







写在前面:
本文只是简要的介绍了一下LDA模型的概念和一些整体上的认识,没有涉及到具体的公式推导,目前只是按照助教的建议大致梳理一下,后期肯定还要花大时间推导公式仔细理解该模型,感兴趣的可以参考后面的博客,总结的很详细,看完后受益匪浅。
文章目录
一. PlSA模型
1. 概念
- pLSA 模型是有向图模型,将主题作为隐变量,构建了一个简单的贝叶斯网,采用EM算法估计模型参数
- 在语义分析问题中,存在同义词和一词多义这两个严峻的问题,LSA可以很好的解决同义词问题,却无法妥善处理一词多义问题。PLSA则可以同时解决这两个问题
2.概率图模型
PLSA的概率图模型如下所示:

- 其中 D 表示文档(document),Z 表示主题(topic), W 表示单词(word),其中箭头表示了变量间的依赖关系,比如 D 指向 Z,表示一篇文档决定了该文档的主题,Z 指向 W 表示由该主题生成一个单词,方框右下角的字母表示该方框执行的次数,N 表示共生成了 N 篇文档,M 表示一篇文档按照document-topic分布生成了 M 次主题,每一次按照生成的主题的topic-word分布生成单词。每个文档的单词数可以不同。
- PLSA引入了隐藏变量 Z,认为 {D,W,Z} 表示完整的数据集(the complete data set), 而原始的真实数据集 {D,W} 是不完整的数据集(incomplete data)。
- 假设 Z 的取值共有 K 个。PLSA模型假设的文档生成过程如下:
以 p( d i d_i di) 的概率选择一个文档 d i d_i di
以 p( z k z_k zk| d i d_i di) 的概率选择一个主题 z k z_k zk
以 p( w j w_j wj| z k z_k zk) 的概率生成一个单词 w j w_j wj
- 根据图模型,可以得到观测数据的联合分布:
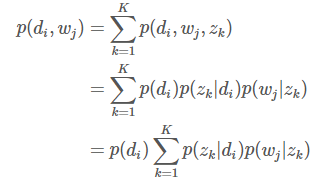
第一个等式是对三者的联合概率分布对其中的隐藏变量 Z 的所有取值累加,第二个等式根据图模型的依赖关系将联合概率展开为条件概率,第三个等式只是简单的乘法结合律。这样就计算出了第 i 篇文档与第 j 个单词的联合概率分布。
二. 共轭先验分布
1. 基本概率分布
- 概率论中有两大学派,分别是频率学派和贝叶斯学派。先验概率,后验概率,共轭分布和共轭先验是贝叶斯学派中的几个概念。二者的区别是贝叶斯学派认为分布存在先验分布和后验分布的不同,而频率学派则认为一个事件的概率只有一个。
- 基本概率分布主要有以下几种:
先验分布(prior probability)
后验分布(posterior probability)
似然函数(likelyhood function)
共轭分布(conjugacy)
2. 共轭分布
- 共轭分布就是后验概率分布函数与先验概率分布函数具有相同形式
- 采用共轭先验的原因是可以使得先验分布和后验分布的形式相同,这样一方面合符人的直观(它们应该是相同形式的)另外一方面是可以形成一个先验链,即现在的后验分布可以作为下一次计算的先验分布,如果形式相同,就可以形成一个链条。
- 如果先验分布和似然函数可以使得先验分布和后验分布(posterior distributions)有相同的形式,那么就称先验分布与似然函数是共轭的。所以,共轭是指的先验分布(prior probability distribution)和似然函数(likelihood function)。如果某个随机变量Θ的后验概率 p(θ|x)和气先验概率p(θ)属于同一个分布簇的,那么称p(θ|x)和p(θ)为共轭分布,同时,也称p(θ)为似然函数p(x|θ)的共轭先验。
三. LDA主题模型
1.原理
在LDA模型中,一篇文档生成的方式如下:
- 从狄利克雷分布中 α \alpha α 取样生成文档 i 的主题分布 θ i \theta_i θi
- 从主题的多项式分布 θ i \theta_i θi 中取样生成文档i第 j 个词的主题 z i , j z_{i,j} zi,j
- 从狄利克雷分布 β \beta β中取样生成主题 z i , j z_{i,j} zi,j对应的词语分布 Φ z i , j \Phi_{z{i,j}} Φzi,j
- 从词语的多项式分布
Φ
z
i
,
j
\Phi_{z{i,j}}
Φzi,j中采样最终生成词语
w
i
,
j
w_{i,j}
wi,j
其中,类似Beta分布是二项式分布的共轭先验概率分布,而狄利克雷分布(Dirichlet分布)是多项式分布的共轭先验概率分布
LDA的图模型结构如下图所示(类似贝叶斯网络结构):

2.学习步骤
- 一个函数:gamma函数
- 四个分布:二项分布、多项分布、beta分布、Dirichlet分布
- 一个概念和一个理念:共轭先验和贝叶斯框架
- 两个模型:pLSA、LDA
- 一个采样:Gibbs采样
3.应用场景
- 特征生成:LDA可以生成特征供其他机器学习算法使用。
- 在推荐系统中的应用
- 降维:每篇文章在主题上的分布提供了一个文章的简洁总结。
- 在关键词提取的应用
- 中文标签/话题提取/推荐
- LDA相似文章聚类
- 文本挖掘中主题追踪的可视化呈现
- 高效的主题模型的建立
- 排序
4.优缺点
4.1 优点
- 在降维过程中可以使用类别的先验知识经验,而像PCA这样的无监督学习则无法使用类别先验知识
- LDA在样本分类信息依赖均值而不是方差的时候,比PCA之类的算法较优。
4.2 缺点
- LDA不适合对非高斯分布样本进行降维,PCA也有这个问题。
- LDA降维最多降到类别数k-1的维数,如果我们降维的维度大于k-1,则不能使用LDA。当然目前有一些LDA的进化版算法可以绕过这个问题。
- LDA在样本分类信息依赖方差而不是均值的时候,降维效果不好。
- LDA可能过度拟合数据
5.参数学习
LDA在sklearn中,sklearn.decomposition.LatentDirichletAllocation()
主要参数:
n_components : int, optional (default=10)
主题数
doc_topic_prior : float, optional (default=None)
文档主题先验Dirichlet分布θd的参数α
topic_word_prior : float, optional (default=None)
主题词先验Dirichlet分布βk的参数η
learning_method : 'batch' | 'online', default='online'
LDA的求解算法。有 ‘batch’ 和 ‘online’两种选择
learning_decay : float, optional (default=0.7)
控制"online"算法的学习率,默认是0.7
learning_offset : float, optional (default=10.)
仅在算法使用"online"时有意义,取值要大于1。用来减小前面训练样本批次对最终模型的影响
max_iter : integer, optional (default=10)
EM算法的最大迭代次数
batch_size : int, optional (default=128)
仅在算法使用"online"时有意义, 即每次EM算法迭代时使用的文档样本的数量。
evaluate_every : int, optional (default=0)
多久评估一次perplexity。仅用于`fit`方法。将其设置为0或负数以不评估perplexity
训练。
total_samples : int, optional (default=1e6)
仅在算法使用"online"时有意义, 即分步训练时每一批文档样本的数量。在使用partial_fit函数时需要。
perp_tol : float, optional (default=1e-1)
batch的perplexity容忍度。
mean_change_tol : float, optional (default=1e-3)
即E步更新变分参数的阈值,所有变分参数更新小于阈值则E步结束,转入M步。
max_doc_update_iter : int (default=100)
即E步更新变分参数的最大迭代次数,如果E步迭代次数达到阈值,则转入M步。
n_jobs : int, optional (default=1)
在E步中使用的资源数量。 如果为-1,则使用所有CPU。
``n_jobs``低于-1,(n_cpus + 1 + n_jobs)被使用。
verbose : int, optional (default=0)
详细程度。
总结的比较好的博客:
https://blog.csdn.net/v_july_v/article/details/41209515
https://zhuanlan.zhihu.com/p/31470216
https://www.cnblogs.com/pinard/p/6831308.html















 677
677











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









