







Task2 数据读取与数据分析 学习笔记
Author: 2tong
教程学习
1.数据读取
>>> import pandas as pd
>>> train_file = './data/train_set.csv'
>>> train_df = pd.read_csv(train_file, sep='\t', nrows=100)
>>> train_df.head()
label text
0 2 2967 6758 339 2021 1854 3731 4109 3792 4149 15...
1 11 4464 486 6352 5619 2465 4802 1452 3137 5778 54...
2 3 7346 4068 5074 3747 5681 6093 1777 2226 7354 6...
3 2 7159 948 4866 2109 5520 2490 211 3956 5520 549...
4 3 3646 3055 3055 2490 4659 6065 3370 5814 2465 5...
2.数据分析
对非结构数据往往不需要做很多的数据分析,但是通过数据分析还是可以找出一些规律的。
2.1句子长度分析
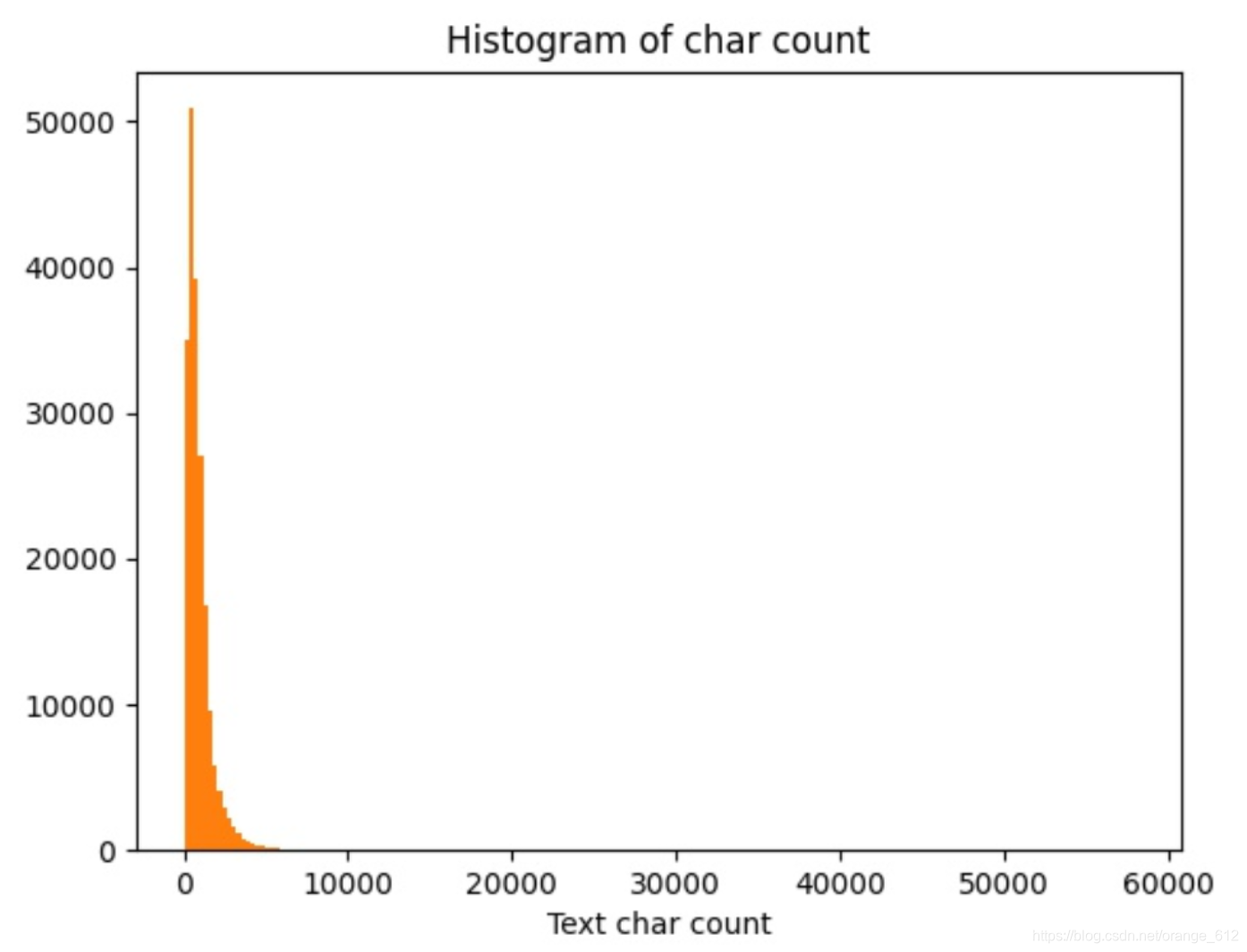
目标:探测赛题的数据集中句子长度分布。
>>> train_df = pd.read_csv(train_file, sep='\t')
>>> train_df['text_len'] = train_df['text'].apply(lambda x: len(x.split(' ')))
>>> print(train_df['text_len'].describe())
count 200000.000000
mean 907.207110
std 996.029036
min 2.000000
25% 374.000000
50% 676.000000
75% 1131.000000
max 57921.000000
Name: text_len, dtype: float64
绘制直方图:
>>> import matplotlib.pyplot as plt
>>> _ = plt.hist(train_df['text_len'], bins=200)
>>> plt.xlabel('Text char count')
Text(0.5, 0, 'Text char count')
>>> plt.title('Histogram of char count')
Text(0.5, 1.0, 'Histogram of char count')
>>> plt.savefig('histogram_of_char_count.jpg')
2.2类别分析
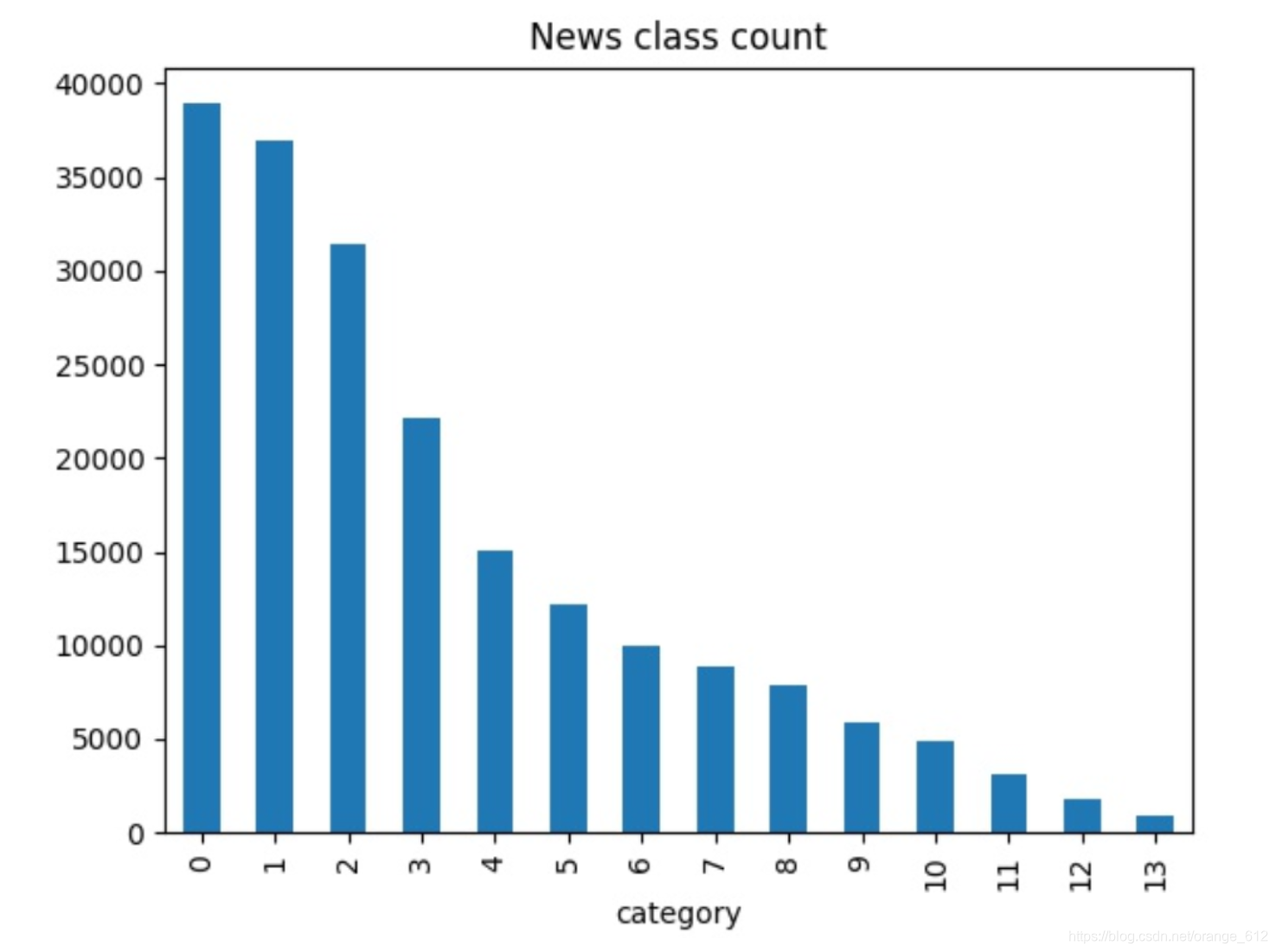
目标:统计赛题的数据集分布情况,探测是否存在分布较为不均匀的情况。
>>> train_df['label'].value_counts()
0 38918
1 36945
2 31425
3 22133
4 15016
5 12232
6 9985
7 8841
8 7847
9 5878
10 4920
11 3131
12 1821
13 908
Name: label, dtype: int64
>>> train_df['label'].value_counts().plot(kind='bar')
<AxesSubplot:>
>>> plt.title('News class count')
Text(0.5, 1.0, 'News class count')
>>> plt.xlabel('category')
Text(0.5, 0, 'category')
>>> plt.savefig('news_class_count.jpg')
2.3字符分布统计
目标:统计每个字符出现的次数,共有多少个字符
>>> from collections import Counter
>>> all_lines = ' '.join(list(train_df['text']))
>>> word_count = Counter(all_lines.split(" "))
>>> word_count = sorted(word_count.items(), key=lambda d:d[1], reverse = True)
>>> print(len(word_count))
6869
>>> print(word_count[0])
('3750', 7482224)
>>> print(word_count[-1])
('3133', 1)
目标:推出标点符号:哪些在每个句子中基本均出现的,覆盖率高的很有可能是标点符号
>>> train_df['text_unique'] = train_df['text'].apply(lambda x: ' '.join(list(set(x.split(' ')))))
>>> all_lines = ' '.join(list(train_df['text_unique']))
>>> word_count = Counter(all_lines.split(" "))
>>> word_count = sorted(word_count.items(), key=lambda d:int(d[1]), reverse = True)
>>> print(word_count[0], word_count[1], word_count[2])
('3750', 197997) ('900', 197653) ('648', 191975)
技术储备
1.pandas
Pandas是一个强大的分析结构化数据的工具集;它的使用基础是Numpy(提供高性能的矩阵运算);用于数据挖掘和数据分析,同时也提供数据清洗功能。
Pandas的利器为:
- DataFrame
- Series














 404
404











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









