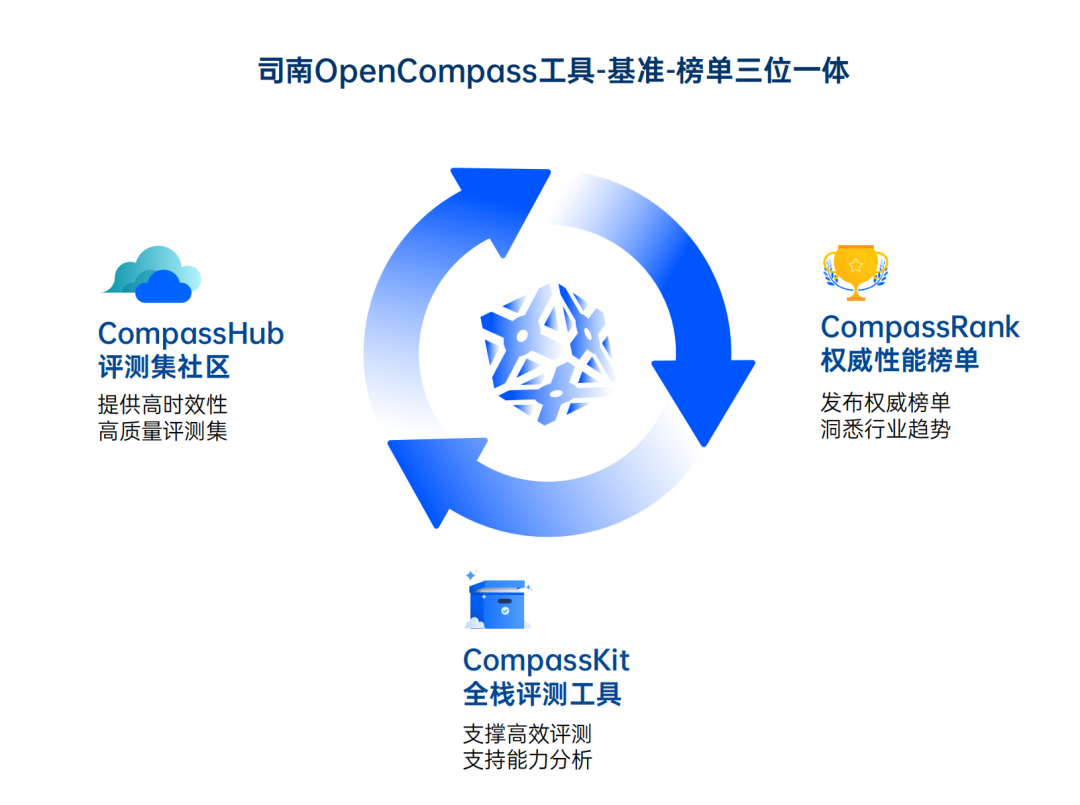
目前,司南已形成“工具-基准-榜单”三位一体的评测格局,成为开源社区最完善的评测体系之一,共构建并收录超过200个评测集及超50万道题目,参与评测的各类大模型超150个,30余家国内外大模型厂商及科研机构采用司南助力技术研发。同时,司南还成为大模型评测国标主要参与方,作为唯一的国产大模型评测机构,获得Meta官方推荐。未来,司南将持续巩固并拓展评测基准,与业界开放共建,以科学中立评测,推动AI生态繁荣。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









