







1:登录注册案例(理解)

分析
需求:用户登录注册案例。
按照如下的操作,可以让我们更符号面向对象思想
A:有哪些类呢?
B:每个类有哪些东西呢?
C:类与类之间的关系是什么呢?
分析:
A:有哪些类呢?
用户类
测试类
B:每个类有哪些东西呢?
用户类:
成员变量:用户名,密码
构造方法:无参构造
成员方法:getXxx()/setXxx()
登录,注册
假如用户类的内容比较对,将来维护起来就比较麻烦,为了更清晰的分类,我们就把用户又划分成了两类
用户基本描述类
成员变量:用户名,密码
构造方法:无参构造
成员方法:getXxx()/setXxx()
用户操作类
登录,注册
测试类:
main方法。
C:类与类之间的关系是什么呢?
在测试类中创建用户操作类和用户基本描述类的对象,并使用其功能。
分包:
A:功能划分
B:模块划分
C:先按模块划分,再按功能划分
今天我们选择按照功能划分:
用户基本描述类包 cn.itcast.pojo
用户操作接口 cn.itcast.dao
用户操作类包 cn.itcast.dao.impl
今天是集合实现,过几天是IO实现,再过几天是GUI实现,就业班我们就是数据库实现
用户测试类 cn.itcast.test2:Set集合(理解)
(1)Set集合的特点无序(存储顺序和取出顺序不一致),唯一
(2)HashSet集合(掌握)
A:底层数据结构是哈希表(是一个元素为链表的数组)Hash table
B:哈希表底层依赖两个方法:hashCode()和equals()
执行顺序:
首先比较哈希值是否相同
相同:继续执行equals()方法
返回true:元素重复了,不添加
返回false:直接把元素添加到集合
不同:就直接把元素添加到集合
C:如何保证元素唯一性的呢?
由hashCode()和equals()保证的
HashSet存储元素保证唯一性的代码及图解

E:HashSet存储字符串并遍历
F:HashSet存储自定义对象并遍历(对象的成员变量值相同即为同一个元素)
G:
* LinkedHashSet:底层数据结构由哈希表和链表组成。
* 哈希表保证元素的唯一性。
* 链表保证元素有素。(存储和取出是一致)
*/
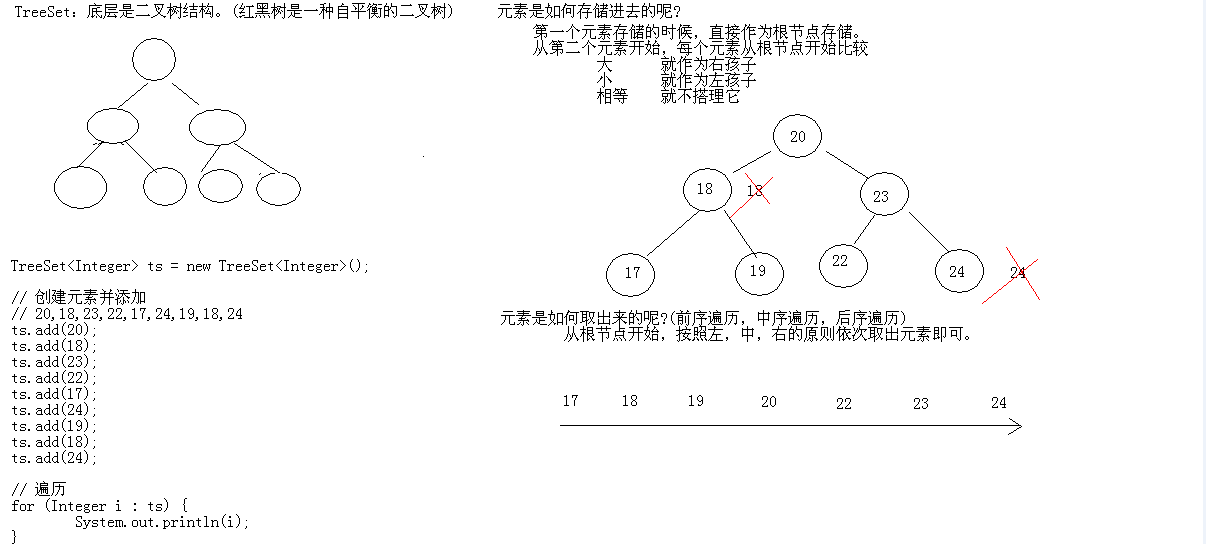
(3)TreeSet集合
A:底层数据结构是红黑树(是一个自平衡的二叉树)B:保证元素的排序方式
a:自然排序(元素具备比较性)
让元素所属的类实现Comparable接口
b:比较器排序(集合具备比较性)
让集合构造方法接收Comparator的实现类对象
TreeSet存储元素自然排序和唯一的图解
(4)案例:
A:获取无重复的随机数
import java.util.HashSet;
import java.util.Random;
/*
* 编写一个程序,获取10个1至20的随机数,要求随机数不能重复。
*
* 分析:
* A:创建随机数对象
* B:创建一个HashSet集合
* C:判断集合的长度是不是小于10
* 是:就创建一个随机数添加
* 否:不搭理它
* D:遍历HashSet集合
*/
public class HashSetDemo {
public static void main(String[] args) {
// 创建随机数对象
Random r = new Random();
// 创建一个Set集合
HashSet<Integer> ts = new HashSet<Integer>();
// 判断集合的长度是不是小于10
while (ts.size() < 10) {
int num = r.nextInt(20) + 1;
ts.add(num);
}
// 遍历Set集合
for (Integer i : ts) {
System.out.println(i);
}
}
}
B:键盘录入学生按照总分从高到底输出
学生类略
import java.util.Comparator;
import java.util.Scanner;
import java.util.TreeSet;
/*
* 键盘录入5个学生信息(姓名,语文成绩,数学成绩,英语成绩),按照总分从高到低输出到控制台
*
* 分析:
* A:定义学生类
* B:创建一个TreeSet集合
* C:总分从高到底如何实现呢?
* D:键盘录入5个学生信息
* E:遍历TreeSet集合
*/
public class TreeSetDemo {
public static void main(String[] args) {
// 创建一个TreeSet集合
TreeSet<Student> ts = new TreeSet<Student>(new Comparator<Student>() {
@Override
public int compare(Student s1, Student s2) {
// 总分从高到低
int num = s2.getSum() - s1.getSum();//public int getSum() {return this.chinese + this.math + this.english;}
// 总分相同的不一定语文相同
int num2 = num == 0 ? s1.getChinese() - s2.getChinese() : num;
// 总分相同的不一定数序相同
int num3 = num2 == 0 ? s1.getMath() - s2.getMath() : num2;
// 总分相同的不一定英语相同
int num4 = num3 == 0 ? s1.getEnglish() - s2.getEnglish() : num3;
// 姓名还不一定相同呢
int num5 = num4 == 0 ? s1.getName().compareTo(s2.getName())
: num4;
return num5;
}
});
System.out.println("学生信息录入开始");
// 键盘录入5个学生信息
for (int x = 1; x <= 5; x++) {
Scanner sc = new Scanner(System.in);
System.out.println("请输入第" + x + "个学生的姓名:");
String name = sc.nextLine();
System.out.println("请输入第" + x + "个学生的语文成绩:");
String chineseString = sc.nextLine();
System.out.println("请输入第" + x + "个学生的数学成绩:");
String mathString = sc.nextLine();
System.out.println("请输入第" + x + "个学生的英语成绩:");
String englishString = sc.nextLine();
// 把数据封装到学生对象中
Student s = new Student();
s.setName(name);
s.setChinese(Integer.parseInt(chineseString));
s.setMath(Integer.parseInt(mathString));
s.setEnglish(Integer.parseInt(englishString));
// 把学生对象添加到集合
ts.add(s);
}
System.out.println("学生信息录入完毕");
System.out.println("学习信息从高到低排序如下:");
System.out.println("姓名\t语文成绩\t数学成绩\t英语成绩");
// 遍历集合
for (Student s : ts) {
System.out.println(s.getName() + "\t" + s.getChinese() + "\t"
+ s.getMath() + "\t" + s.getEnglish());
}
}
}
3:Collection单列集合总结(掌握)
Collection
|--List 有序,可重复
|--ArrayList
底层数据结构是数组,查询快,增删慢。
线程不安全,效率高
|--Vector
底层数据结构是数组,查询快,增删慢。
线程安全,效率低
|--LinkedList
底层数据结构是链表,查询慢,增删快。
线程不安全,效率高
|--Set 无序,唯一
|--HashSet
底层数据结构是哈希表。
如何保证元素唯一性的呢?
依赖两个方法:hashCode()和equals()
开发中自动生成这两个方法即可
|--LinkedHashSet
底层数据结构是链表和哈希表
由链表保证元素有序
由哈希表保证元素唯一
|--TreeSet
底层数据结构是红黑树。
如何保证元素排序的呢?
自然排序
比较器排序
如何保证元素唯一性的呢?
根据比较的返回值是否是0来决定
4:针对Collection集合我们到底使用谁呢?(掌握)
唯一吗?
是:Set
排序吗?
是:TreeSet
否:HashSet
如果你知道是Set,但是不知道是哪个Set,就用HashSet。
否:List
要安全吗?
是:Vector
否:ArrayList或者LinkedList
查询多:ArrayList
增删多:LinkedList
如果你知道是List,但是不知道是哪个List,就用ArrayList。
如果你知道是Collection集合,但是不知道使用谁,就用ArrayList。
如果你知道用集合,就用ArrayList。
5:在集合中常见的数据结构(掌握)
ArrayXxx:底层数据结构是数组,查询快,增删慢
LinkedXxx:底层数据结构是链表,查询慢,增删快
HashXxx:底层数据结构是哈希表。依赖两个方法:hashCode()和equals()
TreeXxx:底层数据结构是二叉树。两种方式排序:自然排序和比较器排序















 217
217

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









