




数据库在 IT 架构中承担数据存储和查询的功能,其正常运行对企业数据安全和业务连续性起着至关重要的作用。
- 传统数据库通常采用HA或RAC架构来实现高可用,这类架构是我们通常所说的“Share Everything",虽然能够通过冗余计算节点来规避计算资源的单点,但数据库只有一个,只能依赖底层存储的冗余来保证数据的安全。但存储本身也是一个集中式的设备,一旦出现问题对数据库来说是毁灭性的影响;
- 分布式数据库采用存储和计算节点分离的架构,通过多副本机制将数据分散在不同的节点,即使部分节点故障,仍然可以从其他节点获取到数据。相比传统集中式架构,分布式架构数据散落在多个存储节点上,因此这种架构也被称为“Share Nothing”。
OceanBase 是一款分布式架构的数据库,因此其设计理念也遵循上述的分布式架构特点,但是在技术实现上仍然有其特有之处。这篇文章就来说说,OceanBase 是如何实现高可用的。
物理架构和高可用
从物理上看,OceanBase 数据库集群由若干个可用区 (Zone) 组成,Zone 代表了一组服务器的物理位置分布。不同的 Zone 可以是异地或同城的数据中心,也可以是同一个数据中心不同的机架。Zone 由一到多台服务器 (OB Server) 构成,每个 Zone 都有一份且只有一份完整的数据副本,单个 Zone 出现故障时可能通过其他副本获取数据,为了避免集群分裂时出现对等数量的子集,Zone 通常建议配置为奇数数量。
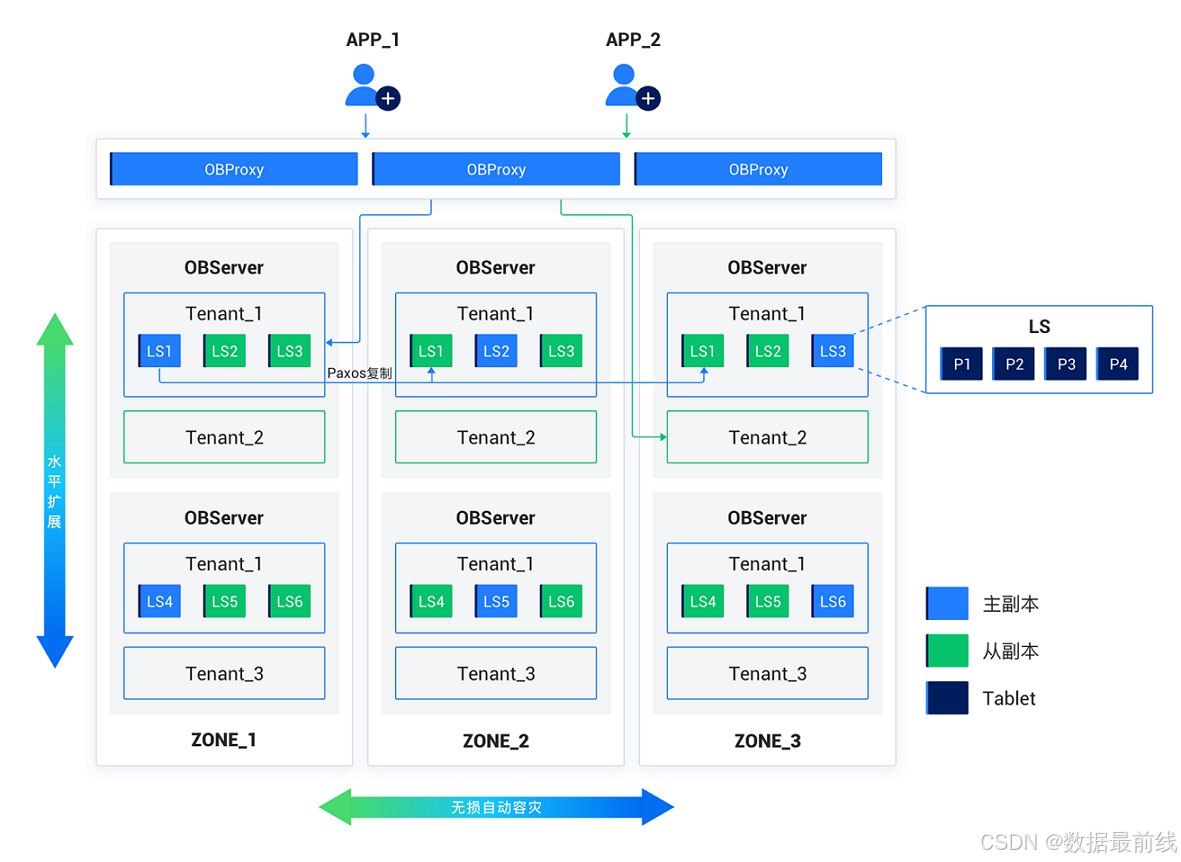
OB Server 提供独立的计算和存储资源,每台服务器都是对等的。当部分OB Server故障无法提供正常服务时,上层的 OBProxy 能感知到故障节点并将相应的路由切换到正常的镜像节点上。
数据管理和高可用
OceanBase 是分布式数据库,逻辑层面的高可用主要通过数据多副本来实现。
OB 将资源分配单位定义为 UNIT,UNIT 类似于一个 docker 容器,描述了位于一台 Server 上的一组计算资源 (CPU 和内存) 和存储资源,每个 UNIT 只能属于一个租户。
资源池由一个或多个 UNIT 组成,这些资源来自每个Zone中的服务器节点。资源池被分配给相应的租户,数据库则创建在相应的租户。
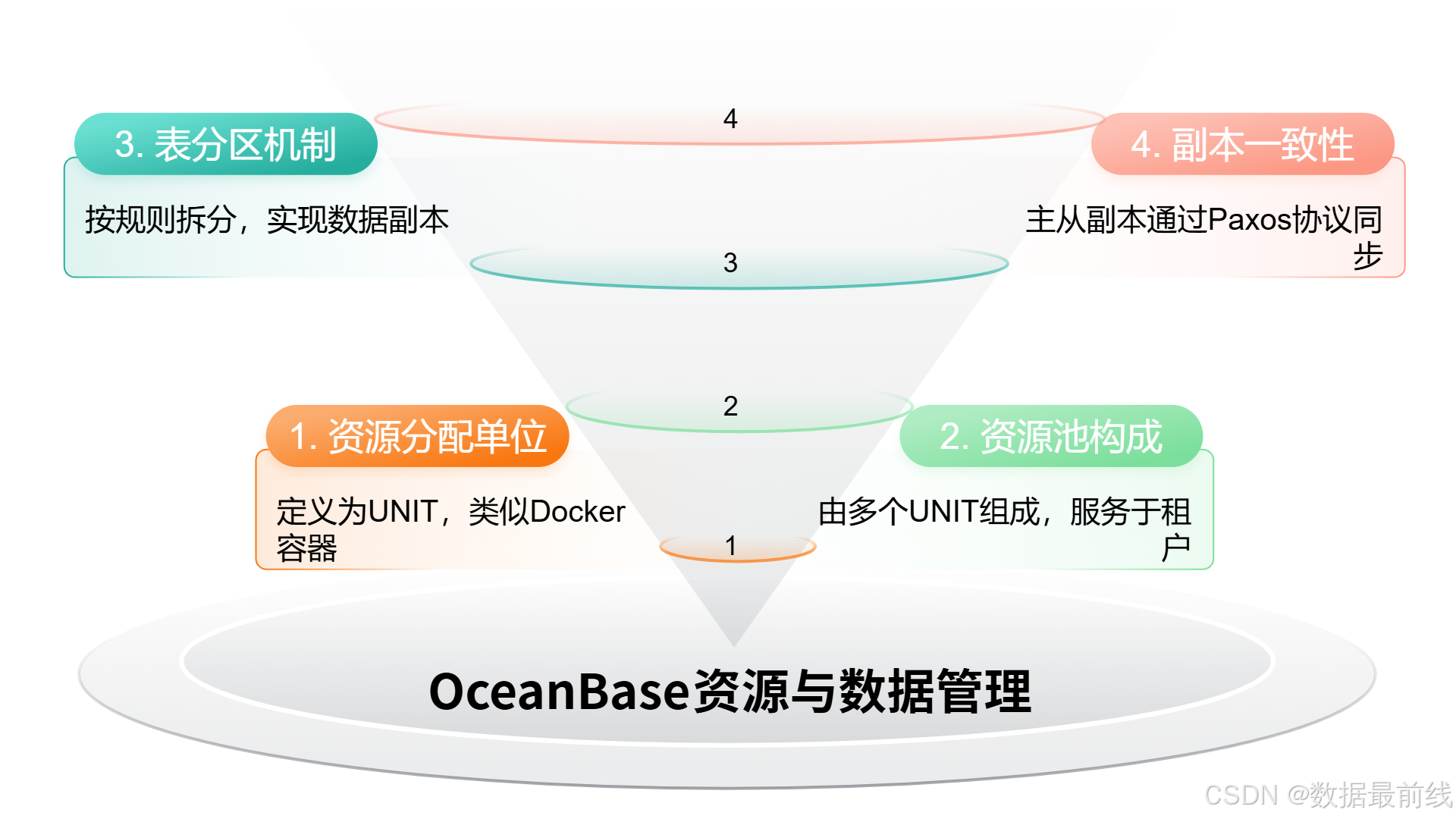
在OceanBase数据库内部,一个表的数据可以按照某种规则水平拆分为多个分片,每个分片称之为一个表分区。表分区的数据会在租户创建时指定的每个 Zone 上保存一份数据,称为副本。这些副本仅有一个允许对外读写,叫做主副本 (Leader),其他副本叫做从副本 (Follower),主从副本之间通过 Paxos 分布式协议进行数据同步,确保数据的一致性。当主副本所在的节点发生故障时,其中一个从副本被选举为新的主副本并继续提供服务。
应用访问高可用
OceanBase 上层还有一个 OB Proxy 的组件,应用通过该组件连接到 OB 数据库。
OB Proxy 是一个无状态的服务进程,不参与数据库引擎的计算任务,也不参与事务处理。仅对 SQL 语句做基础解析,确定对应的 Leader 所在位置,并将请求路由到对应的 Leader 上,从而实现应用的透明访问。
OB Proxy 不做数据持久化,既可以独立部署,也可以和 OB Server 部署在同一台服务器。为了实现该组件的高可用,通常会在一套集群中部署 3 个节点,前端再加上 F5 组成负载均衡集群。
写在最后
高可用是分布式架构设计最原始的目标,以小型机和存储为代表集中式架构成本高昂,因此人们想用价格相对低廉的 PC 服务器来替代集中式架构。但彼时的 PC 服务器可靠性和小型机差距甚远,为了规避硬件风险设计了分布式架构。分布式架构没有中心节点,各节点之间没有强依赖关系,同时每个组件又有冗余,架构上不存在单点的隐患。
具体到 OceanBase 数据库,从上层的 OB Proxy,到物理节点架构的 Zone,以及数据存储副本,每个环节都有相应的冗余保护机制,少量的节点损坏并不会影响整个集群的正常工作。
集群组件各司其职,但又相互协同构成一个有机的整体,这大概是分布式最有魅力的地方吧!

















 1792
1792

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









