







代码
val conf: SparkConf = new SparkConf().setMaster("local").setAppName("wordcount")
val sc: SparkContext = new SparkContext(conf)
val rdd: RDD[String] = sc.textFile("datas/1.txt",2)
rdd.saveAsTextFile("output")数据格式 :
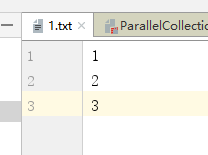
当texfFile可以将文件作为数据处理的数据源,默认也有设定分区
minPartitions:最小分区数量

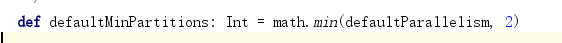
默认的最小分区数为2,但是实际的分区数可能比2要大
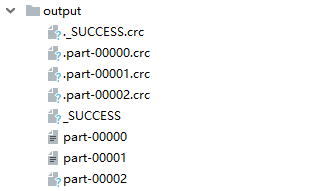
比如运行脚本后最后得到的分区文件为3个文件,并不是2个文件,原因是
分区数量的计算方式,spark读取文件底层使用的是hadoop读取文件方式getSplits方法
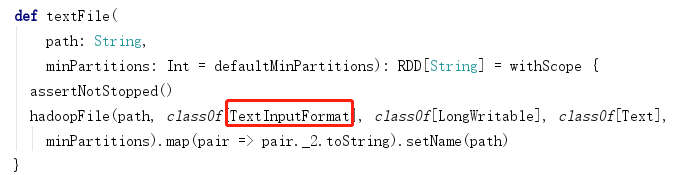

通过源码查看使用到了totalSize,这个指的是文件的字节数
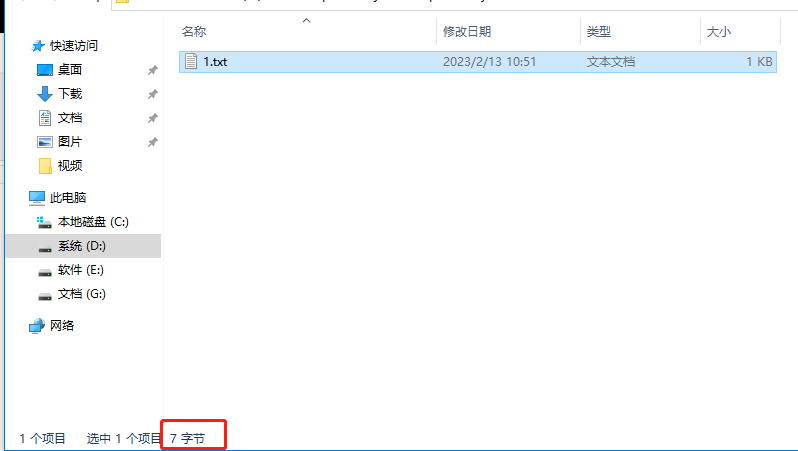
通过文件打开可以看到在1 和2 的后面有特殊字符,表示回车因此该文档并不是3个字节而是7个字节

因此 totalSize=7
long goalSize = 7 / (long)(2 == 0 ? 1 : 2)=7/2=3 表示每个分区的字节数
totalSize/goalSize=7/3=2 个分区 余 1个字节 ,1个字节占3个字节的30%
在hadoop的切分原理(1.1)时如果剩余的数据量大于10%产生新的分区
因此最后产出的是3个分区文件

















 2053
2053

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









