







linux arm架构下的栈回溯主要有两种方式,一种是基于fp栈帧寄存器的栈回溯,还有一种是unwind形式的栈回溯。
1 基于fp栈帧寄存器的栈回溯
在介绍栈回溯原理前,先贴一下arm的基本寄存器:
| 寄存器 | 含义 |
| r0-r3 | 用作函数传参,例如函数A调用函数B,如果A需要向B传递参数,则将参数放到寄存器r0-r3中,如果参数个数大于4,则需要借用函数的栈空间。 |
| r4-r11 | 变量寄存器,在函数中可以用来保存临时变量。 |
| r9(SB) | 静态基址寄存器。 |
| r10(SL) | 栈界限寄存器。 |
| r11(FP) | 帧指针寄存器,通常用来访问函数栈,帧指针指向函数栈中的某个位置。 |
| r12(IP) | 内部过程调用暂存寄存器。 |
| r13(SP) | 栈指针寄存器,用来指向函数栈的栈顶。 |
| r14(LR) | 链接寄存器,通常用来保存函数的返回地址。 |
| r15(PC) | 程序计数器,指向代码段中下一条将要执行的指令,不过由于流水线的作用,PC会指向将要执行的指令的下一条指令。 |
1.1 原理分析
当调用函数,依据APCS(ARM Procedure Call Standard)规范,新函数一开始的代码总是执行压栈操作,保留前函数的相关信息在栈上,具体压栈规则入下所示:
mov ip, sp
stmfd sp!, {r0 - r3} (可选的)
stmfd sp!, {..., fp, ip, lr, pc}
……做完压栈步骤以后,当前函数栈保存的寄存器信息如下:
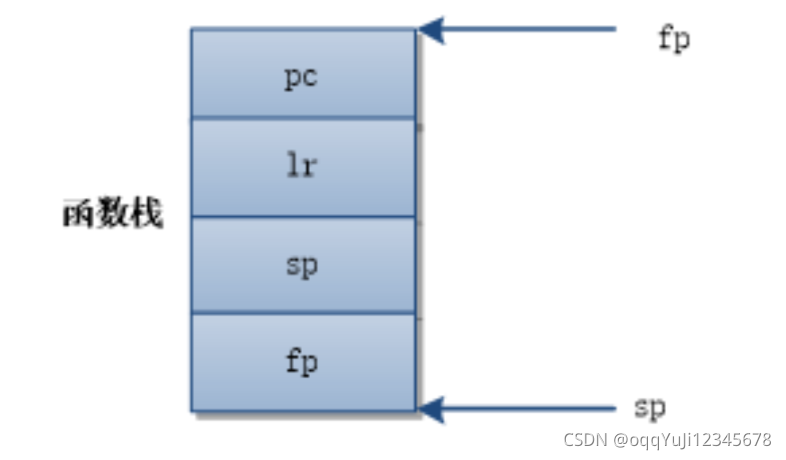
栈中lr是该函数的返回地址,sp是前一个函数的栈顶,fp是前一个函数的栈底。
通过fp寄存器就可以找到存储在栈中lr寄存器数据,这个数据就是函数返回地址。同时也可以找到保存在函数栈中的上一级函数fp寄存器数据,这个数据指向了上一级函数的栈底,如此就可以按照同样的方法找出上一级函数栈中存储的lr和fp数据,就知道哪个函数调用了上一级函数以及这个函数的栈底地址。这样就构成了一个栈回溯过程,整个流程以fp为核心,依次找出每个函数栈中存储的lr和fp数据,计算出函数返回地址和上一级函数栈底地址,从而找出每一级函数调用关系。
下面是一段简单的示例程序来验证上面 的过程:
void karry_a(void)
{
pr_err("call karry_a\n");
dump_stack();
return ;
}
void karry_b(void)
{
pr_err("call karry_b\n");
karry_a();
return ;
}
static int test_init() {
pr_err(" test_init\n");
karry_b();
return 0;
}
调用流程分别是
test_init->karry_b->karry_a
看一下其反汇编代码:
void karry_a(void)
{
10: e1a0c00d mov ip, sp
14: e92dd800 push {fp, ip, lr, pc}
18: e24cb004 sub fp, ip, #4 ; 0x4
1c: e59f0008 ldr r0, [pc, #8] ; 2c <karry_a+0x1c>
20: ebfffffe bl 0 <printk>
24: ebfffffe bl 0 <dump_stack>
}
28: e89da800 ldm sp, {fp, sp, pc}
2c: 00000000 .word 0x00000000
00000030 <karry_b>:
void karry_b(void)
{
30: e1a0c00d mov ip, sp
34: e92dd800 push {fp, ip, lr, pc}
38: e24cb004 sub fp, ip, #4 ; 0x4
3c: e59f0008 ldr r0, [pc, #8] ; 4c <karry_b+0x1c>
40: ebfffffe bl 0 <printk>
44: ebfffffe bl 10 <karry_a>
}
48: e89da800 ldm sp, {fp, sp, pc}
4c: 00000010 .word 0x00000010
static int test_init() {
50: e1a0c00d mov ip, sp
54: e92dd800 push {fp, ip, lr, pc}
58: e24cb004 sub fp, ip, #4 ; 0x4
5c: e59f000c ldr r0, [pc, #12] ; 70 <init_module+0x20>
60: ebfffffe bl 0 <printk>
64: ebfffffe bl 30 <karry_b>
}
可以看到每个函数刚开始部分都是如下代码
30: e1a0c00d mov ip, sp
34: e92dd800 push {fp, ip, lr, pc}
38: e24cb004 sub fp, ip, #4 ; 0x4和前面的示意图相匹配,先把sp 存入ip中,然后把 fp,sp,lr,和pc寄存器压入栈中,fp在低地址,pc在高地址,最后把fp寄存器指向存入的pc处,有了这些信息,基本就能向上一级一级回溯函数的调用关系。
1 首先读取系统中的FP寄存器的值,通过FP的值可以直接找到当前函数的代码段地址,这个很容易,因为当前正在执行的代码(可通过PC寄存器获得)就处在函数的代码段中。在函数栈中保存了一个PC寄存器的备份,通过这个PC寄存器的值可以定位到函数的第一条指令,即函数的入口地址。
2 得到当前函数的入口地址后,内核中保存了所有函数地址和函数名的对应关系,所以可以打印出函数名(可以参考这篇文章内核符号表的生成和查找过程_落尘纷扰的专栏-CSDN博客)。
3 在当前函数的函数栈中还保存了caller函数的帧指针(FP寄存器的值),所以我们就可以找到caller函数的函数栈的位置。
4 继续执行1-3步,直到某个函数的函数栈中保存的帧指针(FP寄存器的值)为0或非法。
1.2 dump_stack实现:
dump_stack
------->show_stack
---------->dump_backtrace
static void dump_backtrace(struct pt_regs *regs, struct task_struct *tsk)
{
unsigned int fp, mode;
int ok = 1;
printk("Backtrace: ");
if (!tsk)
tsk = current;
if (regs) {
fp = regs->ARM_fp;
mode = processor_mode(regs);
} else if (tsk != current) {
fp = thread_saved_fp(tsk);
mode = 0x10;
} else {
/* dump stack 主要走这个逻辑分支, 把fp 寄存器存入fp 变量中*/
asm("mov %0, fp" : "=r" (fp) : : "cc");
mode = 0x10;
}
if (!fp) {
printk("no frame pointer");
ok = 0;
} else if (verify_stack(fp)) {
printk("invalid frame pointer 0x%08x", fp);
ok = 0;
} else if (fp < (unsigned long)end_of_stack(tsk))
printk("frame pointer underflow");
printk("\n");
if (ok)
/* dump stack 的主要实现*/
c_backtrace(fp, mode);
}
c_backtrace函数定义如下(arch/arm/lib/backtrace.S)
@ 定义几个局部变量
#define frame r4
#define sv_fp r5
#define sv_pc r6
#define mask r7
#define offset r8
@ 当前处于dump_backtrace函数的栈中
ENTRY(c_backtrace)
stmfd sp!, {r4 - r8, lr} @ 将r4-r8和lr压入栈中,我们要使用r4-r8,所以备份一下原来的值。sp指向最后压入的数据
movs frame, r0 @ frame=r0。r0为传入的第一个参数,即fp寄存器的值
beq no_frame @ 如果frame为0,则退出
tst r1, #0x10 @ 26 or 32-bit mode? 判断r1的bit4是否为0
moveq mask, #0xfc000003 @ mask for 26-bit 如果是,即r1=0x10,则mask=0xfc000003,即pc地址只有低26bit有效,且末两位为0
movne mask, #0 @ mask for 32-bit 如果不是,即r1!=0x10,则mask=0
@ 下面是一段和该函数无关的代码,用来计算pc预取指的偏移,一般pc是指向下两条指令,所以offset一般等于8
1: stmfd sp!, {pc} @ 存储pc的值到栈中,sp指向pc。
ldr r0, [sp], #4 @ r0=sp的值,即刚刚存的pc的值(将要执行的指令),sp=sp+4即还原sp
adr r1, 1b @ r1 = 标号1的地址,即指令 stmfd sp!, {pc} 的地址
sub offset, r0, r1 @ offset=r0-r1,即pc实际指向的指令和读取pc的指令之间的偏移
/*
* Stack frame layout:
* optionally saved caller registers (r4 - r10)
* saved fp
* saved sp
* saved lr
* frame => saved pc @ frame即上面的fp,每个函数的fp都指向这个位置
* optionally saved arguments (r0 - r3)
* saved sp => <next word>
*
* Functions start with the following code sequence:
* mov ip, sp
* stmfd sp!, {r0 - r3} (optional)
* corrected pc => stmfd sp!, {..., fp, ip, lr, pc} //将pc压栈的指令
*/
@ 函数主流程:开始查找并打印调用者函数
for_each_frame: tst frame, mask @ Check for address exceptions
bne no_frame
@ 由sv_pc找到将pc压栈的那条指令,因为这条指令在代码段中的位置有特殊性,可用于定位函数入口。
1001: ldr sv_pc, [frame, #0] @ 获取保存在callee栈里的sv_pc,它指向callee的代码段的某个位置
1002: ldr sv_fp, [frame, #-12] @ get saved fp,这个fp就是caller的fp,指向caller的栈中某个位置
sub sv_pc, sv_pc, offset @ sv_pc减去offset,找到将pc压栈的那条指令,即上面注释提到的corrected pc。
bic sv_pc, sv_pc, mask @ mask PC/LR for the mode 清除sv_pc中mask为1的位,例如,mask=0x4,则清除sv_pc的bit2。
@ 定位函数的第一条指令,即函数入口地址
1003: ldr r2, [sv_pc, #-4] @ if stmfd sp!, {args} exists, 如果在函数最开始压入了r0-r3
ldr r3, .Ldsi+4 @ adjust saved 'pc' back one. r3 = 0xe92d0000 >> 10
teq r3, r2, lsr #10 @ 比较stmfd指令机器码是否相同(不关注是否保存r0-r9),目的是判断是否为stmfd指令
subne r0, sv_pc, #4 @ allow for mov: 如果sv_pc前面只有mov ip, sp
subeq r0, sv_pc, #8 @ allow for mov + stmia: 如果sv_pc前面有两条指令
@ 至此,r0为callee函数的第一条指令的地址,即callee函数的入口地址
@ 打印r0地址对应的符号名,传给dump_backtrace_entry三个参数:
@ r0:函数入口地址,
@ r1:返回值即caller中的地址,
@ r2:callee的fp
ldr r1, [frame, #-4] @ get saved lr
mov r2, frame
bic r1, r1, mask @ mask PC/LR for the mode
bl dump_backtrace_entry
@ 打印保存在栈里的寄存器,这跟栈回溯没关系,本文中不太关心
ldr r1, [sv_pc, #-4] @ if stmfd sp!, {args} exists, sv_pc前一条指令是否是stmfd指令
ldr r3, .Ldsi+4
teq r3, r1, lsr #10
ldreq r0, [frame, #-8] @ get sp。frame-8指向保存的IP寄存器,由于mov ip, sp,所以caller的sp=ip
@ 所以r0=caller的栈的低地址。
subeq r0, r0, #4 @ point at the last arg. r0+4就是callee的栈的高地址。
@ 由于参数的压栈顺序为r3,r2,r1,r0,所以这里栈顶实际上是最后一个参数。
bleq .Ldumpstm @ dump saved registers
@ 打印保存在栈里的寄存器,这跟栈回溯没关系,本文中不太关心
1004: ldr r1, [sv_pc, #0] @ if stmfd sp!, {..., fp, ip, lr, pc}
ldr r3, .Ldsi @ instruction exists, 如果指令为frame指向的指令为stmfd sp!, {..., fp, ip, lr, pc}
teq r3, r1, lsr #10
subeq r0, frame, #16 @ 跳过fp, ip, lr, pc,即找到保存的r4-r10
bleq .Ldumpstm @ dump saved registers,打印出来r4-r10
@ 对保存在当前函数栈中的caller的fp做合法性检查
teq sv_fp, #0 @ zero saved fp means 判断获取的caller的fp的值
beq no_frame @ no further frames 如果caller fp=0,则停止循环
@ 更新frame变量指向caller函数栈的位置,将上面注释中的Stack frame layout
cmp sv_fp, frame @ sv_fp-frame
mov frame, sv_fp @ frame=sv_fp
bhi for_each_frame @ cmp的结果,如果frame<sv_fp,即当前fp小于caller的fp,则继续循环
@ 这时frame指向caller栈的fp,由于函数中不会修改fp的值,所以这个fp肯定是指向caller保存的pc的位置的。
1006: adr r0, .Lbad @ 否则就打印bad frame提示
mov r1, frame
bl printk
no_frame: ldmfd sp!, {r4 - r8, pc}
ENDPROC(c_backtrace)
@ c_backtrace函数结束。
@ 将上面的代码放到__ex_table异常表中。其中1001b ... 1006b是指上面的1001-1006标号。
.section __ex_table,"a"
.align 3
.long 1001b, 1006b
.long 1002b, 1006b
.long 1003b, 1006b
.long 1004b, 1006b
.previous
#define instr r4
#define reg r5
#define stack r6
@ 打印寄存器值
.Ldumpstm: stmfd sp!, {instr, reg, stack, r7, lr}
mov stack, r0
mov instr, r1
mov reg, #10
mov r7, #0
1: mov r3, #1
tst instr, r3, lsl reg
beq 2f
add r7, r7, #1
teq r7, #6
moveq r7, #1
moveq r1, #'\n'
movne r1, #' '
ldr r3, [stack], #-4
mov r2, reg
adr r0, .Lfp
bl printk
2: subs reg, reg, #1
bpl 1b
teq r7, #0
adrne r0, .Lcr
blne printk
ldmfd sp!, {instr, reg, stack, r7, pc}
.Lfp: .asciz "%cr%d:%08x"
.Lcr: .asciz "\n"
.Lbad: .asciz "Backtrace aborted due to bad frame pointer <%p>\n"
.align
.Ldsi:
@ 用来判断是否是stmfd sp!指令,并且参数包含fp, ip, lr, pc,不包含r10
.word 0xe92dd800 >> 10 @ stmfd sp!, {... fp, ip, lr, pc}
@ 用来判断是否是stmfd sp!指令,并且参数不包含r10, fp, ip, lr, pc
.word 0xe92d0000 >> 10 @ stmfd sp!, {}更详细的内容参考这篇文章:
linux内核中打印栈回溯信息 - dump_stack()函数分析_落尘纷扰的专栏-CSDN博客_dump_stack
2 基于unwind的栈回溯
在arm架构下,不少32位系统用的是unwind形式的栈回溯,这种栈回溯要复杂很多。首先需要程序有一个特殊的段.ARM.unwind_idx 或者.ARM.unwind_tab,linux内核本身由多段组成,比如内核驱动初始化函数的init段。在System.map文件可以搜索到__start_unwind_idx,这就是ARM.unwind_idx段的起始地址。这个unwind段中存储着跟函数入栈相关的关键数据。当函数执行入栈指令后,在unwind段会保存跟入栈指令一一对应的编码数据,根据这些编码数据,就能计算出当前函数栈大小和cpu的哪些寄存器入栈了,在栈中什么位置。当栈回溯时,首先根据当前函数中的指令地址,就可以计算出函数unwind段的地址,然后从unwind段取出跟入栈有关的编码数据,根据这些编码数据就能计算出当前函数栈的大小以及入栈时lr寄存器数据在栈中的存储地址。这样就可以找到lr寄存器数据,就是当前函数返回地址,也就是上一级函数的指令地址。此时sp一般指向的函数栈顶,sp+函数栈大小就是上一级函数的栈顶。这样就完成了一次栈回溯,并且知道了上一级函数的指令地址和栈顶地址,按照同样的方法就能对上一级函数栈回溯,类推就能实现整个栈回溯流程。
更详细的内容参考这篇文章:

















 1145
1145

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









