







- metric API的使用
- bucketing API的使用
- 两类API的嵌套使用
1. 聚合API
ES中的Aggregations API是从Facets功能基础上发展而来,官网正在进行替换计划,建议用户使用Aggregations API,而不是Facets API。ES中的聚合上可以分为下面两类:
- metric(度量)聚合:度量类型聚合主要针对的number类型的数据,需要ES做比较多的计算工作
- bucketing(桶)聚合:划分不同的“桶”,将数据分配到不同的“桶”里。非常类似sql中的group语句的含义。
metric既可以作用在整个数据集上,也可以作为bucketing的子聚合作用在每一个“桶”中的数据集上。当然,我们可以把整个数据集合看做一个大“桶”,所有的数据都分配到这个大“桶”中。
ES中的聚合API的调用格式如下:

前言
说完了ES的索引与检索,接着再介绍一个ES高级功能API – 聚合(Aggregations),聚合功能为ES注入了统计分析的血统,使用户在面对大数据提取统计指标时变得游刃有余。同样的工作,你在hadoop中可能需要写mapreduce或hive,在mongo中你必须得用大段的mapreduce脚本,而在ES中仅仅调用一个API就能实现了。
开始之前,提醒老司机们注意,ES原有的聚合功能Facets在新版本中将被正式被移除,抓紧时间用Aggregations替换Facets吧。Facets真的很慢!
1 关于Aggregations
Aggregations的部分特性类似于SQL语言中的group by,avg,sum等函数。但Aggregations API还提供了更加复杂的统计分析接口。
掌握Aggregations需要理解两个概念:
- 桶(Buckets):符合条件的文档的集合,相当于SQL中的group by。比如,在users表中,按“地区”聚合,一个人将被分到北京桶或上海桶或其他桶里;按“性别”聚合,一个人将被分到男桶或女桶
- 指标(Metrics):基于Buckets的基础上进行统计分析,相当于SQL中的count,avg,sum等。比如,按“地区”聚合,计算每个地区的人数,平均年龄等
对照一条SQL来加深我们的理解:
|
1
|
SELECT COUNT(color) FROM table GROUP BY color
|
GROUP BY相当于做分桶的工作,COUNT是统计指标。
下面介绍一些常用的Aggregations API。
现在我们有了一些数据,来创建一个聚合吧。一个汽车交易商也许希望知道哪种颜色的车卖的最好。这可以通过一个简单的聚合完成。使用terms桶:
|
1
2
3
4
5
6
7
8
9
10
11
|
GET /cars/transactions/_search
{
"aggs"
: {
"colors"
: {
"terms"
: {
"field"
:
"color"
}
}
},
"size"
:
0
}
|
因为我们并不关心搜索结果,使用的"size": 0。聚合工作在顶层的aggs参数下(当然你也可以使用更长的aggregations)。 然后给这个聚合起了一个名字:colors。 最后,我们定义了一个terms类型的桶,它针对color字段。
聚合是以搜索结果为上下文而执行的,这意味着它是搜索请求(比如,使用/_search端点)中的另一个顶层参数(Top-level Parameter)。聚合可以和查询同时使用,这一点我们在后续的范围聚合(Scoping Aggregations)中介绍。
接下来我们为聚合起一个名字。命名规则是有你决定的; 聚合的响应会被该名字标记,因此在应用中你就能够根据名字来得到聚合结果,并对它们进行操作了。
然后,我们开始定义聚合本身。比如,我们定义了一个terms类型的桶。terms桶会动态地为每一个它遇到的不重复的词条创建一个新的桶。因为我们针对的是color字段,那么terms桶会动态地为每种颜色创建一个新桶。
如果执行出现报错,搜了一下应该是5.x后对排序,聚合这些操作用单独的数据结构(fielddata)缓存到内存里了,需要单独开启,简单来说就是在聚合前执行如下操作
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
<code>PUT cars/_mapping/transactions
{
"properties"
: {
"color"
: {
"type"
:
"text"
,
"fielddata"
:
true
}
}
}
PUT cars/_mapping/transactions
{
"properties"
: {
"make"
: {
"type"
:
"text"
,
"fielddata"
:
true
}
}
}</code>
|
让我们执行该聚合来看看其结果:

因为我们使用的"size": 0,所以没有搜索结果被返回。 每个桶中的key对应的是在colZ喎�"/kf/ware/vc/" target="_blank" class="keylink">vctfWts7W0NXStb21xLK71ti4tLXEtMrM9aGjy/zNrMqx0rKw/LqswcvSu7j2ZG9jX2NvdW50o6zTw8C0se3KvrD8uqzBy7jDtMrM9bXEzsS1tcr9wb+hozwvY29kZT48L2NvZGU+PC9wPg0KPHA+PGNvZGU+PGNvZGU+z+zTprD8uqzBy9K7uPbNsMHQse2jrMO/uPbNsLa8ttTTptfF0ru49rK71ti4tLXE0dXJqyixyMjno6y67Mmru/LV38LMyaspoaPDv7j2zbDSsrD8uqzByyZsZHF1bzu19MjrJnJkcXVvO7jDzbDW0LXEzsS1tcr9wb+ho7HIyOejrNPQNMG+uuzJq7XEs7WhozwvY29kZT48L2NvZGU+PC9wPg0KPHA+PGNvZGU+PGNvZGU+x7DD5rXEwP3X08rHzerIq8q1yrEoUmVhbC1UaW1lKbXEo7rI57n7zsS1tcrHv8nL0cv3tcSjrMTHw7TL/MPHvs3E3Lm7sbu+27rPoaPV4tLizrbXxcTjxNy5u72rxMO1vbXEvtu6z73hufvWw8jrtb3Su7j2zbzQzr/i1tDAtMn6s8nKtcqxtcTSx7HtsOUoRGFzaGJvYXJkKaGj0ru1qcTjwvSz9sHL0rvMqNL4yavG+7O1o6zU2s280M7Jz7nY09rS+MmrxvuztbXEzbO8xsr9vt2+zbvhsbu2r8ystdi4/NDCoaM8L2NvZGU+PC9jb2RlPjwvcD4NCjxociAvPg0KPGgxIGlkPQ=="添加一个指标metric">添加一个指标(Metric)
从前面的例子中,我们可以知道每个桶中的文档数量。但是,通常我们的应用会需要基于那些文档的更加复杂的指标(Metric)。比如,每个桶中的汽车的平均价格是多少?
为了得到该信息,我们得告诉ES需要为哪些字段计算哪些指标。这需要将指标嵌套到桶中。指标会基于桶中的文档的值来计算相应的统计信息。
让我们添加一个计算平均值的指标:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
<code><code>GET /cars/transactions/_search
{
"aggs"
:
{
"colors"
:
{
"terms"
:
{
"field"
:
"color"
},
"aggs"
:
{
"avg_price"
:
{
"avg"
: {
"field"
:
"price"
}
}
}
}
},
"size"
:
0
}</code></code>
|
我们添加了一个新的aggs层级来包含该指标。然后给该指标起了一个名字:avg_price。最后定义了该指标作用的字段为price。.
正如你所看到的,我们向前面的例子中添加了一个新的aggs层级。这个新的聚合层级能够让我们将avg指标嵌套在terms桶中。这意味着我们能为每种颜色都计算一个平均值。
同样的,我们需要给指标起一个名(avg_price)来让我们能够在将来得到其值。最后,我们指定了指标本身(avg)以及该指标作用的字段(price):

现在,在响应中多了一个avg_price元素。
尽管得到的响应只是稍稍有些变化,但是获得的数据增加的了许多。之前我们只知道有4辆红色汽车。现在我们知道了红色汽车的平均价格是32500刀。这些数据你可以直接插入到报表中。
桶中的桶(Buckets inside Buckets)
当你开始使用不同的嵌套模式时,聚合强大的能力才会显现出来。在前面的例子中,我们已经知道了如何将一个指标嵌套进一个桶的,它的功能已经十分强大了。
但是真正激动人心的分析功能来源于嵌套在其它桶中的桶。现在,让我们来看看如何找到每种颜色的汽车的制造商分布信息:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
<code><code>GET /cars/transactions/_search
{
"aggs"
:
{
"colors"
: {
"terms"
: {
"field"
:
"color"
},
"aggs"
:
{
"avg_price"
: {
"avg"
: {
"field"
:
"price"
}
},
"make"
: {
"terms"
: {
"field"
:
"make"
}
}
}
}
},
"size"
:
0
}</code></code>
|
此时发生了一些有意思的事情。首先,你会注意到前面的avg_price指标完全没有变化。一个聚合的每个层级都能够拥有多个指标或者桶。avg_price指标告诉了我们每种汽车颜色的平均价格。为每种颜色创建的桶和指标是各自独立的。
这个性质对你的应用而言是很重要的,因为你经常需要收集一些互相关联却又完全不同的指标。聚合能够让你对数据遍历一次就得到所有需要的信息。
另外一件重要的事情是添加了新聚合make,它是一个terms类型的桶(嵌套在名为colors的terms桶中)。这意味着我们会根据数据集创建不重复的(color, make)组合。
让我们来看看得到的响应:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
|
<code><code>{
"took"
:
12
,
"timed_out"
:
false
,
"_shards"
: {
"total"
:
5
,
"successful"
:
5
,
"failed"
:
0
},
"hits"
: {
"total"
:
8
,
"max_score"
:
0
,
"hits"
: []
},
"aggregations"
: {
"colors"
: {
"doc_count_error_upper_bound"
:
0
,
"sum_other_doc_count"
:
0
,
"buckets"
: [
{
"key"
:
"red"
,
"doc_count"
:
4
,
"avg_price"
: {
"value"
:
32500
},
"make"
: {
"doc_count_error_upper_bound"
:
0
,
"sum_other_doc_count"
:
0
,
"buckets"
: [
{
"key"
:
"honda"
,
"doc_count"
:
3
},
{
"key"
:
"bmw"
,
"doc_count"
:
1
}
]
}
},
{
"key"
:
"blue"
,
"doc_count"
:
2
,
"avg_price"
: {
"value"
:
20000
},
"make"
: {
"doc_count_error_upper_bound"
:
0
,
"sum_other_doc_count"
:
0
,
"buckets"
: [
{
"key"
:
"ford"
,
"doc_count"
:
1
},
{
"key"
:
"toyota"
,
"doc_count"
:
1
}
]
}
},
{
"key"
:
"green"
,
"doc_count"
:
2
,
"avg_price"
: {
"value"
:
21000
},
"make"
: {
"doc_count_error_upper_bound"
:
0
,
"sum_other_doc_count"
:
0
,
"buckets"
: [
{
"key"
:
"ford"
,
"doc_count"
:
1
},
{
"key"
:
"toyota"
,
"doc_count"
:
1
}
]
}
}
]
}
}
}</code></code>
|
该响应告诉了我们如下信息:
|
1
2
3
4
|
<code><code><code>有
4
辆红色汽车。
红色汽车的平均价格是
32500
美刀。
红色汽车中的
3
辆是Honda,
1
辆是BMW。
</code></code></code>
|
最后的一个修改(One Final Modification)
在继续讨论新的话题前,为了把问题讲清楚让我们对该例子进行最后一个修改。为每个制造商添加两个指标来计算最低和最高价格:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
<code><code><code>GET /cars/transactions/_search
{
"aggs"
: {
"colors"
: {
"terms"
: {
"field"
:
"color"
},
"aggs"
: {
"avg_price"
: {
"avg"
: {
"field"
:
"price"
}
},
"make"
: {
"terms"
: {
"field"
:
"make"
},
"aggs"
: {
"min_price"
: {
"min"
: {
"field"
:
"price"
} },
"max_price"
: {
"max"
: {
"field"
:
"price"
} }
}
}
}
}
},
"size"
:
0
}</code></code></code>
|
我们需要添加另一个aggs层级来进行对min和max的嵌套。
得到的响应如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
|
<code><code><code>{
"took"
:
23
,
"timed_out"
:
false
,
"_shards"
: {
"total"
:
5
,
"successful"
:
5
,
"failed"
:
0
},
"hits"
: {
"total"
:
8
,
"max_score"
:
0
,
"hits"
: []
},
"aggregations"
: {
"colors"
: {
"doc_count_error_upper_bound"
:
0
,
"sum_other_doc_count"
:
0
,
"buckets"
: [
{
"key"
:
"red"
,
"doc_count"
:
4
,
"avg_price"
: {
"value"
:
32500
},
"make"
: {
"doc_count_error_upper_bound"
:
0
,
"sum_other_doc_count"
:
0
,
"buckets"
: [
{
"key"
:
"honda"
,
"doc_count"
:
3
,
"max_price"
: {
"value"
:
20000
},
"min_price"
: {
"value"
:
10000
}
},
{
"key"
:
"bmw"
,
"doc_count"
:
1
,
"max_price"
: {
"value"
:
80000
},
"min_price"
: {
"value"
:
80000
}
}
]
}
},
{
"key"
:
"blue"
,
"doc_count"
:
2
,
"avg_price"
: {
"value"
:
20000
},
"make"
: {
"doc_count_error_upper_bound"
:
0
,
"sum_other_doc_count"
:
0
,
"buckets"
: [
{
"key"
:
"ford"
,
"doc_count"
:
1
,
"max_price"
: {
"value"
:
25000
},
"min_price"
: {
"value"
:
25000
}
},
{
"key"
:
"toyota"
,
"doc_count"
:
1
,
"max_price"
: {
"value"
:
15000
},
"min_price"
: {
"value"
:
15000
}
}
]
}
},
{
"key"
:
"green"
,
"doc_count"
:
2
,
"avg_price"
: {
"value"
:
21000
},
"make"
: {
"doc_count_error_upper_bound"
:
0
,
"sum_other_doc_count"
:
0
,
"buckets"
: [
{
"key"
:
"ford"
,
"doc_count"
:
1
,
"max_price"
: {
"value"
:
30000
},
"min_price"
: {
"value"
:
30000
}
},
{
"key"
:
"toyota"
,
"doc_count"
:
1
,
"max_price"
: {
"value"
:
12000
},
"min_price"
: {
"value"
:
12000
}
}
]
}
}
]
}
}
}</code></code></code>
|
在每个make桶下,多了min和max的指标。
此时,我们可以得到如下信息:
|
1
2
3
4
5
6
|
<code><code><code><code>有
4
辆红色汽车。
红色汽车的平均价格是
32500
美刀。
红色汽车中的
3
辆是Honda,
1
辆是BMW。
红色Honda汽车中,最便宜的价格为
10000
美刀。
最贵的红色Honda汽车为
20000
美刀。
</code></code></code></code>
|
一、Elasticsearch的聚合
ES的聚合相当于关系型数据库里面的group by,例如查找在性别字段男女人数的多少并且按照人数的多少进行排序,在使用mysql的时候,可以使用如下的句子
在ES里面想要实现这种的语句,就叫做聚合,比如这种的聚合使用DSL语句的话如下所示:
这样就可以实现最以上例子中的group by的功能,当然这只是最简单的聚合的使用,在ES里面的聚合有多重多样的,比如说有度量聚合,可以用来计算某一个字段的平均值最大值等,在此给出一个简单的度量聚合的例子
这个DSL语句就是将先按照性别进行聚合,并且对不同的性别给出一个平均的年龄,使用之后ES的给出结果如下所示:
在度量聚合里面有min,max,sum,avg聚合等,还有stats,extern_stats等聚合,其中stats的聚合给出的信息会包括min,max,count等基本的信息,更多详细的细节请参考ES官网给出的指导https://www.elastic.co/guide/en/elasticsearch/guide/current/aggregations.html
以上只是给出的度量聚合,但是在实际中我们经常使用的是桶聚合,什么是桶聚合呢,个人理解就是将符合某一类条件的文档选出来,所有的某一类的聚合就称为桶,例如你可以按照某一个分类将所有的商品聚合起来,这种情况下就可以认为某一个分类的商品称为一个桶,下面将详细介绍几个常用的桶聚合,并且会给出java使用时候的代码
二、桶聚合
桶聚合是在实际使用时候用处比较多的一种聚合,简单的桶聚合包括term聚合,range聚合,date聚合,IPV4聚合等聚合,因为自己使用的仅仅是其中的三个,在此就简单的介绍三个,分别是term聚合,range聚合,以及date聚合
1、term聚合
term聚合就是第一部分给出的简单的例子,按照不同的字段进行聚合
2、range聚合
range聚合为按照自定义的范围来创造桶,将每一个范围的数据进行聚合,并且这个聚合一般适用于字段类型为long或者int,double的字段,可以进行直接的聚合,例如,我们想统计不同年龄段的人的个数,DSL如下所示:
3、daterange聚合
date range聚合和range聚合类似,但是所使用的类型是datetime这种类型,使用的时候与range有些区别,给出一个简单的使用date range聚合的DSL例子,如下所示:
上面的DSL是简单的按照时间格式进行区间的聚合,但是有些时候我们可能想要一些按照年份聚合或者月份聚合的情况,这个时候应该怎么办呢?在date range里面可以指定日期的格式,例如下面给出一个按照年份进行聚合的例子:
我们可以指定格式来进行聚合
三、对于上述三种聚合java的实现
首先先给出一个具体的使用ES java api实现搜索并且聚合的完整例子,例子中使用的是terms聚合,按照分类id,将所有的分类进行聚合
以上的例子实现的是按照category_id字段进行分类的聚合,并且将在name字段查找包含“中学历史”的这个词,并且按照category_id进行排序,在此给出的只是一个搜索实现的函数,里面的字段名字,以及index,type等很多字段均为自己定义的index里面的名字,上面给出的是terms聚合时候的代码,如果使用的是range聚合或者date range聚合,只需要改变 aggregation就可以
使用range聚合的时候:
使用date range聚合的时候:
以上所有的聚合均是先过滤搜索,然后对于召回得到的结果进行一个聚合,例如我们在name字段搜索中学历史这个词,最终得到四个分类分别为1,2,3,4那么聚合的时候就是这四个分类,但是有时候我们可能会需要对于搜索的结果进行一个过滤,但是我们不想对聚合的结果进行过滤,那么我们就要使用一下的部分了
四、先聚合再过滤
以上将的简单的聚合都是先过滤或者搜索,然后对结果进行聚合,但是有时候我们需要先进行聚合,然后再对结果进行一次过滤,但是我们不希望这个时候聚合会发生变化,什么时候会遇到这种情况呢,我们以美团为例做一个说明,在主页我们直接点解美食,得到如下所示的图
点美食之后出现全部的分类,包括各种的菜系,下面我们点一个具体的菜系
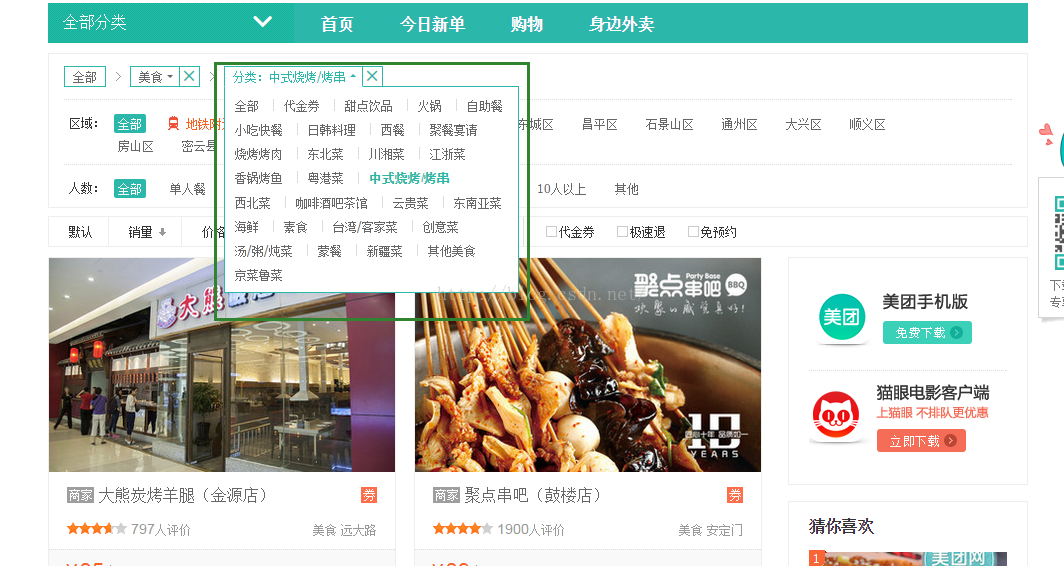
从程序上来说,我们点第二次菜系的时候,出现的所有的菜品均是烤串之类的菜品了,但是在分类里面还是所有的分类都会有,如果按照之前的ES的聚合,会将所有搜索出来的品的分类进行一个聚合,但是点完烤串之后,所有的分类都是烤串了,那么就应该所有的分类只有一个烤串了,不应该有其他的,这样的话肯定是不可以的,那么如何才能实现这种聚合的,这个时候我们就需要先聚合,然后进行再次的过滤,但是过滤的时候并不影响之前的聚合结果,这就是先聚合再过滤,在ES里面也有这种情况的考虑,这个时候使用的是postfilter
postfilter解决了仅仅过滤搜索结果,但是并不影响聚合结果,下面给出一个java使用时候的例子以及比较
函数一为第三部分给出的完整的搜索函数,按照分类聚合
函数二的改变只是对于一的
添加了按照price进行过滤,最后结果显示,聚合的结果两次完全一样,但是函数二召回的结果为函数一结果的子集
2 Metrics
2.1 AVG
求均值。
|
1
2
3
4
5
6
|
GET /company/employee/_search
{
"aggs" : {
"avg_grade" : { "avg" : { "field" : "grade" } }
}
}
|
执行结果
|
1
2
3
4
5
|
{
"aggregations": {
"avg_grade": {"value": 75}
}
}
|
其他的简单统计API,如valuecount, max,min,sum作用与SQL中类似,就不一一解释了。
2.2 Cardinality
cardinality的作用是先执行类似SQL中的distinct操作,然后再统计排重后集合长度。得到的结果是一个近似值,因为考虑到在大量分片中排重的性能损耗Cardinality算法并不会load所有的数据。
|
1
2
3
4
5
6
7
|
{
"aggs" : {
"author_count" : {
"cardinality" : {"field" : "author"}
}
}
}
|
2.3 Stats
返回聚合分析后所有有关stat的指标。具体哪些是stat指标是ES定义的,共有5项。
|
1
2
3
4
5
|
{
"aggs" : {
"grades_stats" : { "stats" : { "field" : "grade" } }
}
}
|
执行结果
|
1
2
3
4
5
6
7
8
9
10
11
|
{
"aggregations": {
"grades_stats": {
"count": 6,
"min": 60,
"max": 98,
"avg": 78.5,
"sum": 471
}
}
}
|
2.4 Extended Stats
返回聚合分析后所有指标,比Stats多三个统计结果:平方和、方差、标准差
|
1
2
3
4
5
|
{
"aggs" : {
"grades_stats" : { "extended_stats" : { "field" : "grade" } }
}
}
|
执行结果
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
{
"aggregations": {
"grade_stats": {
"count": 9,
"min": 72,
"max": 99,
"avg": 86,
"sum": 774,
# 平方和
"sum_of_squares": 67028,
# 方差
"variance": 51.55555555555556,
# 标准差
"std_deviation": 7.180219742846005,
#平均加/减两个标准差的区间,用于可视化你的数据方差
"std_deviation_bounds": {
"upper": 100.36043948569201,
"lower": 71.63956051430799
}
}
}
}
|
2.5 Percentiles
百分位法统计,举例,运维人员记录了每次启动系统所需要的时间,或者,网站记录了每次用户访问的页面加载时间,然后对这些时间数据进行百分位法统计。我们在测试报告中经常会看到类似的统计数据
|
1
2
3
4
5
6
7
|
{
"aggs" : {
"load_time_outlier" : {
"percentiles" : {"field" : "load_time"}
}
}
}
|
结果是
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
{
"aggregations": {
"load_time_outlier": {
"values" : {
"1.0": 15,
"5.0": 20,
"25.0": 23,
"50.0": 25,
"75.0": 29,
"95.0": 60,
"99.0": 150
}
}
}
}
|
加载时间在15ms内的占1%,20ms内的占5%,等等。
我们还可以指定百分位的指标,比如只想统计95%、99%、99.9%的加载时间
|
1
2
3
4
5
6
7
8
9
10
|
{
"aggs" : {
"load_time_outlier" : {
"percentiles" : {
"field" : "load_time",
"percents" : [95, 99, 99.9]
}
}
}
}
|
2.6 Percentile Ranks
Percentile API中,返回结果values中的key是固定的0-100间的值,而Percentile Ranks返回值中的value才是固定的,同样也是0到100。例如,我想知道加载时间是15ms与30ms的数据,在所有记录中处于什么水平,以这种方式反映数据在集合中的排名情况。
|
1
2
3
4
5
6
7
8
9
10
|
{
"aggs" : {
"load_time_outlier" : {
"percentile_ranks" : {
"field" : "load_time",
"values" : [15, 30]
}
}
}
}
|
执行结果
|
1
2
3
4
5
6
7
8
9
10
|
{
"aggregations": {
"load_time_outlier": {
"values" : {
"15": 92,
"30": 100
}
}
}
}
|
3 Bucket
3.1 Filter
先过滤后聚合,类似SQL中的where,也有点象group by后加having。比如
|
1
2
3
4
5
6
7
8
9
10
|
{
"aggs" : {
"red_products" : {
"filter" : { "term": { "color": "red" } },
"aggs" : {
"avg_price" : { "avg" : { "field" : "price" } }
}
}
}
}
|
只统计红色衣服的均价。
3.2 Range
反映数据的分布情况,比如我想知道小于50,50到100,大于100的数据的个数。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
{
"aggs" : {
"price_ranges" : {
"range" : {
"field" : "price",
"ranges" : [
{ "to" : 50 },
{ "from" : 50, "to" : 100 },
{ "from" : 100 }
]
}
}
}
}
|
执行结果
|
1
2
3
4
5
6
7
8
9
10
11
|
{
"aggregations": {
"price_ranges" : {
"buckets": [
{"to": 50, "doc_count": 2},
{"from": 50, "to": 100, "doc_count": 4},
{"from": 100, "doc_count": 4}
]
}
}
}
|
3.3 Missing
我们想找出price字段值为空的文档的个数。
|
1
2
3
4
5
6
7
|
{
"aggs" : {
"products_without_a_price" : {
"missing" : { "field" : "price" }
}
}
}
|
执行结果
|
1
2
3
4
5
6
7
|
{
"aggs" : {
"products_without_a_price" : {
"doc_count" : 10
}
}
}
|
3.4 Terms
针对某个字段排重后统计个数。
|
1
2
3
4
5
6
7
|
{
"aggs" : {
"genders" : {
"terms" : { "field" : "gender" }
}
}
}
|
执行结果
|
1
2
3
4
5
6
7
8
9
10
11
12
|
{
"aggregations" : {
"genders" : {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets" : [
{"key" : "male","doc_count" : 10},
{"key" : "female","doc_count" : 10},
]
}
}
}
|
3.5 Date Range
针对日期型数据做分布统计。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
{
"aggs": {
"range": {
"date_range": {
"field": "date",
"format": "MM-yyy",
"ranges": [
{ "to": "now-10M/M" },
{ "from": "now-10M/M" }
]
}
}
}
}
|
这里的format参数是指定返回值的日期格式。
执行结果
|
1
2
3
4
5
6
7
8
9
10
|
{
"aggregations": {
"range": {
"buckets": [
{"to": 1.3437792E+12, "to_as_string": "08-2012","doc_count": 7},
{"from": 1.3437792E+12, "from_as_string": "08-2012","doc_count": 2}
]
}
}
}
|
3.6 Global Aggregation
指定聚合的作用域与查询的作用域没有关联。因此返回结果中query命中的文档,与聚合的的统计结果是没有关系的。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
{
"query" : {
"match" : { "title" : "shirt" }
},
"aggs" : {
"all_products" : {
"global" : {},
"aggs" : {
"avg_price" : { "avg" : { "field" : "price" } }
}
}
}
}
|
3.7 Histogram
跟range类似,不过Histogram不需要你指定统计区间,只需要提供一个间隔区间的值。好象不太好理解,看个例子就全明白了。
比如,以50元为一个区间,统计每个区间内的价格分布
|
1
2
3
4
5
6
7
8
9
10
|
{
"aggs" : {
"prices" : {
"histogram" : {
"field" : "price",
"interval" : 50
}
}
}
}
|
执行结果
|
1
2
3
4
5
6
7
8
9
10
11
12
|
{
"aggregations": {
"prices" : {
"buckets": [
{"key": 0, "doc_count": 2},
{"key": 50, "doc_count": 4},
{"key": 100, "doc_count": 0},
{"key": 150, "doc_count": 3}
]
}
}
}
|
由于最高的价格没超过200元,因此最后的结果自动分为小于50,50到100,100到150,大于150共四个区间的值。
100到150区间的文档数为0个,我们想在返回结果中自动过滤该值,或者过滤偏小的值,可以添加一个参数”min_doc_count”,比如
|
1
2
3
4
5
6
7
8
9
10
11
|
{
"aggs" : {
"prices" : {
"histogram" : {
"field" : "price",
"interval" : 50,
"min_doc_count" : 1
}
}
}
}
|
返回结果会自动将你设定的值以下的统计结果过滤出去。
3.8 Date Histogram
使用方法与Histogram类似,只是聚合的间隔区间是针对时间类型的字段。
|
1
2
3
4
5
6
7
8
9
10
11
|
{
"aggs" : {
"articles_over_time" : {
"date_histogram" : {
"field" : "date",
"interval" : "1M",
"format" : "yyyy-MM-dd"
}
}
}
}
|
执行结果
|
1
2
3
4
5
6
7
8
9
10
11
|
{
"aggregations": {
"articles_over_time": {
"buckets": [
{"key_as_string": "2013-02-02","key": 1328140800000, "doc_count": 1},
{"key_as_string": "2013-03-02","key": 1330646400000, "doc_count": 2},
...
]
}
}
}
|
3.9 IPv4 range
由于ES是一个企业级的搜索和分析的解决方案,在做大量数据统计分析时比如用户访问行为数据,会采集用户的IP地址,类似这样的数据(还有地理位置数据等),ES也提供了最直接的统计接口。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
{
"aggs" : {
"ip_ranges" : {
"ip_range" : {
"field" : "ip",
"ranges" : [
{ "to" : "10.0.0.5" },
{ "from" : "10.0.0.5" }
]
}
}
}
}
|
执行结果
|
1
2
3
4
5
6
7
8
9
10
|
{
"aggregations": {
"ip_ranges": {
"buckets" : [
{"to": 167772165, "to_as_string": "10.0.0.5","doc_count": 4},
{"from": 167772165,"from_as_string": "10.0.0.5","doc_count": 6}
]
}
}
}
|
3.10 Return only aggregation results
在统计分析时我们有时候并不需要知道命中了哪些文档,只需要将统计的结果返回给我们。因此我们可以在request body中添加配置参数size。
|
1
2
3
4
5
6
7
8
9
|
curl -XGET 'http://localhost:9200/twitter/tweet/_search' -d '{
"size": 0,
"aggregations": {
"my_agg": {
"terms": {"field": "text"}
}
}
}
'
|
4 聚合缓存
ES中经常使用到的聚合结果集可以被缓存起来,以便更快速的系统响应。这些缓存的结果集和你掠过缓存直接查询的结果是一样的。因为,第一次聚合的条件与结果缓存起来后,ES会判断你后续使用的聚合条件,如果聚合条件不变,并且检索的数据块未增更新,ES会自动返回缓存的结果。
注意聚合结果的缓存只针对size=0的请求(参考3.10章节),还有在聚合请求中使用了动态参数的比如Date Range中的now(参考3.5章节),ES同样不会缓存结果,因为聚合条件是动态的,即使缓存了结果也没用了。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









