






版权声明:本文为博主原创文章,未经博主允许不得转载。 http://blog.csdn.net/tilyp/article/details/56298954
scrapy-cluster集群的架构:
- python 2.7
- scrapy 1.0.5
- kafka 2.10-0.10.1.1
- redis 3.0.6
scrapy集群的目的:
- 他们允许任何web页面的任意集合提交给scrapy集群,包括动态需求。
- 大量的Scrapy实例在单个机器或多个机器上进行爬取。
- 协调和优化他们的抓取工作所需的网站。
- 存储抓取的数据。
- 并行执行多个抓取作业。
- 深度信息抓取工作,网站排名,预测等。
- 你可以任意 add/remove/scale你的爬虫而不会造成数据丢失或停机等待。
- 利用Apache kafka作为集群的数据总线与集群的(提交工作,信息输入,停止工作,查看结果)。
- 能够调整管理独立的爬虫在多台机器上,但必须用相同的IP
scrapy-cluster 原理流程图
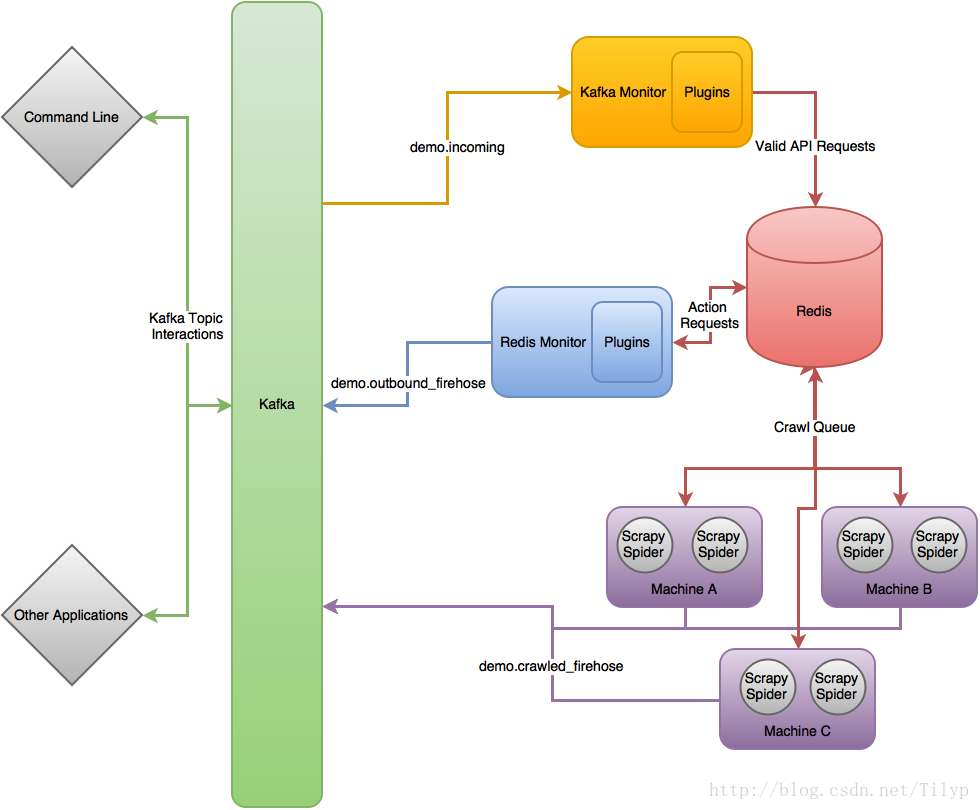
在最高的层次上,Scrapy集群作用于单个输入卡夫卡的话题,和两个独立输出卡夫卡的话题。所有请求传入集群的kafka话题都是通过demo.incoming, 并根据传入请求将生成行为请求话题 demo.outbound_firehose或网页爬取请求话题demo.crawled_firehose。 这里包括的三个组件是可扩展的,kafka组件和redis组件都使用“插件”以提高自己的能力,Scrapy可以运用“Middlewares”,“Pipelines”,“Spiders”去定制自己的爬取需求,这三个组件在一起允许缩放和分布式运行在许多机器上。
各个组件的作用
很多人都在说kafka和redis两个是相互冲突的,这是因为他们对这两种软件的特性不了解。
kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理大批量的实时流数据,如日志;Redis 是一个高性能的key-value形式的内存数据库,支持持久化,因此两者的应用场景不同。在scrapy-cluster集群中,kafka作为消息主线、爬虫的入口,通过kafka-monitor可以控制爬虫的启动、发布、停止、日志处理、以及结果输出,这里也对用户的输入做了格式化处理;redis作为数据库来处理和存储爬虫队列,也用来记录爬虫的状态数据。zookeeper组件是为了更新配置文件,这样不需要重启程序就可以使新的配置生效。
开始搭建集群
- 首先得确保你的每台机器上运行着kafka,zookeeper,redis,python2.7。
注:搭建步骤我的博客里都写了,redis只是存储和管理队列,不负责存储爬虫结果,而且搭建也很简单,在这里不累赘,
zookeeper集群搭建教程:scrapy-culster集群之zookeeper安装
kafka集群搭建教程:scrapy-culster集群搭建之kafka安装
数据库搭建方案有两个:
一, MongoDB搭建教程: ubuntu16.04 下安装mongodb3.4.4
二, Cassandra集群搭建教程: cassandra 集群搭建(ubuntu和windows) - 在每台机器上安装scrapy-cluster,下载地址点击这里,
- 解压并进入文件根据requirements.txt文件下载依赖需求
$ pip install -r requirements.txt- 1
- 离线运行单元测试,以确保一切似乎正常。
$ ./run_offline_tests.sh
如果失败,请检查你的依赖是否安装成功。 - 在三个组件中新建localsettings.py文件并设置kafka,redis,zookeeper的相关配置以确保通信(这里的localsettings.py是覆盖settings.py的,方便我们修改配置,以防引起不必要的冲突和麻烦(注:以下
scdev是kafka,redis,zookeeper的主机),KAFKA_HOSTS的设置为集群有多少个IP:PORT就写多少,以逗号(,)隔开,如KAFKA_HOSTS = 'ip1:port,ip2:port,ip3:port'。
在 kafka-monitor的localsettings.py文件中写入
REDIS_HOST = 'scdev'
KAFKA_HOSTS = 'scdev:9092'
在redis-monitor的localsettings.py文件中写入
REDIS_HOST = 'scdev'
KAFKA_HOSTS = 'scdev:9092'
在crawlers/crawling/的localsettings.py文件中写入
REDIS_HOST = 'scdev'
KAFKA_HOSTS = 'scdev:9092'
ZOOKEEPER_HOSTS = 'scdev:2181'
然后运行他们各自的测试文件
$ python tests/tests_online.py -v- 1
如果集成测试失败,请确保你的端口是打开的在kafka集群,redis主机和zookeeper主机。确保机器爬虫的设置可以访问所需的主机上,且可以成功地访问互联网。如果测试成功,那么恭喜你,你可以学习如何使用他了。当然这里是直接部署,如果单台机器没有测试通过,建议你先看看官方文档的测试用例。
集群的使用
首先,启动你的每一台机器上的三大组件
1,Kafka Monitor
$ python kafka_monitor.py run- 1
2, 启动你要执行的spider,如link_spider.py
$ scrapy runspider crawling/spiders/link_spider.py- 1
3,启动kafkadump.py 来监听redis 组件返回的结果
$ python kafkadump.py dump -t demo.crawled_firehose- 1
用多少台机器你启动多少台,这里可以添加&在后台启动,当然我还是建议你在刚开始时打开更多的窗口来观察他们如何工作。
其次,就是启动整个集群
1,Kafka Monitor
$ python kafka_monitor.py run- 1
2,Redis Monitor
$ python redis_monitor.py- 1
3,再次启动你要执行的spider
$ scrapy runspider crawling/spiders/link_spider.py- 1
4,启动dump 监听redis组件返回的结果
$ python kafkadump.py dump -t demo.crawled_firehose- 1
5,启动dump 查看你的机器爬取的结果
$ python kafkadump.py dump -t demo.outbound_firehose- 1
在选择的每台机器上,每一个过程中应保持运行并和其余集群处于操作状态。
再次,进行数据爬取
1,在接下来我们需要给集群发送一个爬取请求,这是通过相同的kafka组件python脚本来实现的,但是需要运用不同的命令来辨别结果。
$ python kafka_monitor.py feed '{"url": "http://istresearch.com", "appid":"testapp", "crawlid":"abc123"}'- 1
在下列命令行中您将看到发送请求成功:
$ 2015-12-22 15:45:37,457 [kafka-monitor] INFO: Feeding JSON into demo.incoming
{
"url": "http://istresearch.com",
"crawlid": "abc123",
"appid": "testapp"
}
2015-12-22 15:45:37,459 [kafka-monitor] INFO: Successfully fed item to Kafka- 1
- 2
- 3
- 4
- 5
- 6
- 7
如果连接不到kafka,你将在日志中看到一条错误消息,
2,在请求成功之后,以下一系列的事件将按照顺序发生:
- kafka组件将收到请求,并把它存放到redis中
- spider会定期检测新的请求,并像正常的scrapy spider一样从队列中获取请求且执行它
- 接着爬取到的数据将被挂起在 Scrapy item pipeline 中,由kafka Pipeline对象将其推送到kafka
- kafka dump 将读取结果输出的话题,并打印它收到的原始爬取对象
3,redis 组件有助于我们学习在爬取中如何处理和操作redis,因此我们会选择一个更大的网站我们可以看到它是如何工作的(这需要一个完整的部署)
Crawl Request:
$ python kafka_monitor.py feed '{"url": "http://dmoz.org", "appid":"testapp", "crawlid":"abc1234", "maxdepth":1}'- 1
现在发送一个info行为请求爬取去看发生了什么
$ python kafka_monitor.py feed '{"action":"info", "appid":"testapp", "uuid":"someuuid", "crawlid":"abc1234", "spiderid":"link"}'- 1
以下情况会发生在这个动作请求之后
- kafka 组件将收到操作请求,并把它存放到redis
- redis 组件将执行
info请求和记录的当前挂起的请求的spiderid,appid,crawlid。 - redis 组件将结果返回给kafka
- kafka dump 将收到类似下面的结果:
$ {u'server_time': 1450817666, u'crawlid': u'abc1234', u'total_pending': 25, u'total_domains': 2, u'spiderid': u'link', u'appid': u'testapp', u'domains': {u'twitter.com': {u'low_priority': -9, u'high_priority': -9, u'total': 1}, u'dmoz.org': {u'low_priority': -9, u'high_priority': -9, u'total': 24}}, u'uuid': u'someuuid'}- 1
在这种情况下我们有25 url在队列中等待,所以你的显示可能会略有不同
4,如果爬取步骤1仍在运行,现在让它发出stop动作请求停止
Action Request:
$ python kafka_monitor.py feed '{"action":"stop", "appid":"testapp", "uuid":"someuuid", "crawlid":"abc1234", "spiderid":"link"}'- 1
以下情况会发生这个动作请求之后
- kafka 组件将收到请求并存放在redis中
- redis 组件将执行
stop请求,并清除当前请求的spiderid,appid,crawlid。 - redis 组件将
crawlid加入黑名单,所以没有更多的挂起的请求可以从蜘蛛或者应用程序生成 - redis 组件将清洗总结果发送回kafka
- kafka dump 将收到类似下面的结果:
$ {u'total_purged': 90, u'server_time': 1450817758, u'crawlid': u'abc1234', u'spiderid': u'link', u'appid': u'testapp', u'action': u'stop'}- 1
在这种情况下,我们有90个url从队列中删除。这些挂起的请求现在完全从系统中删除,蜘蛛会回到被闲置。
希望你现在有一个工作Scrapy集群,允许您提交工作队列,接收信息抓取,并停止爬行,如果它变得失控。请继续更深入地阅读每个组件的文档。
组件的作用
kafka
kafka组件作为入口点进入爬虫架构。它验证API请求之后,可以确保任何时候的数据是正确的格式。kafka 组件的设计源于需要定义一个格式被允许创建爬虫抓取从任何应用程序架构。如果应用程序可以读取和写入到卡夫卡集群就可以写信息到一个特定的kafka 主题创建爬行。
很快那些相同的应用程序想要对他们的爬虫进行信息检索的能力,停止他们,或者得到他们的集群信息。我们决定创建一个动态请求的接口可以支持所有的需求,但利用相同的基础代码。这个基础代码现在被称为kafka 组件,利用各种插件来扩展或改变kafka 组件的功能。 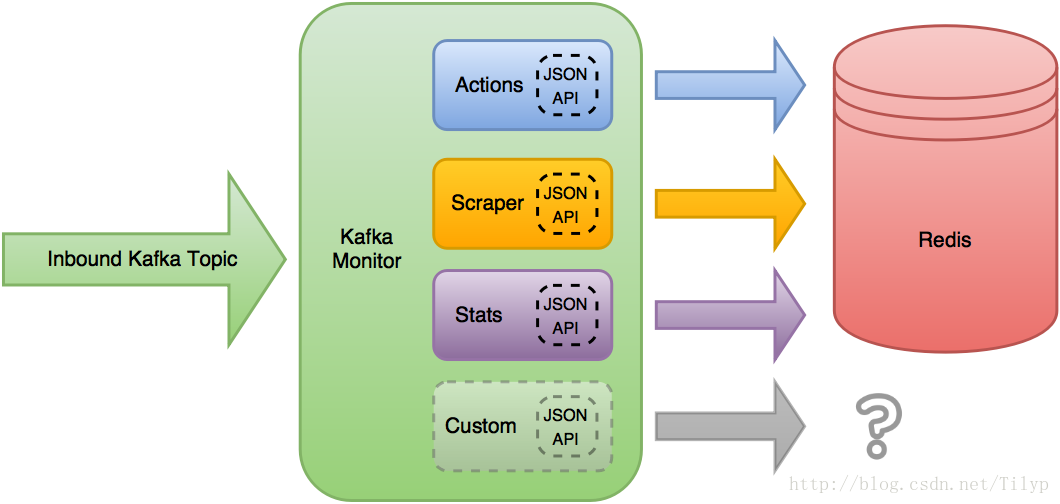
kafka 组件读取需要入站kafka 的话题,并应用当前加载的JSON api插件来接收消息。第一个插件有一个有效的JSON Schema接收JSON对象被允许做自己的处理和操纵的对象,
Scrapy集群的用例中,默认插件将他们的请求写入redis 的key中,但是功能并没有就此止步。kafka 组件的设置可以改变哪些插件加载,或添加新插件扩展功能。这些模块允许kafka 组件核心占用空间小但允许扩展或运行不同的插件了。
从我们自己的内部调试,确保其他应用程序正常工作,一个叫 kafka dump 的实用应用程序也是为了能够创建和监控kafka 通过消息交互。这是一个小型转储工具没有外部依赖,允许用户通过kafka 话题去了解集群。
kafka_monitor.py
有两种运行模式run和feed: Run:
这是连续运行模式。将接受传入kafka 的消息从一个话题中,验证消息为JSON对所有可能的JSON API,然后允许有效的API插件来处理对象(运行模式是主要的流程你应该运行) 。
$ python kafka_monitor.py run- 1
Feed:
以JSON对象提交你想要的kafka的话题。这需要提交一个有效的JSON对象并将它插入所需的kafka的话题,然后被上面的run命令运行。
$ python kafka_monitor.py feed '{"url": "http://istresearch.com", "appid":"testapp", "crawlid":"ABC123"}'- 1
feed非常缓慢在生产中不应使用。相反,你应该根据自己的需求编写可以不断运行的应用程序给kafka 所需的API请求。
kafkadump.py
基本kafka主题工具用于检查消息流在你的卡夫卡集群。 Dump:
$ python kafkadump.py dump -t demo.crawled_firehose- 1
这个实用程序默认消耗结束后获取所需的kafka 的话题,并且对离线测试很有用通过当前的消息流。 List:
列出所有集群内的话题
$ python kafkadump.py list- 1
kafka 组件的API 就不多说了,自己到官网去看,API地址 。这里讲一下kafka 的几个话题
- 入站话题:
demo.incoming,此话题提交正确格式化的集群请求。 - 出站结果卡夫卡的话题:
1,demo.crawled_firehouse,为系统输出结果的流水话题。任何单一的网页抓取的Scrapy集群保证走出这个管子。
2,demo.outbound_firehose,输出所有特殊的爬虫启动,停止,到期,统计要求的流水话题。此主题将具有从群集请求所有非爬行数据的能力。
3,demo.crawled_<appid>,为获取特殊应用的爬取结果而创建的特殊主题,任何应用程序都可以用appid创建监听话题来监听自己特定的爬取结果,这些主题是爬行的流水话题数据的一个子集并且只包含appid提交的结果。
4,demo.outbound_<appid>,一个特别的话题为了读取特殊应用程序的行动请求数据
后两种方式是禁用的,因为他们在kafka中产生了重复数据,如果想要启用它,只需要覆盖redis 组件的配置文件。
如有疑问请加qq群:526855734















 1081
1081

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









